
Pre HA(Hiring Assesment) 시험에 관한 TIL 기록
1. _.shuffle
_.shuffle = function (arr) {
let arrCloned = arr.slice();
for (let fromIdx = 0; fromIdx < arr.length; fromIdx++) {
const toIdx = Math.floor(Math.random() + arr.length);
let temp = arrCloned[fromIdx];
arrCloned[fromIdx] = arrCloned[toIdx];
arrCloned[toIdx] = temp;
}
return arrCloned;
};
위의 코드를 설명하기 이전에 먼저 자바스크립트에서 언더바는 왜쓰는지 알아보았다.
코딩컨벤션(스타일 가이드)
함수명 앞에 언더바를 붙여주는 것은 일종의 코딩 컨벤션이라고 한다.
코딩 컨벤션이란 프로그래밍 언어별로 권장하는 코딩규칙(스타일)이라고 한다.
이해하기 쉬운 코드를 작성하기 위한 가이드 정도로 참고해서 활용할 수 있다고 한다.
즉, 나 외에 다른 사람들도 내가 작성한 코드를 보고 쉽고 빠르게 이해할 수 있도록 하는 작성표준이라고 생각하면 된다.🔖shuffle(혼합)🏷
웹사이트를 테스트 서버에 구축 후 테스트를 수행하기 위해서 사용되는 Dummy 값들에 적용할 수 있으며, 테스트 데이터에 적용하면 항상 다른 값들을 반환하기 때문에 테스트(QA)를 수행하는데 있어 더 많은 case를 수행할 수 있다고 한다.// 이 내용은 좀더 알아보아야 겠지만, shuffle은 우리말의 의미대로 데이터 섞기 정도로만 현재로서는 이해한다.
위의 코드를 읽어보면,
_.shuffle = function (arr) { // 매개변수 arr를 전달인자로 받아
let arrCloned = arr.slice(); // slice메서드를 이용해 기존배열이 변하지않게 적용하면서 새로운배열 cloned(복제)하는 arrCloned변수에 arr.slice()를 할당
for (let fromIdx = 0; fromIdx < arr.length; fromIdx++) { // 배열의 인덱스 첫번째요소부터 배열의 길이까지 반복으로 돌면서
const toIdx = Math.floor(Math.random() * arr.length); // Math.floor로 배열의 주어진 숫자와 같거나 작은 정수 중에서 가장 큰 수를 찾으며, (Math.random() *arr.length)을 할당하여 값을 원하는 범위로 변형할 수 있도록 toIdx를 선언해서
**let temp = arrCloned[fromIdx]**; // 새로운 변수 temp를 선언하여 arrCloned의 fromIdx번째 요소를 할당
arrCloned[fromIdx] = arrCloned[toIdx]; // fromIdx번째 요소 자리에 toIdx번째 요소의 값을 할당
arrCloned[toIdx] = temp; // toIdx번째 요소 자리에 temp의 값을 할당 (이전 **fromIdx번째 요소의 값**)
}
return arrCloned; // 요소를 섞은 새로운 배열을 리턴
};shuffle 사용의 자바스크립트 구현은 아래와 같다.
function shuffle(array) {
var currentIndex = array.length, temporaryValue, randomIndex;
// While there remain elements to shuffle...
while (0 !== currentIndex) {
// Pick a remaining element...
randomIndex = Math.floor(Math.random() * currentIndex);
currentIndex -= 1;
// And swap it with the current element.
temporaryValue = array[currentIndex];
array[currentIndex] = array[randomIndex];
array[randomIndex] = temporaryValue;
}
return array;
}
// Used like so
var arr = [2, 11, 37, 42];
shuffle(arr);
console.log(arr);
slice()는 원본을 대체하지 않고, 원본 배열에서 요소의 얕은 복사본을 반환한다.
원본 배열의 요소는 다음과 같이 반환 된 배열에 복사된다:
- 객체 참조(및 실제 객체가 아님)의 경우, slice()는 객체 참조를 새 배열로 복사한다. 원본 배열과 새 배열은 모두 동일한 객체를 참조한다. 참조 된 객체가 변경되면 변경 내용은 새 배열과 원래 배열 모두에서 볼 수 있다.
- String 및 Number 객체가 아닌 문자열과 숫자의 경우 slice()는 문자열과 숫자를 새 배열에 복사한다.
한 배열에서 문자열이나 숫자를 변경해도 다른 배열에는 영향을 주지 않는다. 새 요소를 두 배열 중 하나에 추가해도 다른 배열은 영향을 받지 않는다.
slice 사용하기
다음 예제에서 slice()는 myCar에서 newCar라는 새 배열을 만든다. 두 가지 모두 myHonda 객체에 대한 참조를 포함한다. myHonda의 색상이 자주색으로 변경되면 두 배열 모두 변경 사항을 반영한다.
// Using slice, create newCar from myCar.
let myHonda = { color: 'red', wheels: 4, engine: { cylinders: 4, size: 2.2 } }
let myCar = [myHonda, 2, 'cherry condition', 'purchased 1997']
let newCar = myCar.slice(0, 2)
// Display the values of myCar, newCar, and the color of myHonda
// referenced from both arrays.
console.log('myCar = ' + JSON.stringify(myCar))
console.log('newCar = ' + JSON.stringify(newCar))
console.log('myCar[0].color = ' + myCar[0].color)
console.log('newCar[0].color = ' + newCar[0].color)
// Change the color of myHonda.
myHonda.color = 'purple'
console.log('The new color of my Honda is ' + myHonda.color)
// Display the color of myHonda referenced from both arrays.
console.log('myCar[0].color = ' + myCar[0].color)
console.log('newCar[0].color = ' + newCar[0].color)
Math.random() 사용
Math.random() 함수는 0 이상 1 미만의 구간에서 근사적으로 균일한(approximately uniform) 부동소숫점 유사난수를 반환하며, 이 값은 사용자가 원하는 범위로 변형할 수 있다. 난수 생성 알고리즘에 사용되는 초기값은 구현체가 선택하며, 사용자가 선택하거나 초기화할 수 없다.
**Math.random()은 암호학적으로 안전한 난수를 제공하지 않으므로,
보안과 관련된 어떤 것에도 이 함수를 사용해서는 안 된다.
그 대신 Web Crypto API window.crypto.getRandomValues() 메소드를 이용하여야 한다.**2. reduce
위에서 셔플에 대해 알아보았는데, 셔플의 동작을 잘 이해해야지만 mapreduce를 작동시킬때 최적의 성능으로 가동시킬 수 있다고 한다.
셔플은 map에서 reduce로 데이터를 전달하는 과정을 이야기 한다.
동작에 대략적인 그림은 아래와 같다.
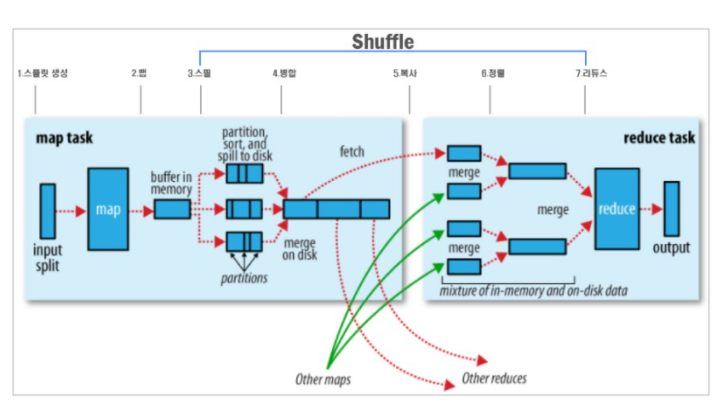
mapreduce는 입력데이터를 입력 스플릿으로 나누어서 map에게 할당하여 map태스크를 실행한다.
map은 구현된 내용대로 입력 데이터를 조작하여 출력값을 자신의 메모리 버퍼에 저장한다. 사전에 메모리 버퍼에 저장하는 이유는 바로 정렬이나 파티셔닝을 용이하게 할 수 있기 때문이라고 한다.//이 내용도 앞으로 좀더 알아보야 겠다.
filter(), map(), reduce() 사용하기
const filterMaped = arr.filter(x => x%2 !== 0).map(x => x*2);
console.log(filterMaped) //[2, 6, 10]위의 화살표 함수를 풀어서 쓰면,
const filterMaped = arr.filter(x => {
if (x%2 !== 0) {// 만약 x를 2로 나누었을때 나머지가 0과 같지않다면,즉 홀수라면
return true; // true를 반환
});
arr.map(x =>
(x * 2)//x값이 1이면 2, 3이면 6, 5이면 10
);
console.log(filterMaped);//[2. 6. 10] 결과값 반환
위의 코드를 reduce를 한 번만 사용한 코드를 변경하면,
let arr =[];// 결과값 반환을 위한 빈배열 할당
let arr.reducer(x, val) {//리듀서 함수로 위의 전달인자 x값을 콜백으로 받고
val = 2;
if (x%2 !==0) { //x가 홀수라면
x.push(arr.length) // 결과값을 모두 나타내기 위한 위한 arr의 길이를 push하고
return (x*val);//x * val값 2를 곱하여
}
return arr; // 결과값을 배열로 반환
}reduce()
reduce() 메서드는 배열의 각 요소에 대해 주어진 리듀서(reducer) 함수를 실행하고, 하나의 결과값을 반환한다.
리듀서 함수는 네 개의 인자를 가진다.
- 누적값 accumulator (acc)
- 현재값 (cur)
- 인덱스 (idx)
- 원본 배열 (src)
리듀서 함수의 반환 값은 누산값에 할당되고, 누적값은 순회 중 유지되므로 결국 최종 결과는 하나의 값이 된다.
reduce()작동방식
(예시)
[0, 1, 2, 3, 4].reduce(function(accumulator, currentValue, currentIndex, array) {
return accumulator + currentValue;
});콜백은 4번 호출되고,(1번호출-1, 2번호출-3, 3번호출-6, 4번호출-10)
reduce()가 반환하는 값으로는 마지막 콜백 호출의 반환값(10)을 사용한다.
💡reduce()메서드 활용 장점💡
맵리듀스(MapReduce)는 구글에서 정보 검색을 위한 데이터 가공(색인어 추출, 정렬 및 역 인덱스 생성)을 목적으로 개발된 분산 환경에서의 병렬 데이터 처리 기법이자 프로그래밍 모델이다.
맵리듀스는 비공유 구조(shared-nothing)로 연결된 여러 노드 PC들을 가지고 대량의 병렬처리 방식(MPP, Massively Parallel Processing)으로 대용량 데이터를 처리할 수 있는 방법을 제공한다. 맵리듀스는 LISP 프로그래밍 언어에서 맵(map)과 리듀스(reduce)라는 함수의 개념을 차용하여 시스템의 분산구조를 감추면서 범용 프로그래밍 언어를 이용해 병렬 프로그래밍을 가능하게 한다.
아래 filterMap함수는 맵리듀스(MapReduce)를 쉽게 이해할 수 있는 예시이다.
const filterMap = function(acc, val){
if (val % 2 !== 0){ // val이 홀수인 경우
acc.push(val * 2) // *2 하여 acc에 push
}
return acc; // 결과를 다음 요소에 전달
}
const filterMaped2 = arr.reduce(filterMap, [])
console.log(filterMaped2) // [2, 6, 10]
즉, 맵(map)과 리듀스(reduce)라는 두 개의 메소드로 구성되어
있으며 맵(map) 메서드는 키-값을 읽어 필터링하거나
다른 값으로 변환하는 작업을 수행 한다.
리듀스(reduce)는 맵(map) 함수를 통해 출력된 결과 값을
새로운 키 기준으로 그룹화(grouping) 한 후
집계연산(Aggregation)을 수행한 결과를 출력한다. 