
1. 컬렉션 프레임웍(collection framework)
- 컬렉션(collection) : 여러 객체(데이터)를 모아 놓은 것
- 프레임웍(framework) : 표준화, 정형화된 체계적인 프로그래밍 방식
- 컬렉션 프레임웍의 핵심 인터페이스 :
listsetmap

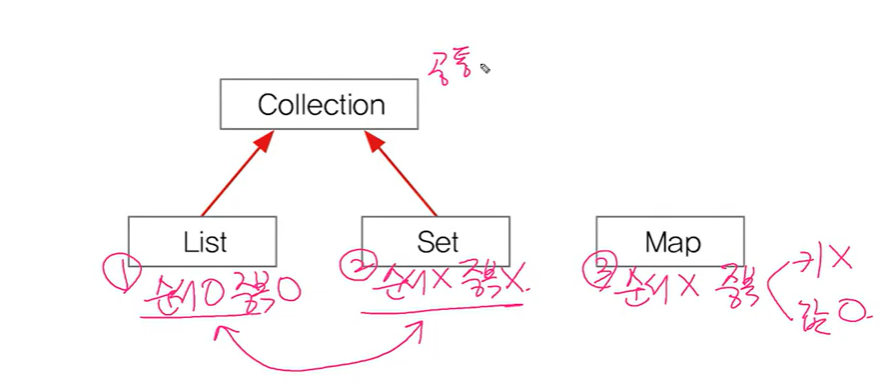
1-1. collection 인터페이스의 메서드
- List와 Set의 공통적 부분을 가진 인터페이스(collection이 조상)
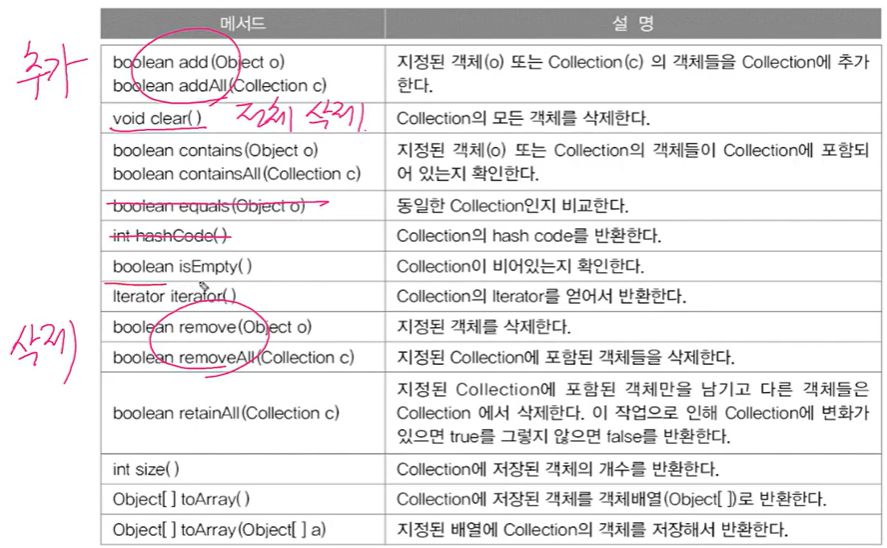
- 메서드
list와 set은 collection이 가진 모든 인터페이스를 갖고 있다. collection의 자손이기 때문.
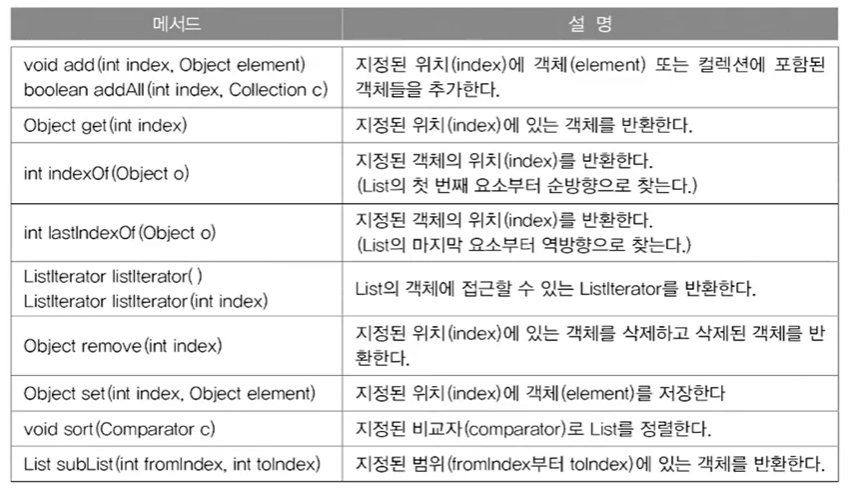
1-2. List 인터페이스
- 순서⭕ 중복⭕
- collection이 가진 모든 메서드를 갖고 있음(자손이니까)
- 배열의 장점?
구조가 간단하고 데이터를 읽는데 걸리는 시간(접근시간)이 짧다 - 배열의 단점?
1) 크기를 변경할 수 없다. 크기를 변경해야 하는 경우 새로운 배열을 생성 후 데이터를 복사해야함
2) 비순차적인 데이터의 추가, 삭제에 시간이 많이 걸린다 (앞에 하나 삭제되면 뒤에께 다 하나씩 옮겨지니까) 그러나 순차적 삭제(끝에 추가)와 삭제(끝부터 삭제)는 빠르다.
1-2-1. ArrayList
- 데이터의 저장공간으로 배열을 사용한다(배열기반)
- List인터페이스를 구현하므로, 저장순서가 유지되고 중복을 허용한다.
- 생성자
ArrayList()
ArrayList(Collection c) //컬렉션을 넣어서
ArrayList(int initialCapacity) //배열의 길이 넣어주기메서드들 - 책에 있음.
public class List {
public static void main(String[] args) {
ArrayList list1 = new ArrayList(10);
//ArrayList에는 객체만 저장가능
//하지만 autoboxing에 의해 기본형도 저장 가능
list1.add(5);
list1.add(new Integer(4));
list1.add(new Integer(2));
list1.add(new Integer(0));
list1.add(new Integer(1));
list1.add(new Integer(3));
//1번째부터 3번째까지 복사해서 새 배열 생성
//이건 새 배열 만들려고 이렇게 생성자 사용한거고, 그냥 읽기 전용할거면 생성자 사용 안해도 됨
ArrayList list2 = new ArrayList(list1.subList(1,4));
//list1과 list2를 정렬한다
Collections.sort(list1);
Collections.sort(list2);
//list1에 list2가 전부 다 잘 들어갔는지
System.out.println(list1.containsAll(list2));
//삽입
list2.add("B");
list2.add("C");
list2.add(3,"A");
}
}🟥add(1), remove(1)은 1을 삭제, 더하는게 아니라 인텍스1을 삭제, 더하는 것
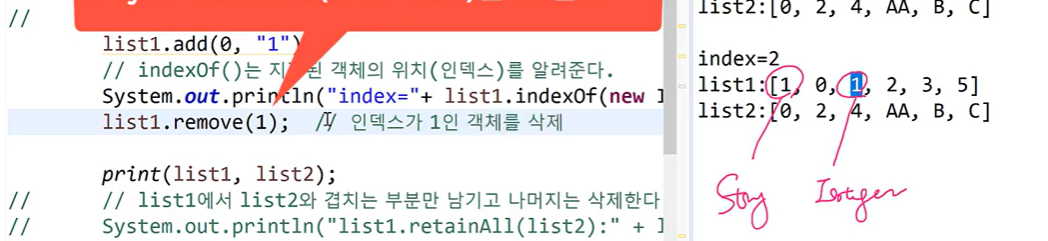
- ArrayList 삭제 과정
- ArrayList에 저장된 세 번쨰 데이터(data[2])를 삭제하는 과정. list.remove(2);를 호출
size가 5에서 4로. (size란? 저장된 객체의 갯수)
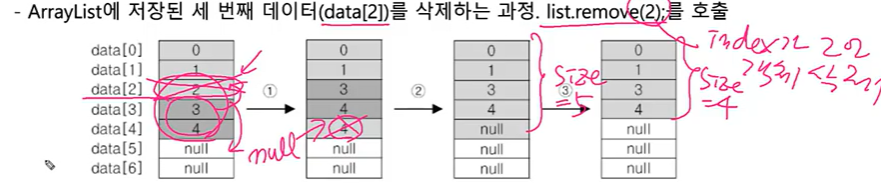
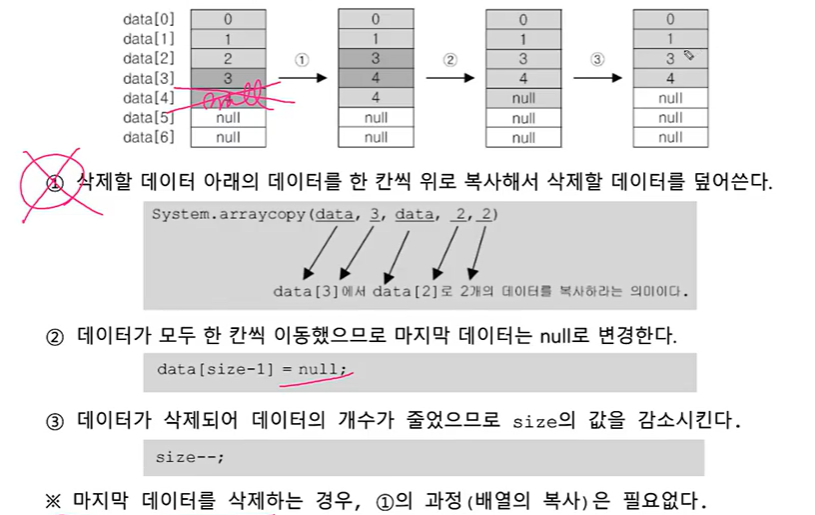
그런데 여기서 마지막 값을 삭제한다면? : 하나씩 앞당길 필요가 없으니까 부담이 덜하다.
- ArryaList에 저장된 첫 번쨰 객체부터
삭제하는 경우(배열 복사 발생)🟨🟨
언젠가 여러분들이 겪을 문제입니다.
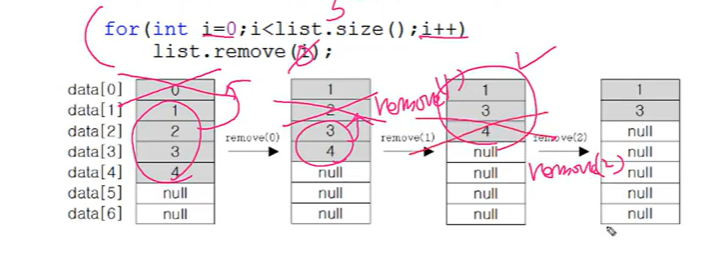
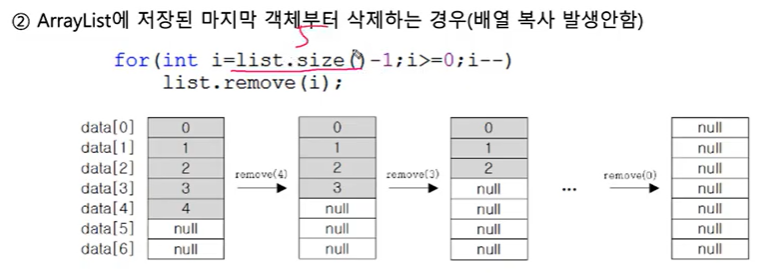
▲이렇게 하면 안됨. 하나 삭제될 때마다 하나씩 앞으로 밀리니까.
▼이렇게 하면 됨. 뒤에꺼부터 삭제하면 됨. 그리고 이게 빨라요.
1-2-2. LinkedList
- 배열의 단점을 보완
- 배열과 달리 linkedlist는 불연속적으로 존재하는 데이터를 연결(link)
(데이터 하나하나가 다 서로 연결되어있다. 밑에 캡처러럼 화살표 방향으로 다음 데이터를 참조하고 있음) - 데이터의 삭제 : 단 한번의 참조 변경만으로 가능
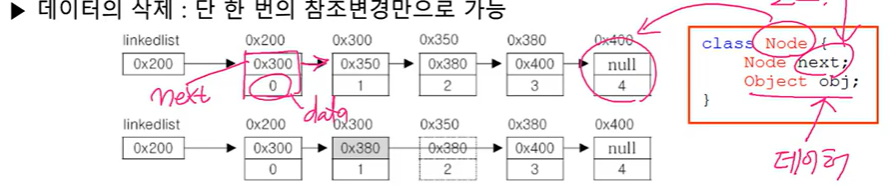
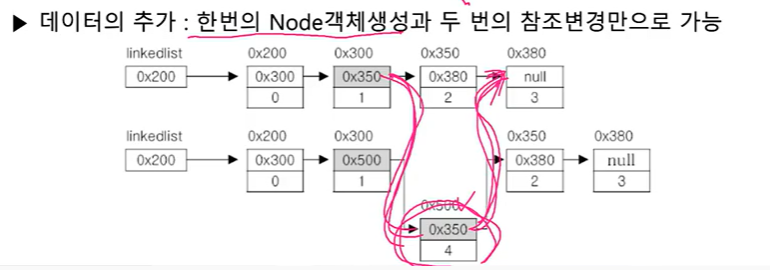
- 데이터의 추가 : 한 번의 Node 객체 생성과 두 번의 참조변경만으로 가능
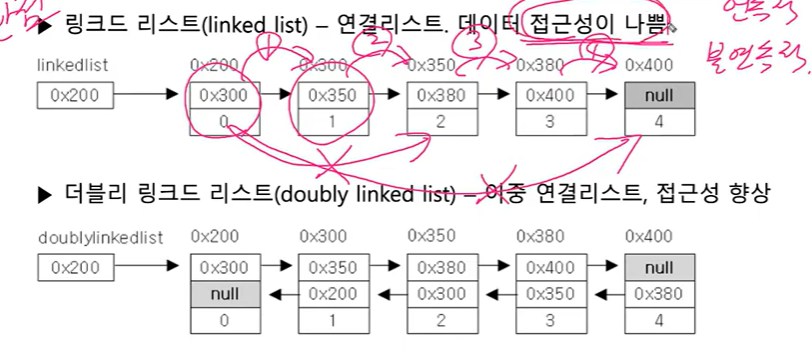
- linkkedlist의 단점 : 연결리스트. 데이터 접근성이 나쁨
(배열처럼 한번에 이동하는게 아니라 (서로 다음 클래스밖에 몰라서) 하나하나 거쳐서 가야함) => 접근성이 나쁘다 => 개선한 것이더블리 링크드 리스트
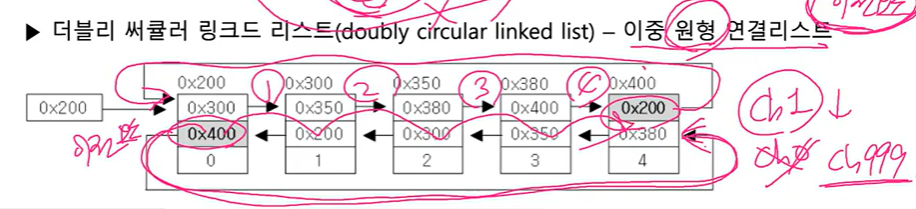
- 더블리 써큘러 링크드 리스트
1-2-3. 스택과 큐(Stack & Queue)
- 스택: LIFO구조. 마지막에 저장된 것을 제일 먼저 꺼내게 된다.
밑이 막힌 상자다. 위로만 넣고 뺄 수 있다.
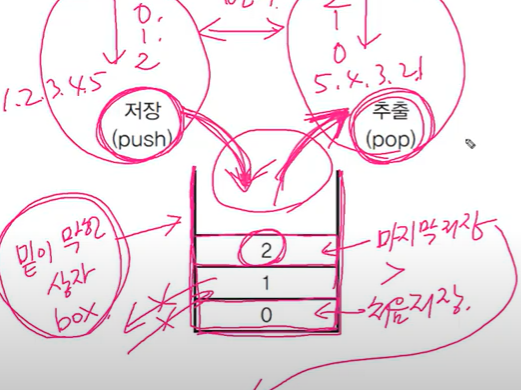
스택:배열이 효율적(링크드 리스트도 가능은 함)- 스택의 메서드
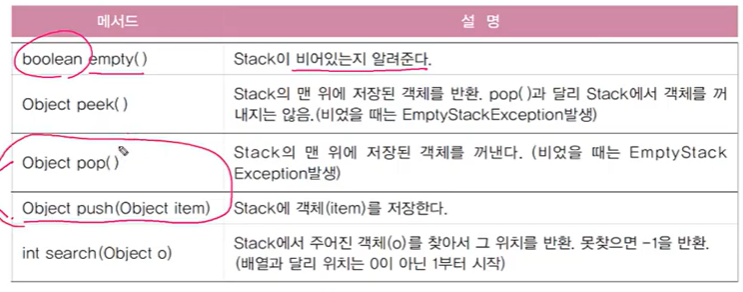
serch는 인덱스 1부터 시작해요. 스택은 인덱스가 1부터 시작하기 때문. - 큐 : FIFO구조. 제일 먼저 저아한 것을 제일 먼저 꺼내게 된다.
양 끝이 뚫린 상자다.
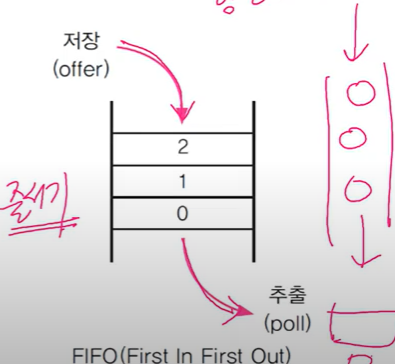
큐:링크드 리스크가 효율적(배열도 가능은 함)- 큐의 메서드

Stack st = new Stack();
Queue 1 = new LinkedList();
st.push("0");
st.push("1");
st.push("2");
q.offer("0");
q.offer("1");
q.offer("2");
while(!st.empty()) {
System.out.println(st.pop()); }
while(!q.isEmpty()) {
System.out.println(q.poll()); }
st는 2,1,0 나오고
q는 0,1,2 나옴.
둘이 나오는 순서가 다름
ex) 괄호 갯수 맞는지 검사 (스택)
public static void main(String[] args) {
Stack st = new Stack();
String expression = "((())))) )";
System.out.println("expression:" + expression);
try {
for (int i=0; i<expression.length(); i++) {
char ch = expression.charAt(i);
if (ch == '(') {
st.push(ch+"");
} else if(ch == ')'){
st.pop();
}
}
if(st.isEmpty()) {
System.out.println("괄호가 일치합니다.");
} else {
System.out.println("괄호가 일치하지 않습니다");
}
} catch(EmptyStackException e) {
System.out.println("괄호가 일치하지 않습니다222");
}
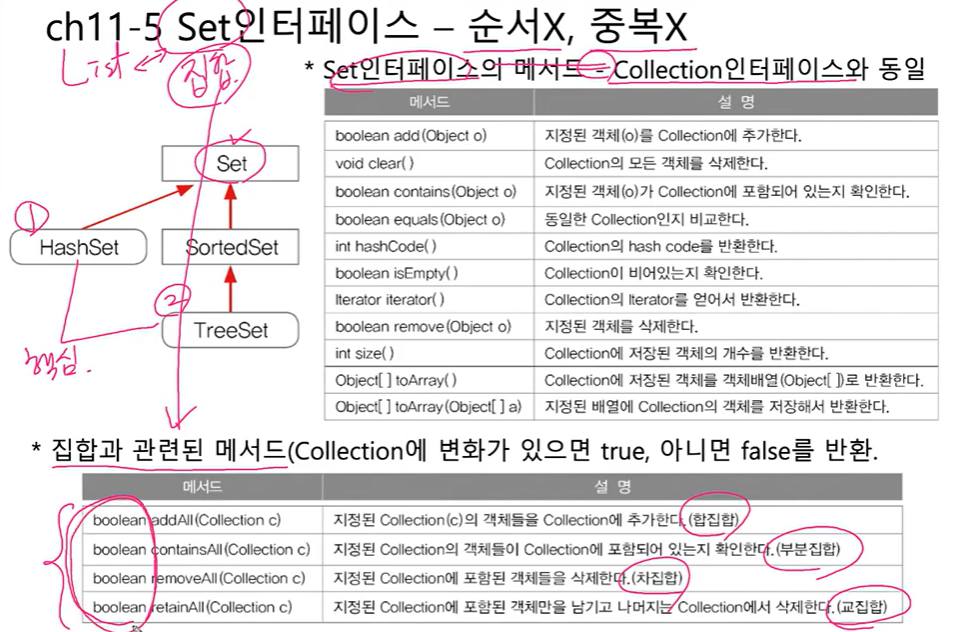
}1-3. set 인터페이스
1-4. Map 인터페이스
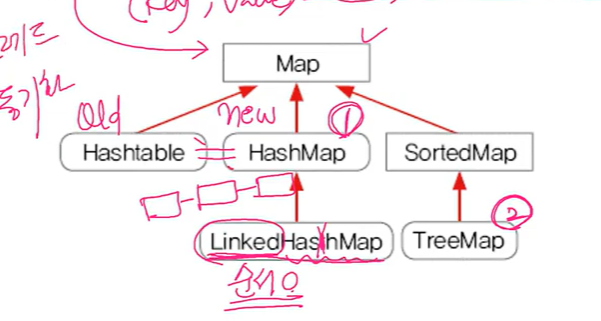
hashtable은 동기화 되어있음
hashmap은 동기화 안 되어있음
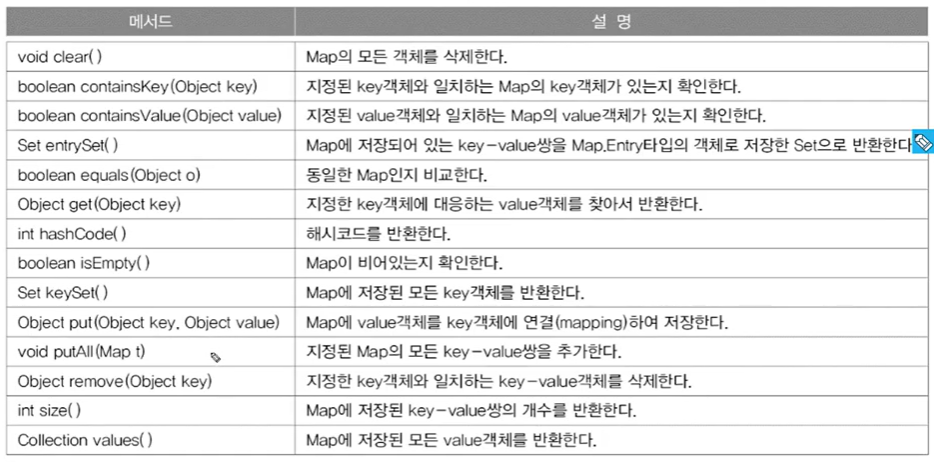
Set ectrySet() : 저장된 모든 키-값 쌍을 불러옴
1-5. Iterator, ListIterator, Enumeration 인터페이스
- 컬렉션에 저장된 데이터를 접근(읽어오기)하는데 사용되는 인터페이스

- 읽는지 확인하고
hashNExt()읽어오기next()! 이 두개만 쓰면 됨! - Enumeration은 Iterator의 구버전
- ListIterator는 Iterator의 접근성을 향상시킨 것(단방향->양방향) 잘 안씀. 신경쓰지 마세요.
- 여러분은 Iterator만 알면 됩니다! - 컬렉션에 iterator()를 호출해서 iterator를 구현한 객체를 얻어서 사용.
List list = new ArrayList();
Iterator it = list.iterator(); //iterator 객체를 반환
while(it.hasNext()) { //요소 있는지 확인
System.out.println(it.next()); //요소 읽어오기
}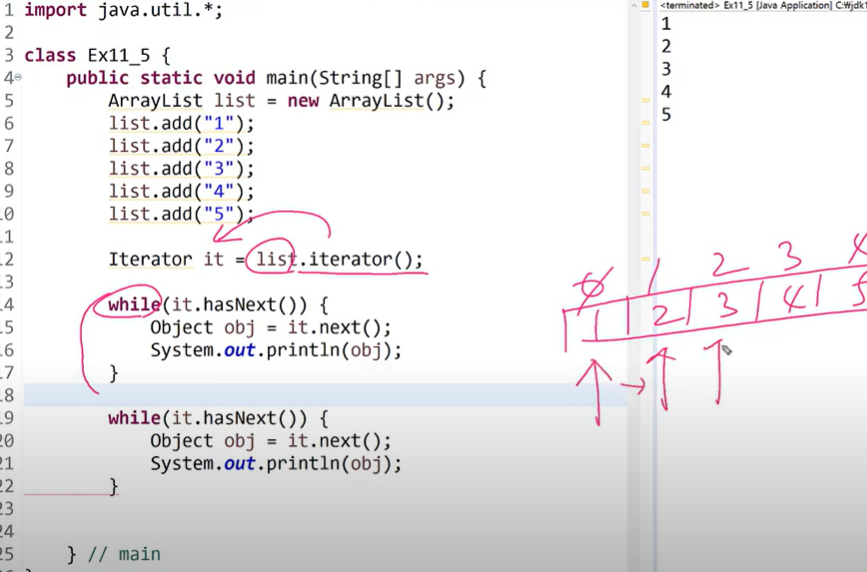
12345가 두 번 안 나오는 이유: 이미 iterator를 다 써버렸기때문.
iterator는 일회용입니다. 한 번 다 끝까지 읽고나면 iterator를 다시 얻어와야 합니다.

이렇게 두 가지 방법으로 읽어오기 가능.
그런데 arraylist를 hashset으로 바꾼다면? hashset은 get()이 없습니다. 그래서 동작을 안 해요.
1-6. Map과 Iterator
- Map에는 iterator가 없다. keySet(), entrySet(), values()를 호출해야.
Map map = new HashMap();
...
Iterator in = map.entrySet().iterator();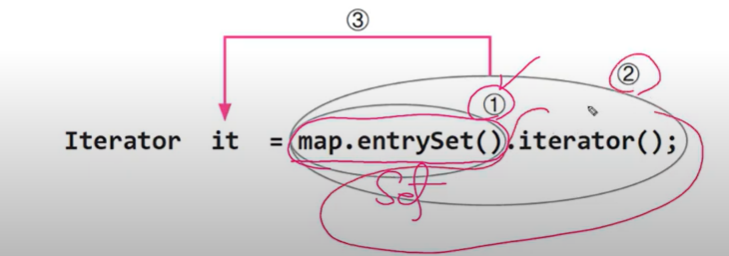
1-7. Comparator와 Comparable
- 객체 정렬에 필요한 메서드(
정렬기준 제공)를 정의한 인터페이스
Comparable : 기본 정렬기준을 구현하는데 사용
Comparator : 기본 정렬기준 외에 다른 기준으로 정렬하고자할 때 사용
public interface comparator {
int compare(Object o1, Object o2);
boolean equals(Object obj); //equals를 오버라이딩 하라는 뜻.
신경쓰지마세요.
}
public interface Comparable {
int comparTo (Object o); //주어진 객체(o)를 자신과 비교
}- Compare()와 compareTo()는 두 객체의 비교결과를 반환하도록 작성
public final class Integer extends Number implements Comparable {
...
public int compareTo(integer anotherInteger) {
int v1 = this.values;
int v2 = anotherInteger value;
//같으면 0, 오른쪽 값이 크면 -1, 작으면 1을 반환
return (v1 < v2 ? -1 : (v1==v2? -: 1));
}
}integer나 String은 기본적으로 Comparable을 구현하고 있다. ==자체적으로 기본 정렬 기준을 갖고 있다.
Q. 정렬 기준만 있어도 정렬이 돼요?
Array.sort()와 같은 메서드가 정렬을 수행하는 과정에서, compareTo()를 호출한다.
1-8. HashSet()
- 순서❌중복❌(list의 정반대. list는 순서O 중복O)
- 대표적으로 Hashset과 TreeSet이 있어요. 이 두개만 아시면 돼요
1-8-1. HashSet()
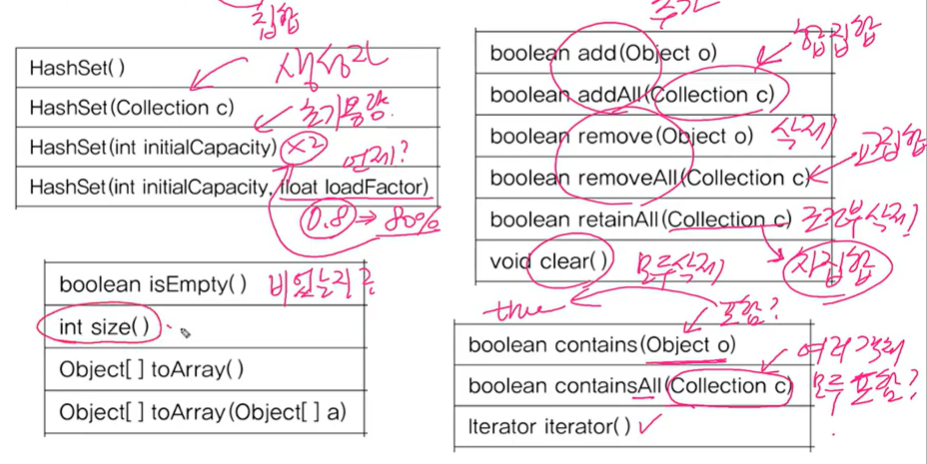
- Set 인터페이스를 구현한 대표적인 컬렉션 클래스
순서를 유지하려면,LinkedHashSet클래스를 사용하면 됨- 주요 메서드
public static void main(String[] args) {
Set set = new HashSet();
for (int i=0; set.size()<6; i++) {
int num = (int) (Math.random()*45) +1;
set.add(num); }
//sort 하기 위해 hashset을 List로 바꾸기 작업
List list = new LinkedList(set);
Collections.sort(list);
Systemm.out.println(list);
}
}✅왜 sort 하기 전 lisr로 바꾸기 작업 할까? sort(List list)다. 그니까 sort는 list(또는 arrayList)만 적용될수 있다.
HashSet()은 객체를 저장하기 전에 기존에 같은 객체가 있는지 확인- 그래서 boolean add(Object o)는 저장할 객체의 equals()와 hashCode()를 호출. 그 객체의 클래스가 equals()와 hashCode()를 오버라이딩 되어 있어야 함! 필수는 아닌데, 그렇게 하는게 좋아요(by 자바의 정석)
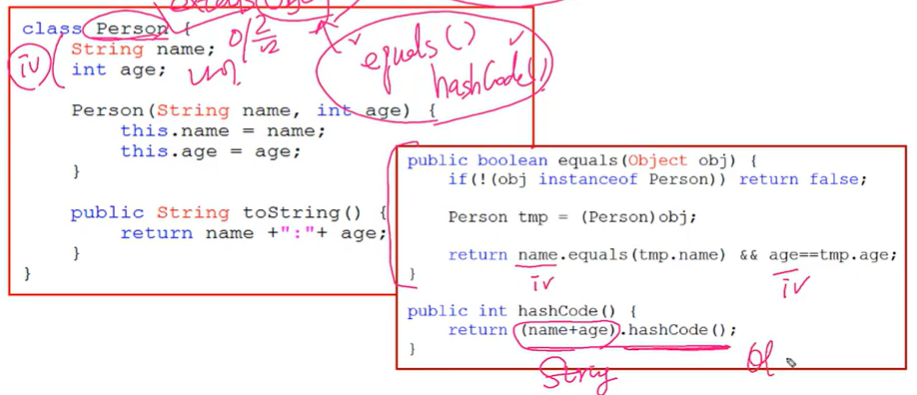
으로 해서 person 클래스의 객체들을 hashSet에 저장할 때, person 클래스에 equals와 hashcode 메서드가 오버라이딩 되어 있어야함. 필수는 아닌데 그렇게 하는게 좋음.
1-8-2. TreeSet()
범위 검색과정렬에 유리한 컬렉션 클래스- HashSet보다 데이터 추가, 삭제 시간이 더 걸림
- 이진 탐색 트리(binary search tree)로 구현. 범위 탐색과 정렬에 유리
이진 트리는 모든 노드가 최대 2개의 하위 노드를 가짐.
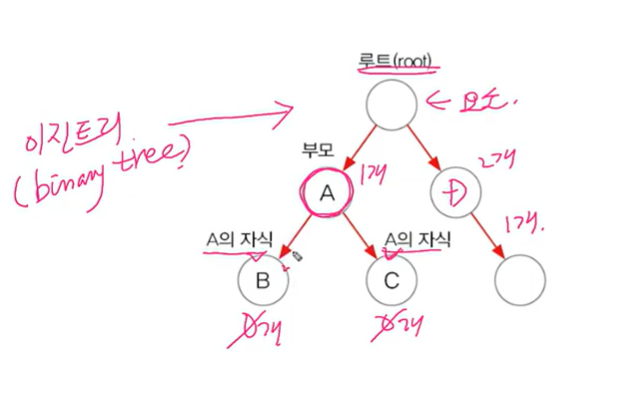
- 부모보다 작은 값은 왼쪽, 큰 값은 오른쪽에 저장
- 데이터가 많아질 수록 추가, 삭제에 시간이 더 걸림(큰지 작은지 비교(오른쪽으로 가져갈지 왼쪽으로 가져갈지) 비교횟수 증가)
- 중복을 허용하지 않기 때문에 넣기 전에 일단 비교함. boolean add(object o)
- 주요 생성자와 메서드
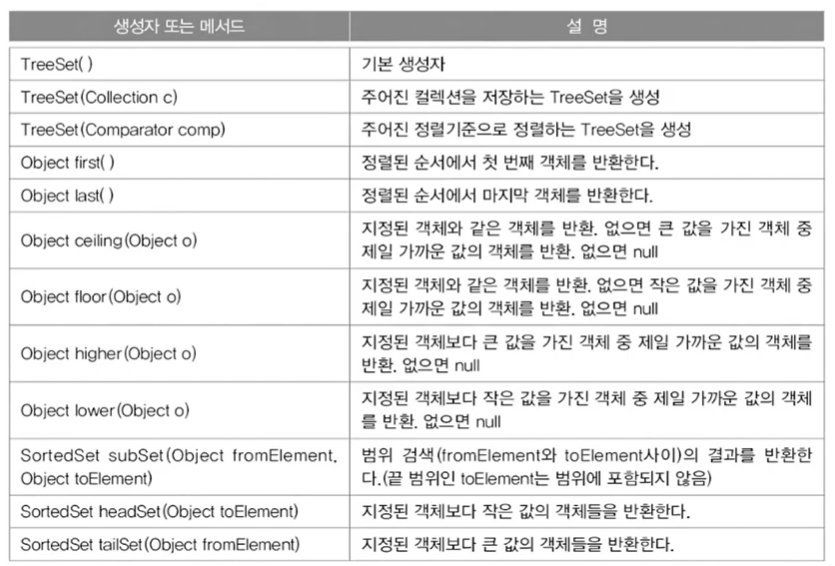
여기에 +add()size()remove()isEmpty()iterator()도 당연히 있음.
public static void main(String[] args) {
Set set = new TreeSet();
for (int i=0; set.size()<6; i++) {
int num = (int) (Math.random()*45) +1;
//Test 객체를 저장해라
set.add(new Test()); //set.add(new Integer(num));으로 하면 오류 안남
오류 나는 코드
}
>> 왜? Treeset은 비교하면서 저장(set)하기 때문에 비교 기준이 없는 Test클래스 객체 경우에는 Error 발
}✅비교하면서 set한다~! 잊지말것. treeset은 순서유지 성질을 갖고 있음!
