
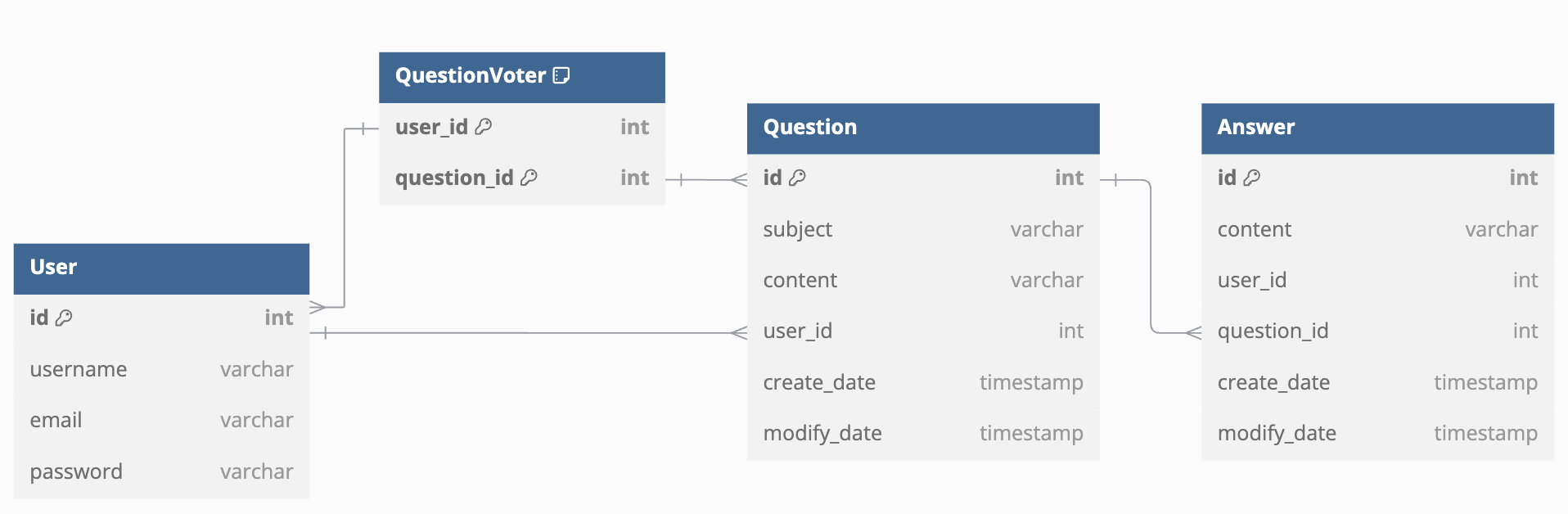
Table
기초
select
데이터를 조회하기 위한 기본 쿼리 생성 함수
-
예시 코드
from sqlalchemy import select stmt = select(Question) results = session.execute(stmt).scalars().all() print("results: ", results) -
결과
results: [ <models.Question object at 0x109b1d190>, <models.Question object at 0x109b1d1c0>, ... ]
filter
조건에 따라 데이터를 필터링하는 함수
- 예시 코드
Question 테이블의 subject가 service인 데이터만 조회from sqlalchemy import select stmt = select(Question).filter(Question.subject == "service") results = session.execute(stmt).scalars().all() print("results: ", results) - 결과
results: [ <models.Question object at 0x10a91cbf0>, <models.Question object at 0x10a91cc20>, <models.Question object at 0x10a91cc50>, <models.Question object at 0x10a91cc80>, <models.Question object at 0x10a91ccb0> ]
order_by
결과 정렬에 사용
-
예시 코드
from sqlalchemy import select stmt = select(Question).order_by(Question.create_date) results = session.execute(stmt).scalars().all() print("results: ", [result.create_date for result in results]) -
결과
기본으로 오름차순 정렬 적용results: [ datetime.datetime(2024, 12, 1, 0, 0), datetime.datetime(2024, 12, 2, 0, 0), datetime.datetime(2024, 12, 3, 0, 0), ... ]
정렬 방식을 지정하고 싶다면?
from sqlalchemy import asc, desc, select # 내림차순 stmt = select(Question).order_by(desc(Question.create_date)) # 오름차순 stmt = select(Question).order_by(asc(Question.create_date))
limit
반환할 레코드 수를 제한
-
예시 코드
Question의 id를 기준으로 오름차순 정렬한 결과 중, 상위 3개의 데이터만 조회from sqlalchemy import asc, select stmt = select(Question).order_by(asc(Question.id)).limit(3) results = session.execute(stmt).scalars().all() print("results: ", [result.id for result in results]) -
결과
results: [1, 2, 3]
offset
반환할 레코드의 시작점을 설정
-
예시 코드
from sqlalchemy import asc, select stmt = select(Question).order_by(asc(Question.id)).offset(3) results = session.execute(stmt).scalars().all() print("results: ", [result.id for result in results]) -
결과
results: [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
join
기본적으로 INNER JOIN을 수행하며, 지정된 조건에 맞는 두 테이블의 교집합을 반환
-
예시 코드
Question 테이블과 Answer 테이블을 join하고 Question의 subject 컬럼의 데이터가 "user"인 데이터만 가지고 옴from sqlalchemy import select stmt = select(Question.content, Answer.content)\ .join(Answer, Question.id == Answer.question_id)\ .filter(Question.subject == "user") results = session.execute(stmt).all() print("results: ", results) -
결과
results: [ ('user-첫번째 질문입니다.', 'user 첫번째 질문 - 답변1'), ('user-첫번째 질문입니다.', 'user 첫번째 질문 - 답변2'), ('user-두번째 질문입니다.', 'user 두번째 질문 - 답변1') ]
outerjoin
기본적으로 LEFT OUTER JOIN을 수행하며, 조건을 만족하지 않는 경우에도 왼쪽 테이블의 모든 레코드 포함, 오른쪽은 NULL로 채움
-
예시 코드
from sqlalchemy import select stmt = select(Question.content, Answer.content)\ .outerjoin(Answer, Question.id == Answer.question_id)\ .filter(Question.subject == "user") results = session.execute(stmt).all() print("results: ", results) -
결과
results: [ ('user-첫번째 질문입니다.', 'user 첫번째 질문 - 답변1'), ('user-첫번째 질문입니다.', 'user 첫번째 질문 - 답변2'), ('user-두번째 질문입니다.', 'user 두번째 질문 - 답변1'), ('user-세번째 질문입니다.', None), ('user-네번째 질문입니다.', None), ('user-다섯번째 질문입니다.', None) ]
all
쿼리 결과를 리스트로 반환
-
예시 코드
from sqlalchemy import select stmt = select(Question) results = session.execute(stmt).scalars().all() print("results: ", results) -
결과
results: [ <models.Question object at 0x109b1d190>, <models.Question object at 0x109b1d1c0>, ... ]
all() 을 사용하지 않는다면?
<sqlalchemy.engine.result.ScalarResult object at 0x108b86c10>
first
첫 번째 결과를 반환
-
예시 코드
from sqlalchemy import select stmt = select(Question) result = session.execute(stmt).scalars().first() print("result: ", result) -
결과
result: <models.Question object at 0x118425190>
중급
scalar / scalars / scalar_one
단일 값 또는 단일 열의 결과를 반환
-
scalars
쿼리 결과에서 각 행의 첫 번째 열 값을 반환. 여러 값을 가져올 때 사용하며, .all()을 사용하여 리스트 형태로 받을 수 있음-
예시 코드
from sqlalchemy import select stmt = select(Question) results = session.execute(stmt).scalars().all() print("results: ", results) -
결과
results: [ <models.Question object at 0x106918fe0>, <models.Question object at 0x106918ce0>, <models.Question object at 0x106919460>, ... ]
-
-
scalar
쿼리 결과에서 첫 번째 레코드의 첫 번째 열 값만 반환하며, 여러 레코드가 있어도 단 하나의 값만 가져옴
stmt = select(Question)의 경우 첫 번째 Question 객체를 반환-
예시 코드
from sqlalchemy import select stmt = select(Question) result = session.execute(stmt).scalar() print("result: ", result) -
결과
result: <models.Question object at 0x106918fe0>
-
-
scalar_one
쿼리가 하나의 결과만 반환할 때 사용. 결과가 없거나 여러 개일 경우 예외(NoResultFound, MultipleResultsFound)가 발생함-
예시 코드
from sqlalchemy import select stmt = select(Question).filter(Question.id == 1) result = session.execute(stmt).scalar_one() # 하나의 결과만 있어야 정상 작동 print("result: ", result) -
결과
result: <models.Question object at 0x106918fe0>
-
update
특정 레코드를 업데이트
-
예시 코드
Question의 id가 1인 데이터의 content, modify_date를 수정from datetime import datetime from sqlalchemy import update stmt = update(Question).where(Question.id == 1)\ .values(content="update content", modify_date=datetime.now()) session.execute(stmt) session.commit()
session.commit()
- 데이터베이스에 변경 사항을 영구적으로 저장.
- 호출하지 않으면 변경 사항이 반영되지 않음.
- session.rollback()을 통해 변경 취소 가능.
delete
특정 레코드를 삭제
-
예시 코드
Question의 id가 5인 데이터를 삭제from sqlalchemy import delete stmt = delete(Question).where(Question.id == 5) session.execute(stmt) session.commit()
현재 Question id가 5인 것을 외래키로 가지고 있는 Answer 데이터때문에 에러 발생
해결 방법1
question_id가 5인 answer 데이터를 삭제한 후, Question 삭제answer_stmt = delete(Answer).where(Answer.question_id == 5) session.execute(answer_stmt) question_stmt = delete(Question).where(Question.id == 5) session.execute(question_stmt) session.commit()
해결 방법2
자식 ForeignKey에 ondelete 제약 조건 추가class Answer(Base): __tablename__ = "answer" ... question_id = Column(Integer, ForeignKey("question.id", ondelete="CASCADE"))
해결 방법3
부모 relationship 에서 cascade 매개변수 지정class Question(Base): __tablename__ = "question" ... answer = relationship('Answer', cascade='delete')question = session.get(Question, 3) session.delete(question) session.commit()
해결 방법2, 3 모두 부모 개체가 삭제될 때 관련된 개체도 함께 삭제하지만 둘의 동작 방식에는 차이가 있음
- 해결 방법2
- ondelete="CASCADE"는 데이터베이스 수준에서 작동
- 부모 테이블의 레코드가 삭제되면 관련된 자식 테이블의 레코드도 자동으로 삭제
- 이 방법은 데이터베이스 자체에서 처리되므로 ORM 없이도 동작
- 해결 방법3
- cascade="delete"는 SQLAlchemy ORM에서 부모-자식 관계를 정의할 때 사용
- 부모 객체를 삭제하면 ORM이 자동으로 관련된 자식 객체를 삭제하는 쿼리를 실행
- 이 동작은 데이터베이스 수준이 아니라 ORM 계층에서 수행
distinct
중복을 제거한 결과 반환
-
예시 코드
Question 테이블의 데이터 중 create_date 컬럼의 중복 데이터를 제거하고 결과 반환from sqlalchemy from select stmt = select(Question.create_date).distinct() results = session.execute(stmt).scalars().all() print("results: ", results) -
결과
results: [ datetime.datetime(2024, 12, 1, 0, 0), datetime.datetime(2024, 12, 2, 0, 0), datetime.datetime(2024, 12, 3, 0, 0), datetime.datetime(2024, 12, 4, 0, 0), datetime.datetime(2024, 12, 5, 0, 0) ]
any
연관된 테이블(relationship)에 하나 이상의 항목이 존재하는 데이터를 조회.
-
예시 코드
좋아요가 존재하는 Question 조회question_voter = Table( 'question_voter', Base.metadata, Column('user_id', Integer, ForeignKey('user.id'), primary_key=True), Column('question_id', Integer, ForeignKey('question.id'), primary_key=True) ) class Question(Base): ... voter = relationship("User", secondary=question_voter, backref="question_voters")from sqlalchemy import select stmt = select(Question).filter(Question.voter.any()) is_exists = session.execute(stmt).scalar() is not None print("is_exists: ", is_exists) -
결과
is_exists: False
subquery
서브쿼리를 작성하기 위한 객체 생성.
-
예시 코드
Answer 테이블에서 question_id가 있는 Question 테이블 레코드를 찾음from sqlalchemy import select subq = select(Answer.question_id).subquery() stmt = select(Question).filter(Question.id.in_(subq)) results = session.execute(stmt).scalars().all() print("results: ", results)코드설명
.subquery(): 서브쿼리로 변환. 즉, 이 쿼리는 임시적인 테이블처럼 사용되며, 결과를 다른 쿼리에서 참조할 수 있게 됨
subq: question_id를 반환하는 쿼리로 변환
stmt: subq 결과인 question_id에 포함되는 Question을 조회하는 쿼리 -
결과
results: [ <models.Question object at 0x1053e9b50>, <models.Question object at 0x1053e9b80>, <models.Question object at 0x1053e9bb0>, ... ]
심화
with_for_update
행을 잠그는 쿼리 (트랜잭션에서 사용).
-
예시 코드
from sqlalchemy import select stmt = select(Question).with_for_update() results = session.execute(stmt).scalars().all()
with_for_update()
- SQLAlchemy의 SELECT 쿼리에 대해 행 잠금을 설정하는 메서드
- 트랜잭션이 실행되는 동안 특정 행(row)을 잠그는 역할
- 동시에 여러 트랜잭션이 동일한 데이터를 수정하려고 할 때 발생할 수 있는 충돌을 방지
- 쿼리로 조회된 행은 다른 트랜잭션에서 변경할 수 없도록 잠그게 됨
동일한 트랜잭션에서는 잠근 행 업데이트 가능stmt = select(Question).with_for_update() # 행 잠금 question = session.execute(stmt).scalars().first() if question: stmt = update(Question).where(Question.id == 3).values(content="update content") session.execute(stmt) session.commit()
aliased
테이블이나 서브쿼리에 별칭을 부여
-
예시 코드
from sqlalchemy import select from sqlalchemy.orm import aliased question_alias = aliased(Question) stmt = select(question_alias).filter(question_alias.id == 1) result = session.execute(stmt).scalars().first() print("result: ", result) -
결과
results: <models.Question object at 0x1068e5220>
options
쿼리에서 특정 로드 전략(eager loading)을 지정하기 위해 사용
Lazy Loading 대신 관계 데이터를 미리 로드하거나 특정 로드 방식을 적용할 때 유용함
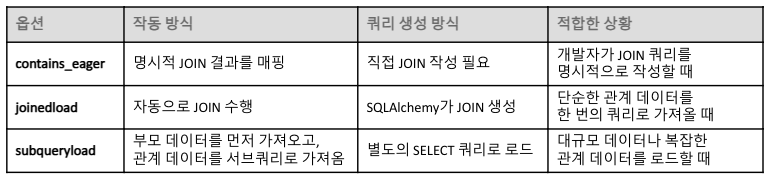
<주요 로드 옵션>
contains_eager: 직접 작성한 JOIN 쿼리를 활용해 관계 데이터를 로드.
joinedload: INNER JOIN 또는 OUTER JOIN을 사용해 관계 데이터를 한 번의 쿼리로 로드.
subqueryload: 두 번째 쿼리를 사용해 관계 데이터를 로드.
-
contains_eager
직접 작성한 SQL JOIN 결과를 ORM 엔티티에 매핑할 때 사용하며, JOIN 결과가 없는 데이터는 제외될 수 있음-
예시 코드
from sqlalchemy import select from sqlalchemy.orm import contains_eager stmt = select(Question).join(User, Question_user_id == User.id)\ .options(contains_eager(Question.user)).order_by(Question.id) results = session.execute(stmt).scalars().all() for result in results: print(f"question: {result.id}, user: {result.user.username if result.user else None}") -
결과
question: 1, user: test1 question: 3, user: test2 question: 4, user: test1 question: 5, user: test2 ...
-
-
joinedload
관계 데이터를 한 번의 쿼리로 가져오는 자동 JOIN 기능이며, 관계가 없는 경우에도 부모 데이터는 유지됨
기본은 LEFT OUTER JOIN이며 필요시 INNER JOIN을 설정할 수 있음-
예시 코드
from sqlalchemy import select from sqlalchem.orm import joinedload stmt = select(Question).options(joinedload(Question.user)).order_by(Question.id) results = session.execute(stmt).scalars().all() for result in results: print(f"question: {result.id}, user: {result.user.username if result.user else None}") -
결과
question: 1, user: test1 question: 2, user: None question: 3, user: test2 question: 4, user: test1 question: 5, user: test2 ...
-
INNER JOIN 설정
stmt = select(Question).options(joinedload(Question.user, innerjoin=True))\ .order_by(Question.id)위와 같이 설정하면 join한 테이블과 관계없는 경우의 부모데이터를 가지고 오지않음
question: 1, user: test1 question: 3, user: test2 question: 4, user: test1 question: 5, user: test2 ...
-
subqueryload
부모 데이터를 먼저 로드한 뒤 관련 데이터를 서브쿼리를 사용해 별도의 SELECT 쿼리로 가져오며, 대규모 데이터나 복잡한 관계에 적합하지만 추가 쿼리가 실행되어 상황에 따라 효율성이 달라질 수 있음-
예시 코드
from sqlalchemy import select from sqlalchemy.orm import subqueryload stmt = select(Question).options(subqueryload(Question.user)).order_by(Question.id) results = session.execute(stmt).scalars().all() for result in results: print(f"question: {result.id}, user: {result.user.username if result.user else None}") -
결과
question: 1, user: test1 question: 2, user: None question: 3, user: test2 question: 4, user: test1 question: 5, user: test2 ...
-
[참고 자료]
