Attention Mechanism
RNN 기반 seq2seq 모델에서의 문제점
- 하나의 고정된 크기의 벡터에 모든 정보를 압축하는 과정에서 손실 발생
- Vanishing Gradient 발생
=> 이러한 문제는 입력 시퀀스가 클수록 성능을 저하시킨다.
seq2seq의 단점을 보완하고자 적용된 것이 attention mechanism이다.
Attention Mechanism
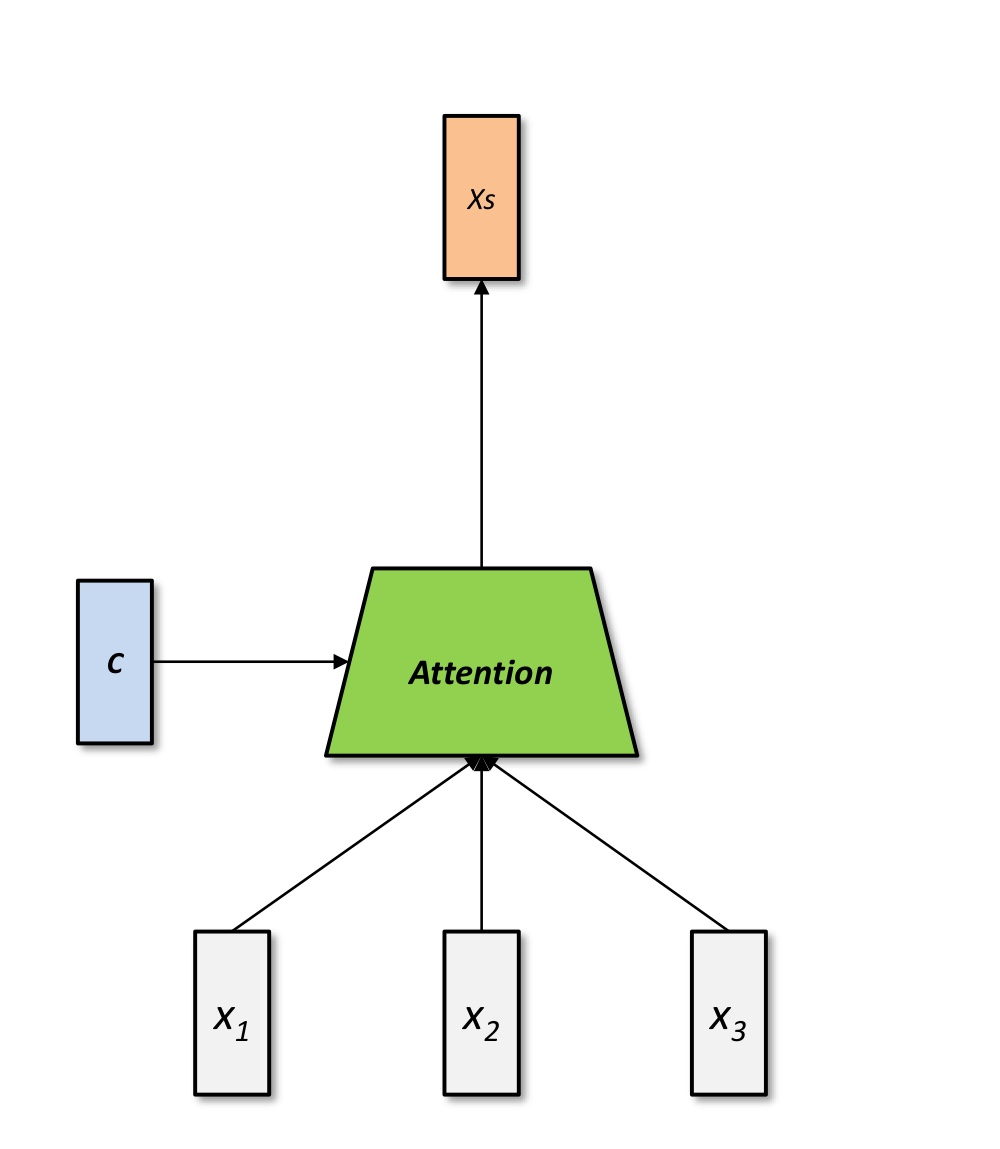
Attention
- attention은 decoder의 매 시점마다 encoder의 전체 입력을 다시 참조
- 다음 단어를 예측할 때 가장 연관있는 입력 문장의 특정 부분을 더 집중적으로 참조
query vector를 blend vector들에 적용시키는 여러 방법들이 있다.
-
Bahdanau method
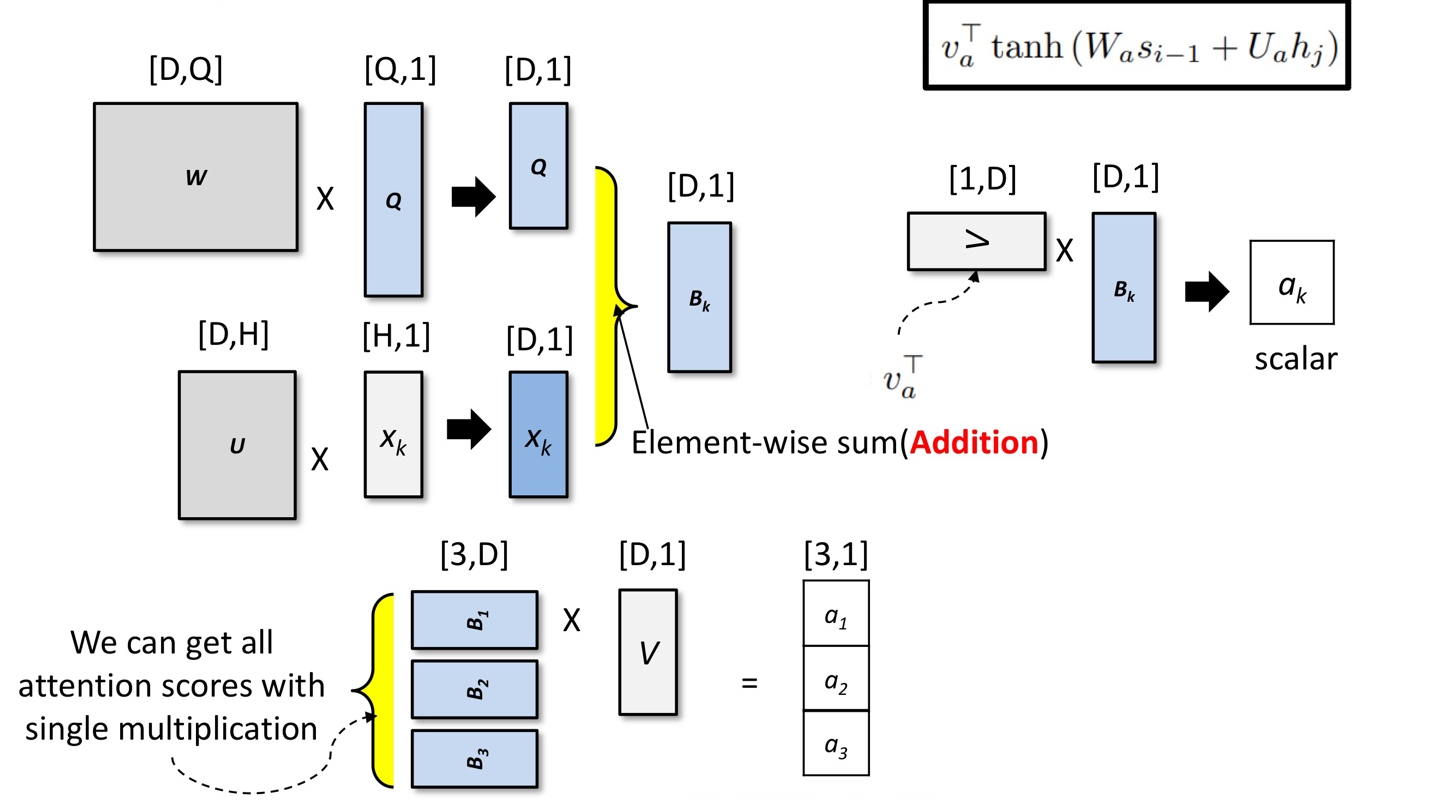
Query의 차원과 Hidden state의 차원이 달라도 가능
정보가 더해지는 경우(additive attention) -
Dot method
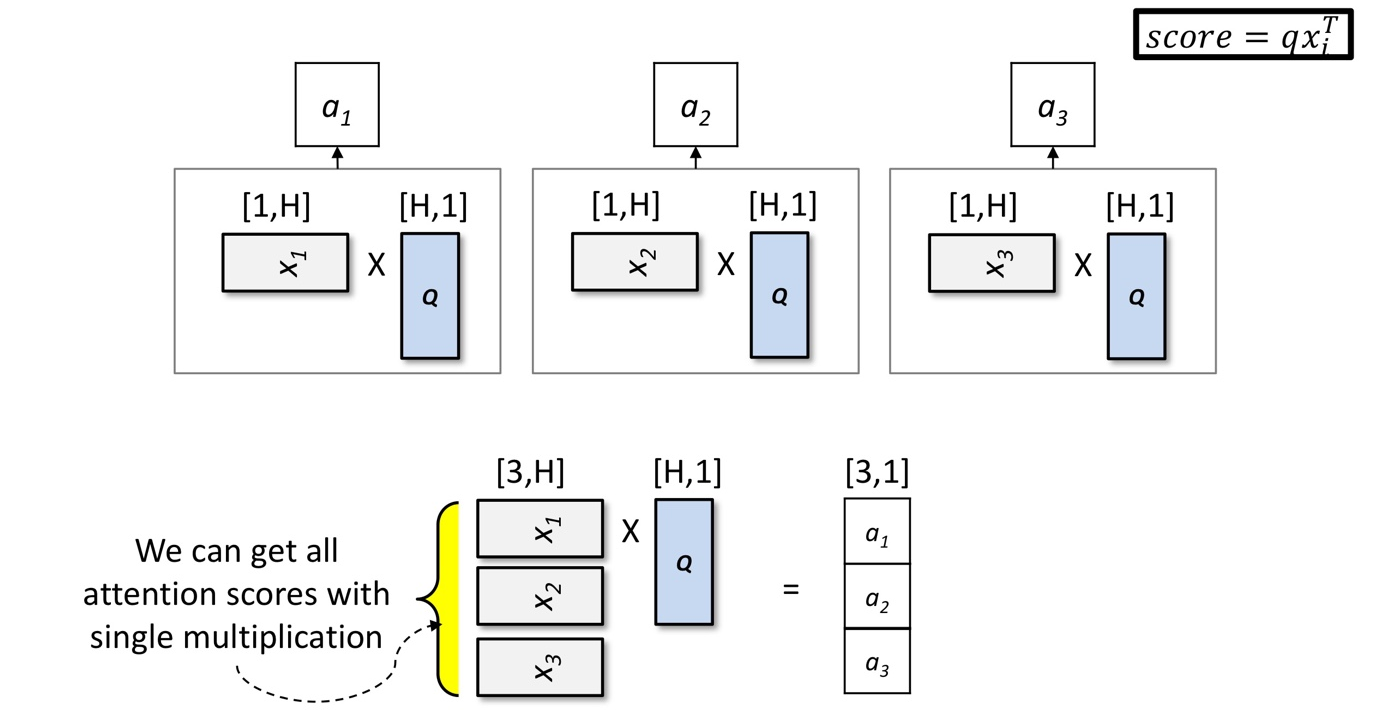
정보의 내적 이용(dot product 수행) -
General method
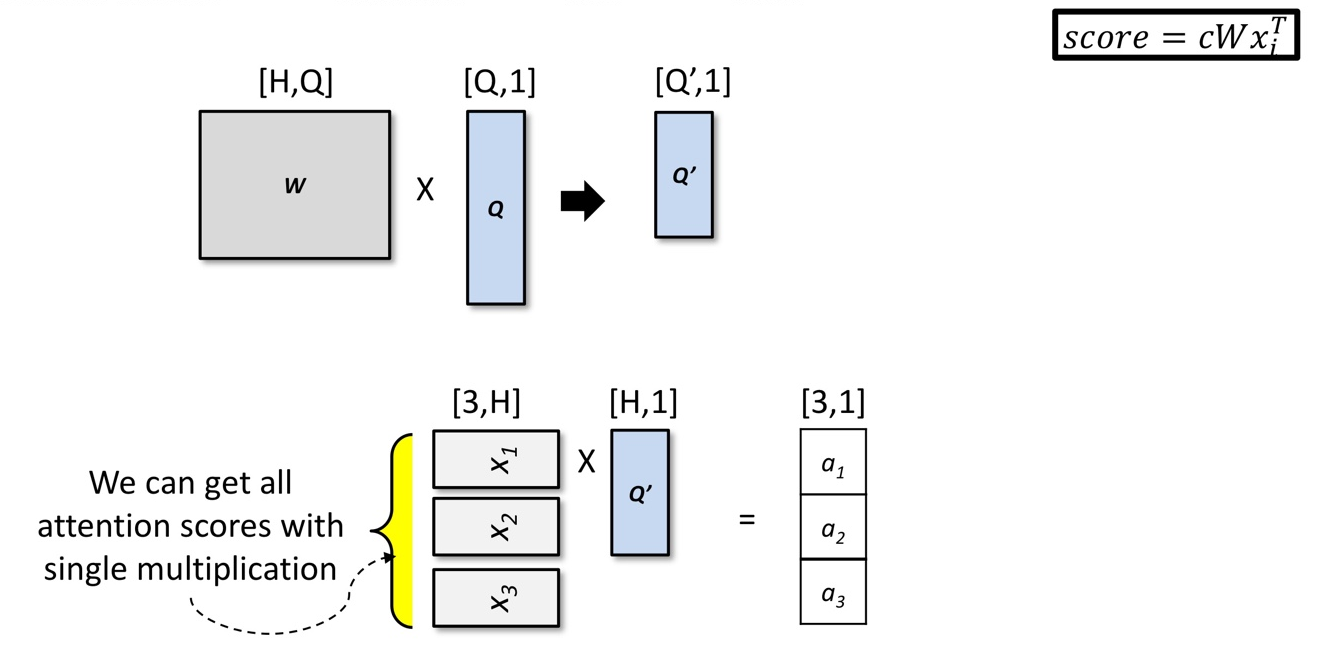
Query의 차원과 Hidden state의 차원이 달라도 가능
Query를 입력 항목과 동일한 모양으로 변환
정보의 내적 이용(dot product 수행)
Attention Score
-
decoder의 특정 예측 시점에서 decoder의 hidden state가 인코더의 각 모든 hidden state와 얼마나 유사한지를 나타낸 값

-
Bahdanau method를 기반으로 정리
Score 함수는 다음과 같다.
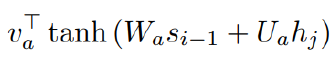
Bahdanau method를 이용하여 reactivity를 계산한 실습 코드
def _calculate_reactivity(self, query_vector, multiple_items):
B, N, H = multiple_items.shape # [B,N,H]
query_vector = query_vector.unsqueeze(1)
projected_q = self.W(query_vector) # projected_q : [B,1,Q] -> [B,1,D]
projected_item = self.U(multiple_items) # projected_item : [B,N,H] -> [B,N,D]
added_pp = projected_q + projected_item # added_pp : [B,1,D] + [B,N,D] -> [B,N,D]
tanh_pp = F.tanh(added_pp) # tanh_pp : [B,N,D]
v_t = self.v.transpose(1,0)
batch_v = v_t.expand(B, self.attention_dim,1) # batch_v : [B,D,1]
reactivity_scores = torch.bmm(tanh_pp, batch_v)
reactivity_scores = reactivity_scores.squeeze(-1)
# reactivity_score : [B,N,D] x [B,D,1] -> [B,N,1] -> squeeze(-1) -> [B,N]
return reactivity_scoresquery_vector에서 unsqueeze(1)로 두번째에 1인 차원을 추가하고 query의 attention dimention인 W를 곱한다. [B,1,Q] -> [B,1,D]
item의 attention dimention인 U를 곱한다. [B,N,H] -> [B,N,D]
project를 한 두 값(projected_q+projected_item)을 더해 added_pp에 저장한다. [B,1,D] + [B,N,D] -> [B,N,D]
더한 값에 tanh 계산을 한 값을 tanh_pp에 저장한다. [B,N,D]
v를 transpose 해준 뒤 expand로 차원을 늘려준다. [B,D,1]
tanh_pp와 batch_v를 곱하여 reactivity_score를 구하고 squeeze(-1)로 1인 차원을 없애 [B,N]으로 만들어준다.
[B,N,D] x [B,D,1] -> [B,N,1] -> squeeze(-1) -> [B,N]
구현코드 github link
https://github.com/KimHyeYeon41/AISoftware/blob/main/%5BAI_03%5DAttention.ipynb
수업자료 이용(이론/실습)
