[논문 리뷰] Rethinking of Pedestrian Attribute Recognition: A Reliable Evaluation under Zero-Shot Pedestrian Identity Setting
AIPro

2023.01.12
이번주 목요일부터 2023 겨울방학동안 박천수 교수님의 AI Pro에서 학부연구생? 학부 인턴쉽?을 진행하게 됐는데, 논문을 읽게 되서 내용 정리를 해보려고 한다. 앞으로도 계속 읽을 것 같기도 하고 간단하게 기억하기 위해 번거롭지만 요약해보겠다.
1.Introduction
해당 논문은 PAR 혹은 (Pedestrian Attribute Recognition)에 대한 재정의 및 해당 정의에 따른 strong baseline method를 제안하고자 한다. 해당 실험 및 비교는 기본 4개의 dataset(PETA, RAP1, RAP2, PA100k)와 2개의 따로 제안한 dataset(PETAzs, RAPzs)으로 총 6개의 dataset을 다루고 있다. 해당 dataset들은 사람과 관련된 자료들로 사람들의 행동에 대한 attribute를 담고 있다. 그리고 해당 dataset들을 MsVAA, VAC, ALM, JLAC 등의 다양한 메서드와 여기서 제안하는 baseline method로 성능을 비교한다.

PAR의 핵심 성능 Core Characteristic은 pedestrian의 cropped image에 좌지우지된다한다.
해당 논문에서 기존의 PAR이 믿을만한 성능이 안된다고 주장하는 이유로 크게 2가지를 제안한다. 하나는 다양한 메서드의 다른 backbone network와 다른 실험 환경 때문이고 다른 하나는 test set와 train set에 동일인이 약간의 다른 배경과 포즈를 지닌체 포함되어 있다는 것이다.
해당 논문은 다음과 같은 질문에 대해 답을 채워 나가며 전개했다.
- for the definition: PAR은 무엇이고 이를 구별짓는 본질적인 특성은 무엇인가?
- for the dataset and evaluation protocol: 현존하는 dataset들은 모델의 성능을 제대로 평가할 수 있는가? 그렇지 않다면, 어떤 dataset이 이를 적절히 수행할 수 있을까?
for the existiing methods: 현존하는 method들은 현존하는 dataset에 얼마나 잘 작동하는가? 어떤 요소가 성능에 영향을 주는가?
2. Related Work
여기서는 현존하는 dataset들을 소개한다.
PETA (PEdesTrian Attribute)
- 19,000 images with 61 binary and four multi-class attributes
- viewpoints, occlusions, and body parts
RAP1 (Richly Annotated Pedestrian)
- 41,585 pedestrian samples from real surveliance network of 26 video cameras from a shopping mall
- 69 fine-grained attributes and 3 environmental factors (viewpoints, occlusion styles,and body parts)
RAP2
- 84,928 pedestrians, 72 attributes
PA-100k (Pedestrian Attribute)
- 100,000 images, 26 attributes
그 이후로는 pedestrian attribute methods에 관한 내용이 나오는데, 그다지 중요하지 않은 내용인 것 같다. 사실 이해를 잘 못했다. 아래는 해당 부분에 관한 내용 중 일부이다.
We review the existing methods from two aspects. One type of methods adopts auxiliary information like human parsing or human key points as prior or training supervision. The other type of methods only uses attribute labels as supervision.
3. Problem Definition
정의:
Definition Given a training set of input-target pairs D = {(xi, yi), i = 1, 2, . . . , N}, pedestrian attribute recognition is a task assigning multiple attribute labels yi ∈ {0, 1}M to one pedestrian image xi of the test set, where pedestrian identities (Itest) have never been seen in the training set, i.e., the zero-shot settings between identities of the training set and identities of the test set, Itrain ∩ Itest = ∅.
4. Datasets
여기서 중요한 내용은 Itrain ∩ Itest = ∅이라고 생각한다. Train dataset에서 등장한 사람은 Test dataset에 재등장하면 안된다. 이를 data leakage라고 논문은 정의했다. 다음 사진은 dataset에서 common-identity image와 unique-identity image의 비율이다. common-identity image는 training set와 test set 모두 등장하는 image이고 unique-identity image는 test set에서만 등장하는 image이다.
data leakage 없이 dataset을 구성하는 걸 zero-shot splitting이라고 칭한다.
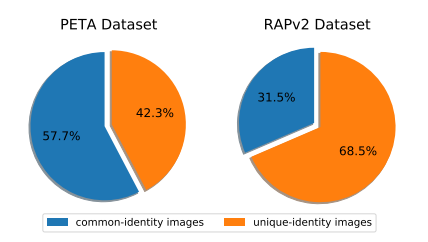
위의 자료와 같이 common-identity가 섞여있는 데이터셋이 있는 걸 알 수 있다. 해당 논문은 다 unique-identity image만 갖는 데이터셋을 만들었고 이를 PETAzs, RAPzs로 만들었다.
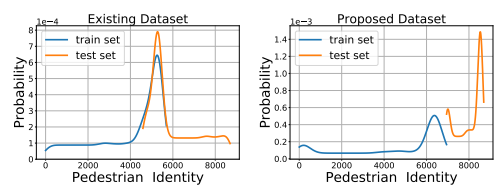
Pedestrian identity distribution on PETA and PETAzs. X-axis indicates the pedestrian identity number and Y-axis is the proportion of corresponding images of the pedestrian identity. Our proposed dataset PETAzs solves the problem by completely separating the pedestrian identities of the test set from the identities of the training set.
또 해당 정의를 따르도록 제안했다.

I는 identity set, | |는 집한의 cardinality, N은 샘플의 개수, R은 positive ratio of the i-th attribute in the validation and test set, T는 threshold를 의미한다.
5. Methods
해당 내용은 생략하려고 한다. Accu, F1, mA, Prec, Recall 등과 Loss function, 3가지의 weight function들에 대한 소개를 했다. 또한 MsVAA, VAC, ALM, and JLAC를 reimplement 하겠다고 소개하는 수준이었다.
6. Experiments
여기서 실험을 진행했는데, baseline method는 PyTorch로 구현되었으며, end-to-end로 학습되었으며, ResNet50을 backbone network로 사용했으며 pedestrian image는 256 X 128 크기로 했다. Adam Optimizer를 사용하기로 했다. ReduceLROnPlateau learning rate scheduler가 사용되었다. Batch size는 64, epoch number는 30으로 설정하였다. 그 결과 MsVAA, VAC보다 더 나은 결과를 냈다고 한다. 정확한 수치는 우선 사진으로 올려보겠다. 아직 잘 모르기 때문이다 ㅎ;;
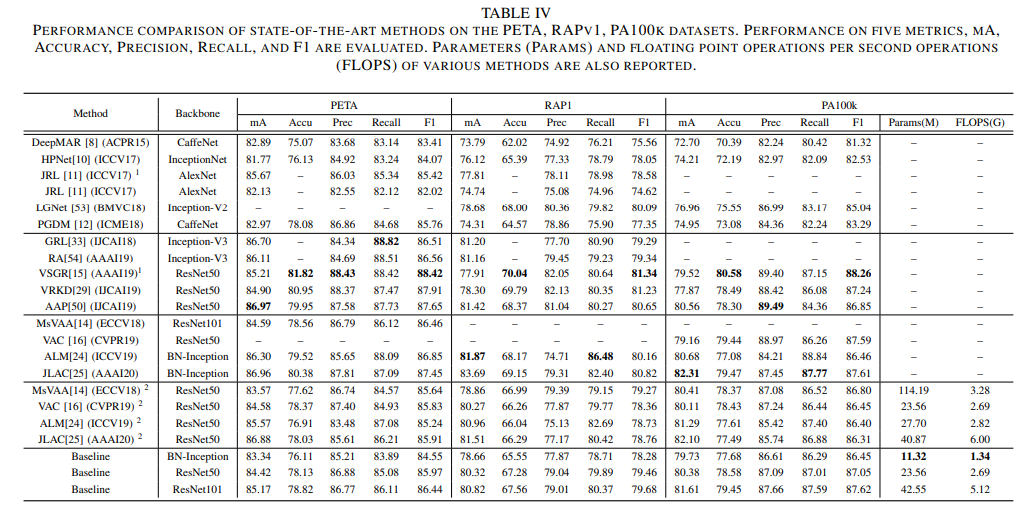
- 추가적으로 Input data의 크기를 늘릴 경우 score이 더 잘 나오는데, 그것은 실생활에 적용될 감시 카메라의 해상도는 낮기 때문에, 의미가 없다고 했다.
7. Conclusion
결론으로는 해당 논문이 현존하는 dataset, PETA, RAP1, RAP2 등의 문제점을 꼬집어냈고 쓸만한 method인 baseline method를 제안한다고 자랑했다. 그리고 새로 제안한 dataset와 더불어서 나중에 참조할 수 있을 것이라고 글을 적으며 마쳤다.
후기
이 논문에서 내가 생각하기에 중요한 점은 zero-shot splitting인 것 같다. 이를 위해서 dataset도 따로 제안하고 모델도 구현했다. 내 아쉬운 점은 모델이 어떻게 구성되어 있는 지 모르겠다는 점이다. ResNet50, ResNet101이 뭔지 잘 모르겠어서 인 것 같기도 하다. 첫 논문인만큼, 이 분야와 아직 친해지는 중이다.
