KeyBERT, TextRazor, wiki api test
키워드 추출 테스트
키워드 추출은 KeyBERT를 이용하고 여러가지 임베딩 모델을 사용하여 키워드추출을 시도하였음.
KeyBERT 모델특성상 시간이 오래걸리고, 토큰 제한이슈가 있음.
토큰제한은 한번에 512개의 토큰으로 제한되는데 토큰은 텍스트에서 인지할수 있는 단어를 한 토큰으로 정함.
근데 unhappniess라는 단어를 인지하지 못한다면 이 단어를 'un'과 'happiness'로 나누어서 2개의 토큰으로 나뉘어짐. 즉, 인지할수 있는 최대한의 단어를 하나의 토큰으로 계산함.
아무튼, 토큰 제한이슈로 인해서 문단을 512개의 토큰으로 나누어서 각각 나누어진 글에 대해서 키워드를 추출하고, 추출한 모든 키워드들을 종합해서 점수가 높은순으로 10개를 추출하는 방식으로 진행.
TextRazor는 KeyBERT이외의 키워드 추출 API를 검색하던중 알게되어 시험해보게 되었음.
MonkeyLearn은 비용 페이지도 사라져있고, 사용하려는데 웹 사이트의 설명 부족으로 API키를 발급 못했음.. ㅠㅠ
AmazonComprehend는 가난한 거지이고, 웹 페이지에서 키워드를 추출하는 기능이라고 하여 제외하였음..
이외에도 여러가지 키워드 추출 API가 있었지만 거의 대부분이 유료버전이라 하루 500건 무료인 TextRazor를 사용하기로 함.
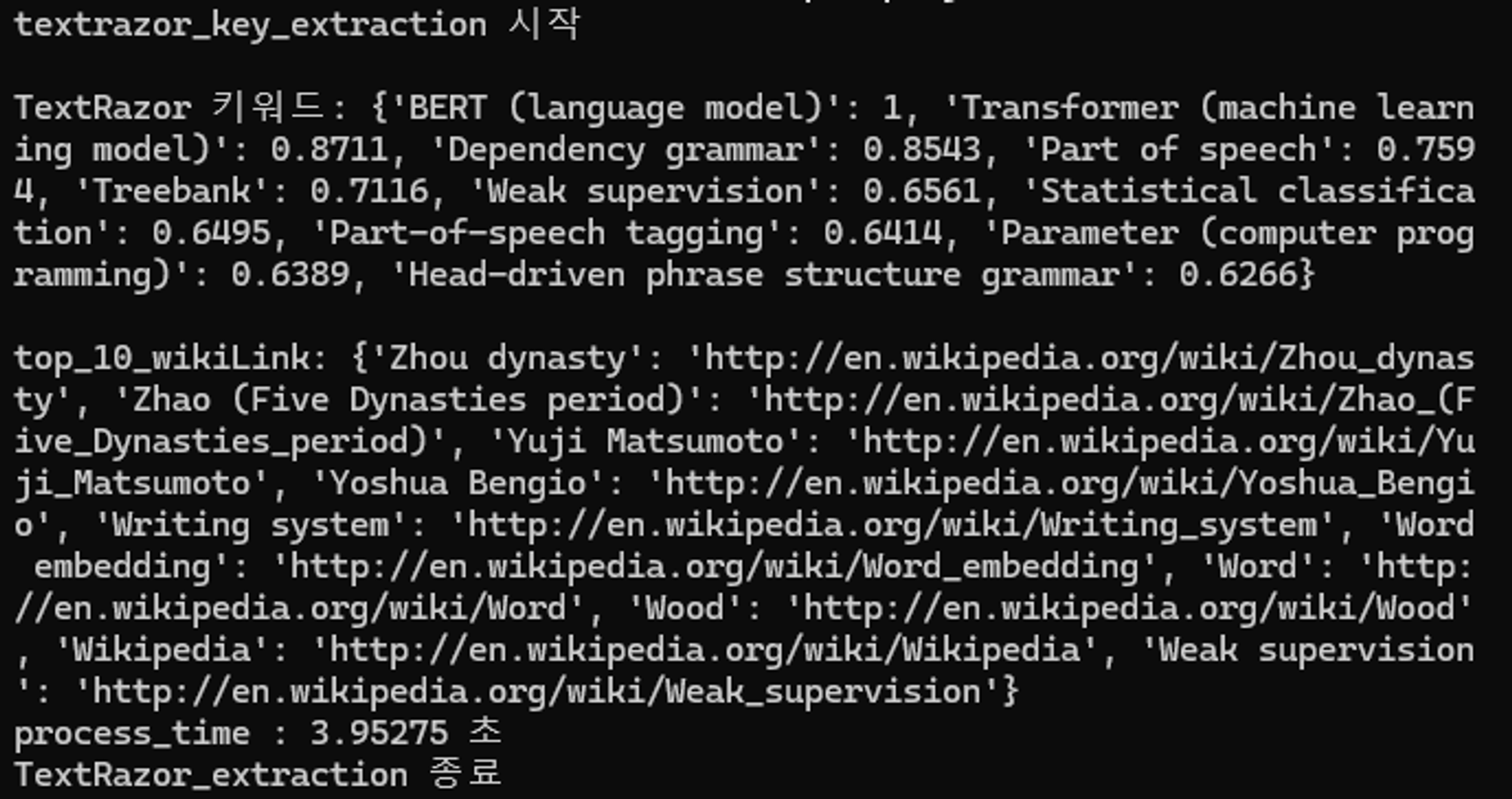
1. text razor
결과화면 :
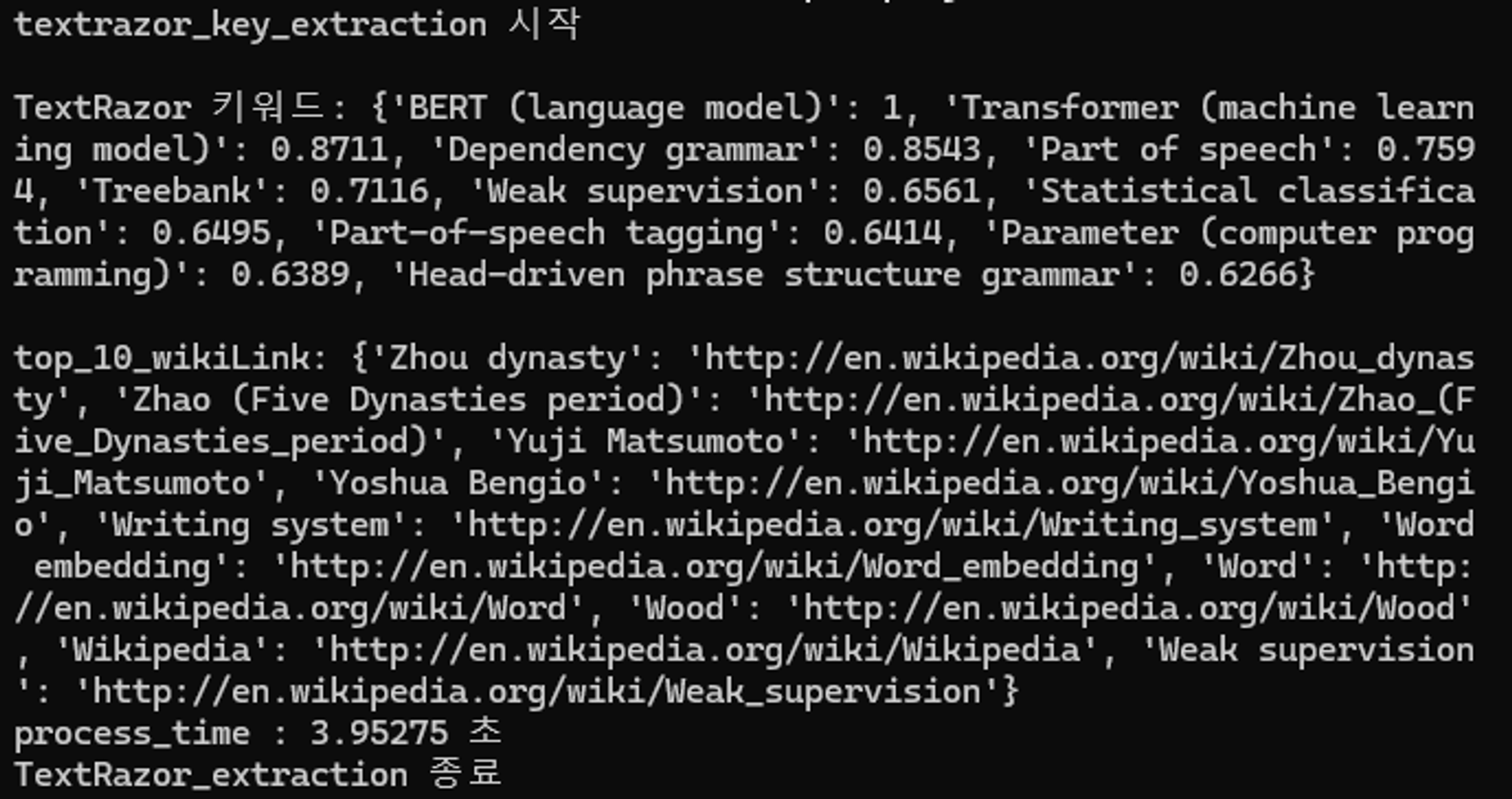
2. KeyBERT(embedding_model = 'distilbert-base-cased')
결과화면 :
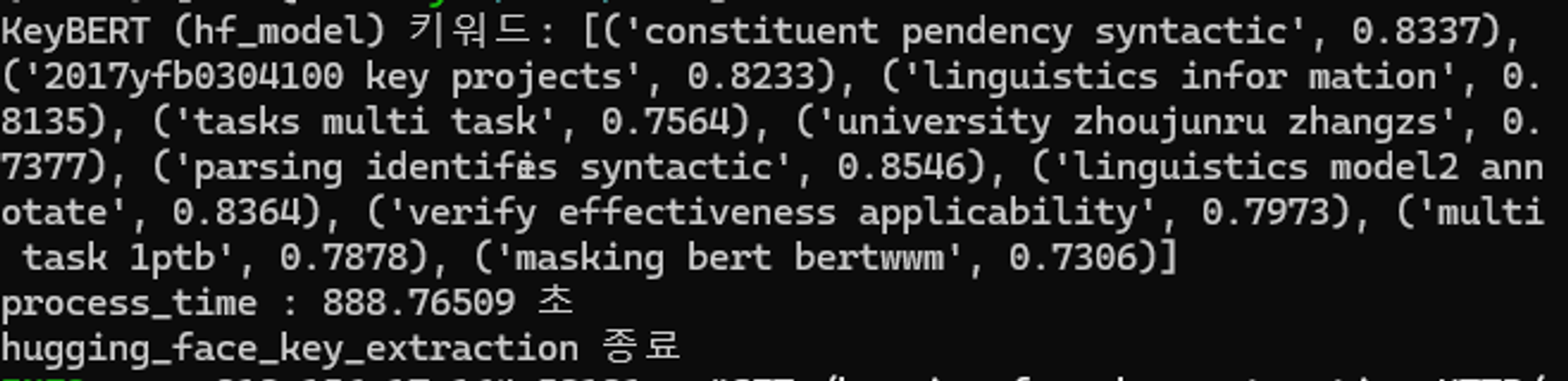
3. KeyBERT(embedding_model = 'all-MiniLM-L12-v2')
결과화면 :

4. KeyBERT(embedding_model = 'roberta-base')
결과화면 :
업로드 예정모델별 정리
키워드 추출 테스트
| 구분 | TextRazor | all-MiniLM-L12-v2 (default_model) | distilbert-base-cased | roberta-base |
|---|---|---|---|---|
| 걸린 시간 | 3.7초 | 84초 | 860초 (약 14분) | 1486초 (약 24분) |
| 키워드 추출 | 'BERT (language model)': 1, 'Phrase structure rules': 1, 'Dependency grammar': 0.9526, 'Treebank': 0.9482, 'Phrase': 0.9118, 'Transformer (machine learning model)': 0.8711, 'Syntax': 0.7488, 'Part of speech': 0.7469, 'Parse tree': 0.7452, 'Parsing': 0.7329 | 'multi task bert': 0.7537, 'bert linguistics informed': 0.7512, 'glue dev test': 0.6971, 'constituent dependency parsing': 0.6967, 'multi task bert': 0.6796, 'semantic role labeling': 0.6757, 'word masking spm': 0.6756, 'limit bert based': 0.6621, 'linguistics tasks speech': 0.6613, 'deep utterance aggregation': 0.6479 | 'construct task specific': 0.8745, 'tokens corresponding syntac': 0.8725, 'parser10 dependency syntactic': 0.8677, 'bidirectional representations': 0.8661, '2018b syntactic parsing': 0.8599, 'loss predicted tokens': 0.8588, 'steedman 2000 syntactic': 0.8567, 'parsing identifies syntactic': 0.8546, 'argument annotation formulizations': 0.8502, 'dependency syntactic parsing': 0.8478 | 'bert 10http nlp': 0.9963, 'bert parameters transformer': 0.9962, 'computational linguistics': 0.9962, 'highly lexicalized non': 0.9961, 'pretrained bert use': 0.996, 'linguistics tasks multi': 0.996, '2009 linguistics guided': 0.9957, 'output discriminator transformer': 0.9957, 'high performance chen': 0.9957, 'tion efficient decoding': 0.9957 |
all_MiniLM-L12-v2은 KeyBERT의 기본 모델로, 성능과 속도측면에서 고만고만한 모델임.
distilbert-base-cased 모델은 허깅페이스에서 찾은 모델로 BERT모델의 성능을 유지하면서 속도를 최적화 했다고 하길래 시도해보았음.
roberta-base 모델은 성능이 가장 좋다고 하여서 시도해보았음.
TextRazor는 그냥 API 호출 방식임.
결과를 보면 TextRazor가 뭔가 일반적인 키워드들을 많이 추출한다고 생각되고, 속도 측면에서도 KeyBERT가 너무 무겁고 Token 제한으로 인해 추출한 키워드들이 전체 맥락에서 보면 적합하지 않다고 생각되므로 TextRazor 사용하는것이 효율적이다는 결론을 내렸음.
위키 api 테스트
-
wiki-qa api
Q : BERT모델이 뭐야??
A : ???? 정의를 찾지 못했습니다 ????

Q : What is BERT??
A : []

Q : 버트 모델이 뭐야???
A : 나디아 코마네치??? 어쩌고 저쩌고
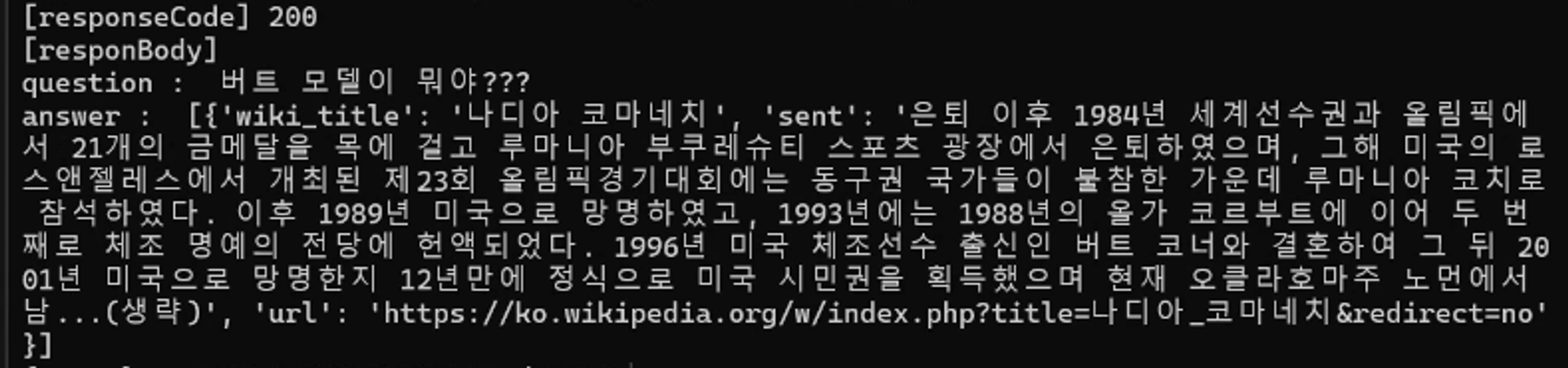
한국어만 인식을 하고 영어가 들어가있으면 인식을 하지 못함.
이런 이슈로 인해서 그냥 wiki-api를 사용하여 wiki 결과를 그대로 가져다 주기로 하였음. -
wiki api
추출한 키워드 하나를 넣어서 위키에 검색을 한 결과임.

API 코드(Code Conversation 에 맞춰서 수정할 예정임.)
import fitz
from sentence_transformers import SentenceTransformer
from keybert import KeyBERT
from flair.embeddings import TransformerDocumentEmbeddings
import textrazor
import os
import time
from transformers.pipelines import pipeline
from transformers import AutoTokenizer
from fastapi import FastAPI
import uvicorn
from fastapi.responses import JSONResponse
import wikipedia
import wikipediaapi
app = FastAPI()
PDF_FILE_PATH = './1910.14296v2.pdf'
def extract_pdf_to_text(path):
doc = fitz.open(path)
text = ""
for page in doc:
text += page.get_text("text")
return text
# 텍스트를 토큰 단위로 나누는 함수
def chunk_text(text, max_length=512):
words = text.split()
chunks = [' '.join(words[i:i + max_length]) for i in range(0, len(words), max_length)]
return chunks
# Tokenizer 초기화
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
print('키워드 추출 처리 중')
def highlighted_text_to_html(highlighted_text: str):
"""하이라이트된 텍스트를 HTML 파일로 저장"""
html_content = f"""
<html>
<head>
<title>Highlighted Text</title>
</head>
<body>
{highlighted_text}
</body>
</html>
"""
return html_content
#--------------------------------------------TextRazor---------------------------------------------
def textrazor_key_extraction(text):
print('textrazor_key_extraction 시작')
wiki = []
start = time.time()
data = {}
link = {}
keyword = {}
# TextRazor를 사용한 키워드 추출
textrazor.api_key = os.getenv('TEXTRAZOR_API_KEY')
client = textrazor.TextRazor(extractors=["entities", "keywords"])
response = client.analyze(text).json['response']
entities = response['entities']
# 엔티티에서 키워드와 점수 추출
for entity in entities:
word = entity['entityId']
score = entity['relevanceScore']
wikiLink = entity['wikiLink']
keyword[word] = score
link[word] = wikiLink
# 키워드를 점수 기준으로 정렬하여 상위 10개 선택
top_10_keywords = dict(sorted(keyword.items(), key=lambda item: item[1], reverse=True)[:10])
end = time.time()
print("\nTextRazor 키워드:", top_10_keywords)
print(f"process_time : {end - start:.5f} 초")
print('TextRazor_extraction 종료')
return top_10_keywords
# --------------------------------------------허깅페이스 모델---------------------------------------------
def hugging_face_key_extraction(text):
print('hugging_face_key_extraction 시작')
chunks = chunk_text(text, max_length=512)
hf_model = pipeline("feature-extraction", model="distilbert-base-cased")
hf_kw_model = KeyBERT(model=hf_model)
start = time.time()
hf_key = []
for chunk in chunks:
hf_key.extend(hf_kw_model.extract_keywords(
chunk,
keyphrase_ngram_range=(1, 3),
top_n=5,
use_maxsum=True,
diversity=0.5,
use_mmr=True,
nr_candidates=20,
highlight=False # highlight를 False로 설정하여 키워드만 추출
))
end = time.time()
hf_key = list(dict.fromkeys(hf_key))
hf_key = sorted(hf_key, key=lambda x: x[1], reverse=True)
print("\nKeyBERT (hf_model) 키워드:", hf_key[:10])
print(f"process_time : {end - start:.5f} 초")
print('hugging_face_key_extraction 종료')
return hf_key[:10]
# --------------------------------------------기본 모델---------------------------------------------
def default_key_extraction(text):
print('default_key_extraction 시작')
start_time = time.time()
chunks = chunk_text(text, max_length=512)
model = KeyBERT('all-MiniLM-L12-v2')
default_key = []
for chunk in chunks:
keywords = model.extract_keywords(
chunk,
keyphrase_ngram_range=(1, 3),
top_n=10,
use_maxsum=True,
diversity=0.5,
use_mmr=True,
nr_candidates=20,
highlight=False # highlight를 False로 설정하여 키워드만 추출
)
default_key.extend(keywords)
default_key = list(dict.fromkeys(default_key))
default_key = sorted(default_key, key=lambda x: x[1], reverse=True)
end_time = time.time()
print("default 모델 키워드:", default_key[:10])
print(f"process_time : {end_time - start_time:.5f} 초")
return default_key
# --------------------------------------------roberta 모델---------------------------------------------
def roberta_key_extraction(text):
print('roberta_key_extraction 시작')
start = time.time()
chunks = chunk_text(text, max_length=512)
print('roberta_key_extraction 시작')
roberta = TransformerDocumentEmbeddings('roberta-base')
kw_model = KeyBERT(model=roberta)
roberta_key = []
for chunk in chunks:
roberta_key.extend(kw_model.extract_keywords(
chunk,
keyphrase_ngram_range=(1, 3),
top_n=5,
use_maxsum=True,
diversity=0.5,
nr_candidates=20,
highlight=False # highlight를 False로 설정하여 키워드만 추출
))
end = time.time()
roberta_key = list(dict.fromkeys(roberta_key))
roberta_key = sorted(roberta_key, key=lambda x: x[1], reverse=True)
print("\nKeyBERT (roberta) 키워드:", roberta_key[:10])
print(f"{end - start:.5f} 초")
print('roberta_key_extraction 종료')
return roberta_key[:10]
def search_wikipedia(keyword):
search_results = wikipedia.search(keyword)
if search_results:
first_result = search_results[0]
wiki_wiki = wikipediaapi.Wikipedia(
user_agent='MyProjectName (merlin@example.com)',
language='en',
extract_format=wikipediaapi.ExtractFormat.WIKI
)
page = wiki_wiki.page(first_result)
first_paragraph = page.text.split('\n\n')[0]
print(f"{keyword} : {first_paragraph}")
return f"{keyword} : {first_paragraph}"
else:
print("검색 결과가 없습니다.")
return None
@app.get('/textrazor_key_extraction')
async def textrazor_key(text: str):
result = textrazor_key_extraction(text)
return result
@app.get('/hugging_face_key_extraction')
async def hugging_face_key(text: str):
result = hugging_face_key_extraction(text)
return result
@app.get('/default_key_extraction')
async def default_key(text: str):
result = default_key_extraction(text)
return result
@app.get('/roberta_key_extraction')
async def roberta_key(text: str):
result = roberta_key_extraction(text)
return result
@app.get('/host_wikipedia')
async def call_wikipedia(text: str):
result = search_wikipedia(text)
return result
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
