다양한 기업들이 시행하는 코딩 테스트는 문제의 정확성뿐 아니라 효율성을 묻는 문제들도 많다.
답은 맞췄어도 시간이 너무 오래 걸리는 코드의 경우에는 오답 처리가 되므로 평소에도 코드를 효율적으로 짜는 방안을 생각해야 하는데 이번에 맞닥뜨린 문제는 한 번 더 깊게 생각하는 계기가 되어 정리하게 되었다.
프로그래머스 - 주식가격
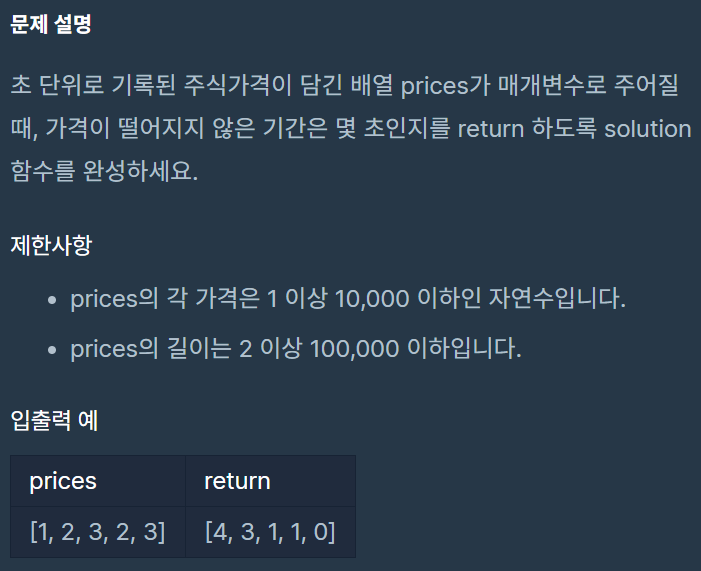
문제를 보자마자 바로 생각난 풀이는 이중 for 문이었다.
prices의 각 원소마다 후발 원소들을 하나씩 체크하면서 가격이 떨어지는 순간의 초를 answer 리스트에 추가하는 형태.
(1) 처음 풀이는 다음과 같다.
# 편의를 위해 함수형으로 구현하지 않고 그냥 구현함
prices = [1, 2, 3, 2, 3]
answer = []
for i in range(len(prices)):
cnt = -1
for j in range(len(prices)):
cnt += 1
if prices[j] < prices[0]:
break
answer.append(cnt)
prices.pop(0)가격이 떨어질 때까지의 시간을 측정하기 위해 cnt라는 변수를 만들고 자기 자신부터 0초에서 시작하도록 -1로 초깃값을 주었다. 그 뒤 시간 측정이 끝난 원소에 대해서는 pop 연산을 통해 리스트에서 아예 제거했다.
자바로 해당 문제를 풀었을 때는 동일한 방식으로 정확성, 효율성을 모두 통과했기에 파이썬도 같은 방식으로 풀면 통과할 줄 알았으나 효율성 부분에서 0점을 받았다.
처음에는 틀린 이유가 이중 for 문이라 시간을 많이 잡아먹는다고 생각했다.
그래서 어떻게든 for 문의 형태에서 벗어나려 했지만 아무리 생각해도 '얘는 이중 for 문이 답인데?'에 막혔다가 그 형태는 유지하되 내부만 바꿔보자 하는 생각을 하게 되었다.
(2) 그렇게 생각을 통해 나온 코드는 다음과 같다.
prices = [1, 2, 3, 2, 3]
answer = [0]*len(prices)
for i in range(len(prices)):
for j in range(i+1, len(prices)):
if prices[i] > prices[j]:
answer[i] = j-i
break
else:
answer[i] = j-i별도의 변수를 주지 않고 이중 for 문의 범위를 줄여가면서 가격이 떨어지는 순간 두 인덱스 간의 차이를 그대로 answer 리스트에 할당했다. 이 풀이는 정확성, 효율성 모두 통과를 하였다.
아니 그럼 이중 for 문이 문제가 아니었네? 근데 두 코드가 그렇게 시간차가 많이 나나?
얼마나 시간이 걸리는지 확인하기 위해 각 코드를 100번씩 실행해 평균치를 측정해보았다.
(1) 시간 측정 결과 : 1.990000009755022e-07
(2) 시간 측정 결과 : 7.899999673099955e-08
거의 2.5배에 달하는 시간차가 나는 것을 확인할 수 있었다.
그럼 대체 어디서 시간을 많이 잡아먹는 것인지 코드를 보던 중 (1)의 pop 연산이 눈에 띄었다.
해당 연산이 얼마나 시간을 소모하는지 찾다가 다음 문서를 발견했다.
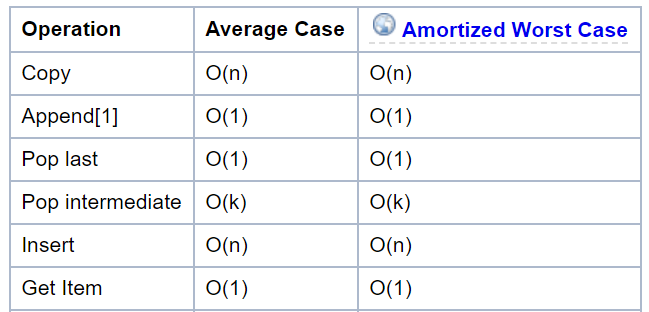
해답이 여기에 있었다!
(1)의 경우 매번 pop(0)을 수행하기 위해 리스트 전체를 수행해서 시간이 오래 걸리는 것이었다.
(2)가 제일 효율적인 풀이는 절대 아니다. (1)에서도 pop 부분만 수정하면 테스트를 통과한다.
prices = [1, 2, 3, 2, 3]
answer = []
for i in range(len(prices)):
cnt = -1
for j in range(i, len(prices)):
cnt += 1
if prices[j] < prices[i]:
break
answer.append(cnt)물론 더 빠른 코드들도 충분히 존재한다.
하지만 이중 for 문이 무조건 느린 게 아닌 연산 한 줄에 의해서도 코드의 소요 시간이 크게 차이 난다는 것을 확인하게 된 계기가 되었다.
