JPA(Java Persistence API)
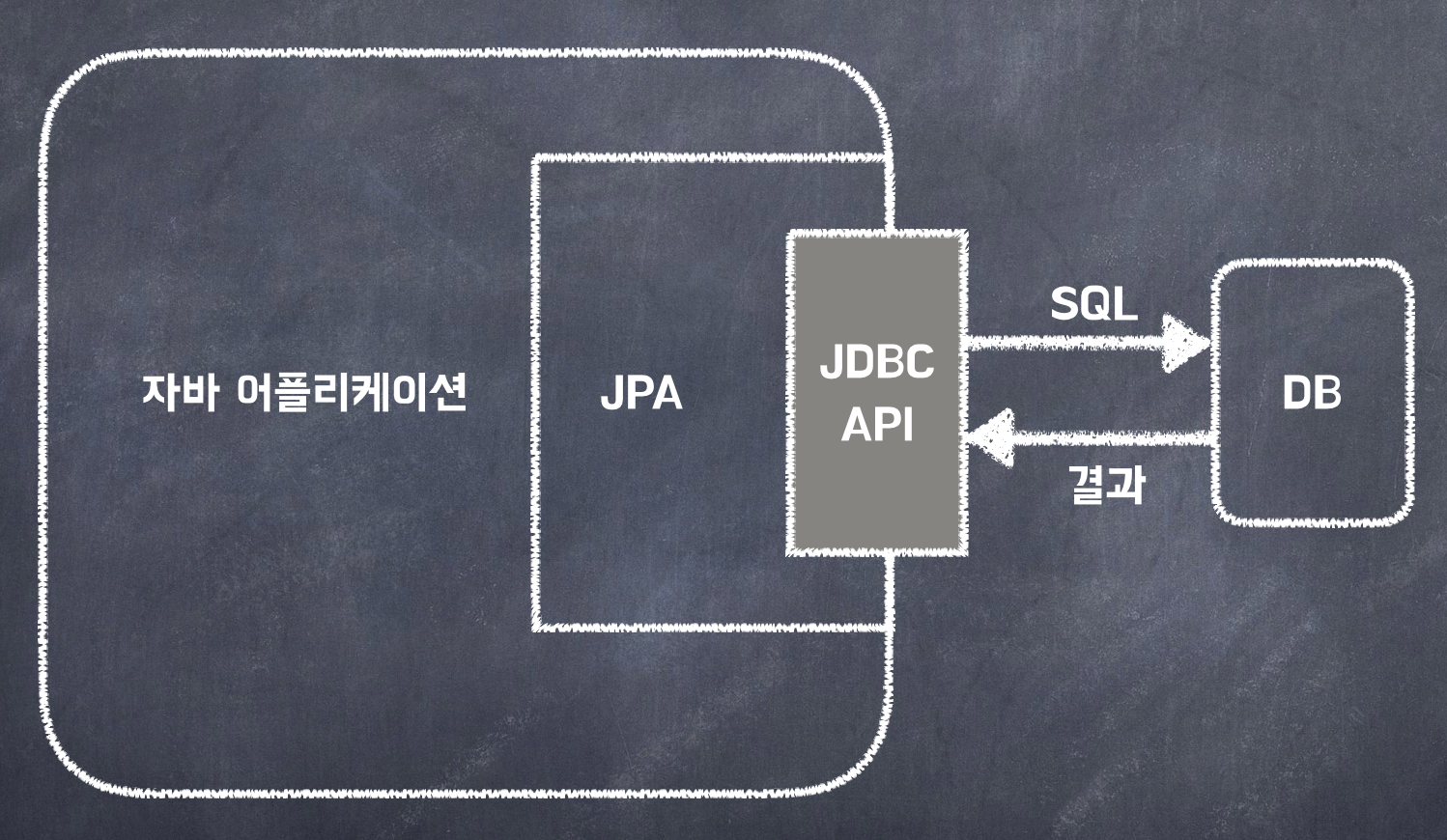
ORM(Object Relational Mapping)
객체와 테이블을 매핑해서 패러다임의 불일치를 개발자 대신 해결해준다.
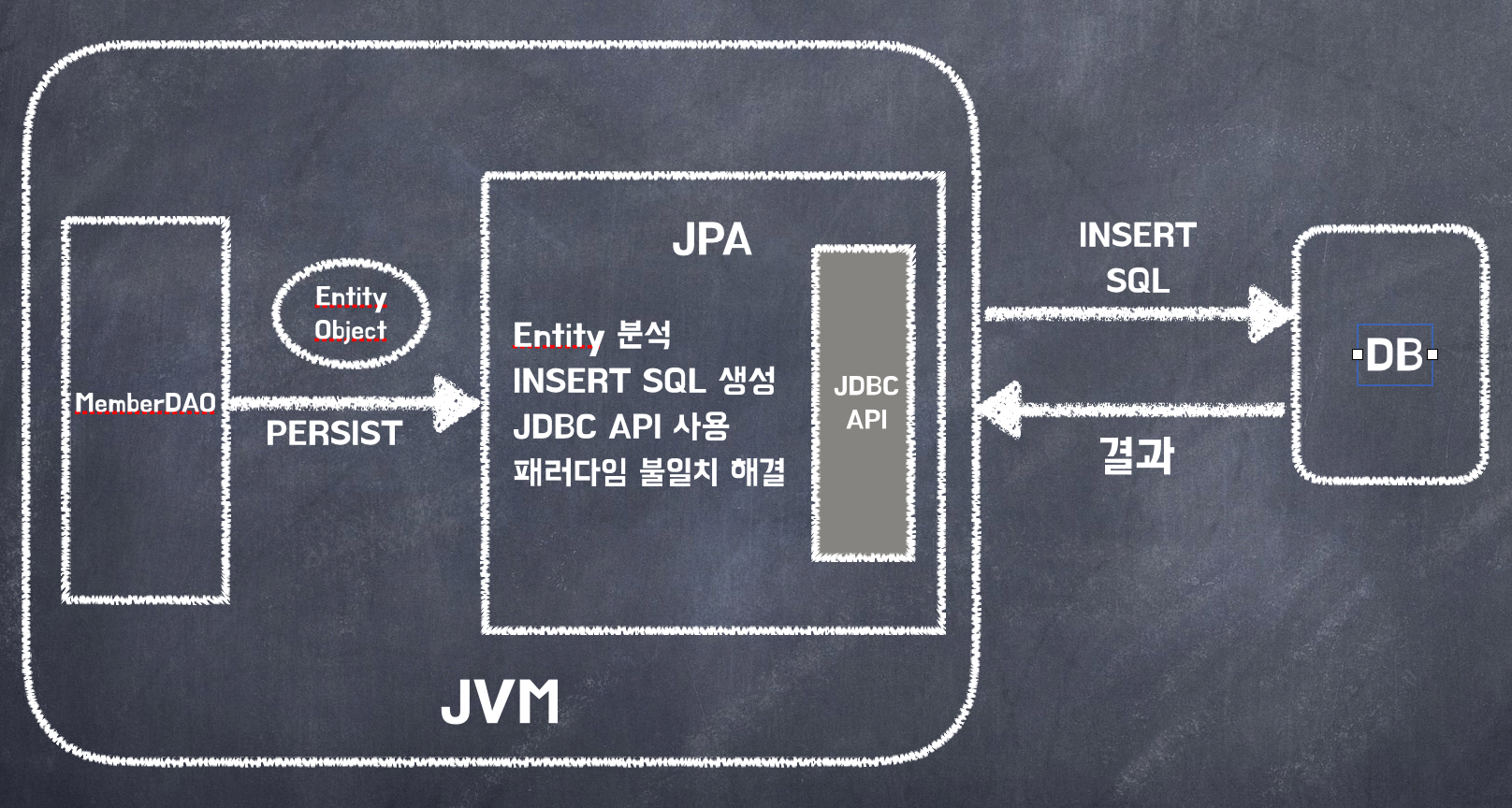
객체를 저장하는 코드
jpa.persist(member);
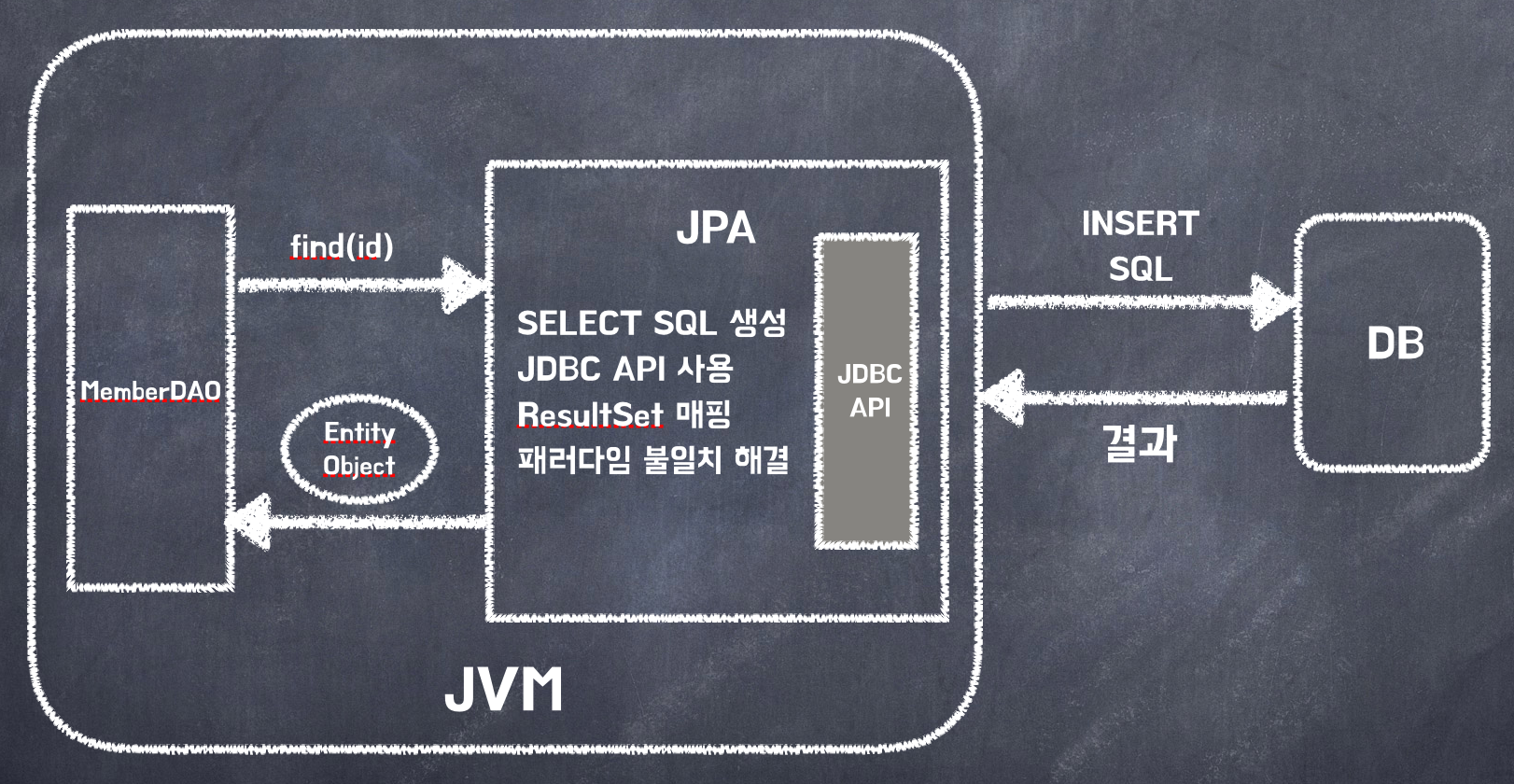
객체를 조회하는 코드
Member member = jpa.find(memberId);
JPA 영속성 컨텍스트의 이점
영속성 컨텍스트는 엔티티를 영구 저장하는 환경을 의미합니다.
영속성 컨텍스트를 쓰는 이유
-
1차 캐시: 조회가 가느아혐 1차 캐시에 없으면 DB에서 조회하여 1차 캐시에 올려 놓습니다.
-
동일성 보장: 동일성 비교가 가능합니다.(==)
-
쓰기 지연: 트랜잭션을 지원하는 쓰기 지연이 가능하며 트랜잭션 커밋하기 전까지 SQL을 바로 보내지않고 모아서 보낼 수 있습니다.
-
변경감지(Dirty checking): 스냅샷을 1차캐시에 들어온 데이터를 찍습니다. commit되는 시점에 Entity와 스냅샷과 비교하여 update SQL을 생성합니다.
-
지연로딩: 엔티티에서 해당 엔티티를 불러올 때 그 때 SQL을 날려 해당 데이터를 가져옵니다.
JPA의 전파 단계
JPA Propagation은 트랜잭션 동작 도중 다른 트랜잭션을 호출(실행)하는 상황에 선택할 수 있는 옵션입니다.
@Transactiondml propagation 속성을 통해 피호출 트랜잭션의 입장에서는 호출한 쪽의 트랜잭션을 그대로 사용할 수도 있고, 새롭게 트랜잭션을 생성할 수도 있습니다.
REQUIRED(기본값) : 부모 트랜잭션 내에서 실행하며 부모 트랜잭션이 없을 경우 새로운 트랜잭션을 생성합니다.
이 외에도 종류가 REQUIRES_NEW,SUPPORTS,MANDATORY,NOT_SUPPORT,NEVER,NESTED가 있음
N+1
N + 1 쿼리 문제는 즉시 로딩과 지연 로딩 전략 각각의 상황에서 발생가능합니다. 하위 엔티티들이 존재하는 경우 한 쿼리에서 모두 가져오는 것이 아닌,필요한 곳에서 각각 쿼리가 발생하는 경우를 이릅니다.
즉시 로딩에서 발생하는 이유는 JPQL을 사용하는 경우 전체 조회를 했을 때, 영속성 컨텍스트가 아닌 데이터베이스에서 직접 데이터를 조회한 다음 즉시로딩 전략이 동작하기 때문입니다.
지연로딩에서 발생하는 이유는 지연로딩 전략을 사용한 하위 엔티티를 로드할 때 JPA에서 프록시 엔티티를 unproxy할 때 해당 엔티티를 조회하기 위한 추가적인 쿼리가 실행되어 발생합니다.
해결방법으론느 Fetch Join이라고 불리는 JPQL의 join fetch를 사용하는 방법이 있으며, 또 다른 방법으로는 @EntityGraph 를 사용하는 방법, @Fetch(FetchMode.SUBSELECT)를 사용하는 방법, @BatchSize를 사용해 조절하거나 전역적인 batch-size를 설정하는 방법이 있습니다.
