Chapter 4 YARN
-
yarn : resource manager
-
Resource Manger : 머리통으로 하둡 전체 리소스의 상태를 체크하고 있으며 이또한 노드 매니져들로부터 주기적인 하트비트를 받고 있다.
-
Node Manager : 자기 노드에서 컨테이너를 구동하고 모니터링하여 리소스 매니저에게 보고한다.
-
Application Master : 어플리케이션이 (spark job 등) 이 구동 시 노드 매니저에 어플리케이션 마스터가 구동이되고 리소스 매니저로 요청을 보내 컨테이너 띄워야할 정보를 리턴 받는다.
-
Container (worker) : 어플리케이션이 실제 구동되는 컨테이너
Scheduler
제한된 리소스를 공유해야하기 때문에 어떻게 자원을 나눌지에 대한 스케쥴링을 나타낸다
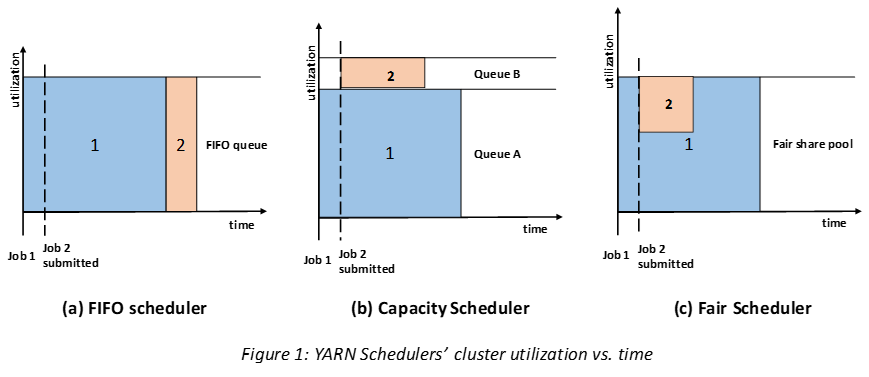
-
FIFO : 그냥 들어오는데로 처리한다.
-
Capacity : 일정량의 capacity를 유저에게 부여하고 서로 가끔씩 겹치게 사용할 수 있다 (1, 2에게 동일하게 50 프로씩을 할당하고 2가 잡이 적을때는 1이 75프로씩 사용할 수 있게끔하는 방법). 직접 경험해봤던 스케쥴러는 40 40 20(ETL) 이렇게 유저 3명을 생성하고 각 부서(2개) 에게 40씩을 부여하고 한쪽이 사용량이 적으면 60까지 사용할 수 있게 설정하였었다. Ambari 에서는 간단하게 UI로 설정 후 재 구동하면 된다.
-
Fair : 말 그대로 균등하게 처리한다 즉 1이 수행되고 있는데 2가 들어오면 반씩 자원을 공유하고 2가 끝나면 다시 1이 다쓰게 된다. Capacity Schuduler와 Fair Scheduler를 혼합하여 많이 사용하는 것으로 알 고 있다.
Chapter 5 : Hadoop I/O
- 체크썸 : Hadoop은 CRC-32C라는 알고리즘으로 체크썸을 계산하여 데이터의 무결성을 보장한다.
압축
gzip :
1. 압축률이 매우 높으나 분할 (hdfs 블록으로) 이 불가능하여 데이터를 읽기 위해서는 하나의 노드로 모든 블록을 모아야한다.
bzip2 : 분할을 사용할 수 있다.
Snappy : g나 bzip보다 훨씬 빠른 압축/해제 속도를 가지고 있으나 압축률이 저조하다. 그렇기 때문에 테이블 구성시 (많이 사용되는) 스내피를 사용하면 좋다.
직렬화
네트워크 전송을 위해 객체를 바이트 스트림으로 전환하는 과정 그리고 Hadoop에서는 Writable이라는 표ㅕ준 인터페이스로 이를 구현하고 크게 write 와 readFields 라는 두개의 메소드를 기본적으로 사용한다.
