해시 테이블은 해시 함수의 결과값을 인덱스로 데이터를 관리한다.
그리고 Set은 값 자체를 해시 함수 인풋으로 사용한다 즉 그 인풋에 대한 해시 함수 결과 값이 인덱스가 되는 것이다. 그렇기 때문에 set은 일반적인 튜플보다 많은 메모리를 사용한다.
import sys
l = [1,2,3,4]
t = (1,2,3,4)
s = set()
s.add(1)
s.add(2)
s.add(3)
s.add(4)
print(sys.getsizeof(l))
print(sys.getsizeof(t))
print(sys.getsizeof(s))
## Result
120
72
216결과를 보면 배열보다도 많은 메모리를 사용하게 된다.
조금더 파보자 일반적으로 해시 테이블 사용하기 때문에 더 많은 메모리를 할당 받아야한다고 이해하고 있다 그런데 나의 궁금증은 왜 해시 테이블이 필요하지? 해시 테이블이 정확히 뭐지? 라는 궁금증을 자아낸다. 그냥 함수 하나 딸랑 있으면 되는거 아닌가?
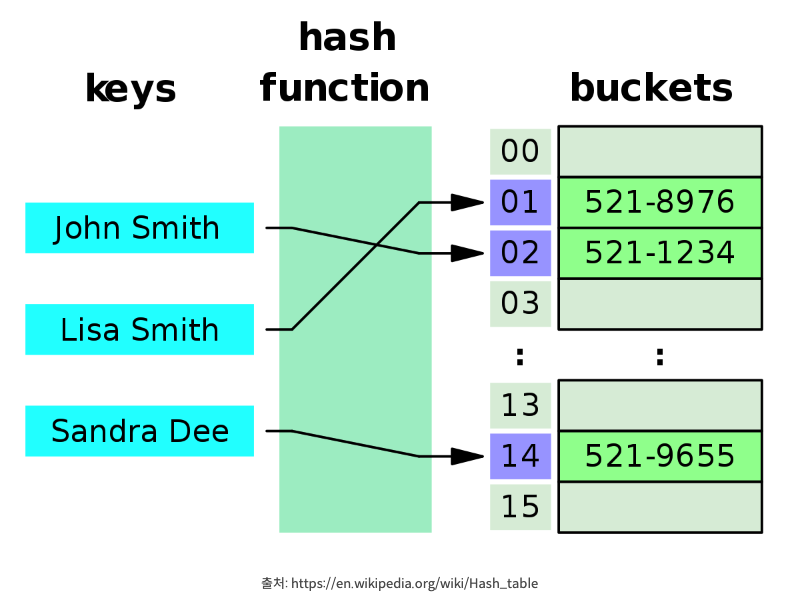
해시 공부하면 항상 나오는 사진이다. 결국 존스미스에 대한 해시 결과가 버켓과 이어지고 이로인해 빠른 탐색이 가능해진다. 그럼 여기서 해시 테이블이 뭐냐? 모르겠다.
그냥 일반적인 배열을 생각해보자.
a = [1,2,3,4]
a[1]
print(id(a[1]))
## Result
140382482524496이런식으로 결과가 나온다. 결국 그럼 배열도 index라는 해시 테이블을 사용하고 있다는말이 아닌가? 1 번 인덱스가 140382482524496 메모리 주소를 바라봐야 하는것 아니냐는 말이다. 140382482524495 번부터 시작하는 배열은 따로 인덱스를 저장하지 않고 사용하고 있는것이다. 그러나 결국 파이썬 list[i]를 사용하면 i +140382482524495라는 해시 함수를 사용하고 있다는 것 아닐까?
결론은 아니다 배열은 선언을 할때부터 메모리의 양을 할당한다. 그러나 set은 메모리 주소가 메핑되는 결과 테이블을 따로 저장하고 이게 바로 해시 테이블이다! 이해완

어려움에 성장하는 데이터 엔지니어