프로젝트를 진행하며 SQL-Server와 Spark를 사용하여 ETL을 진행하는데 있어 T-SQL과 Pyspark의 orderBy에서 차이가 일어나는 현상이 있어 이를 해결하기 위한 방법을 공유하고자 한다.
T-SQL 로 대문자 소문자 혼합 문자열에 대해 정렬을 하면
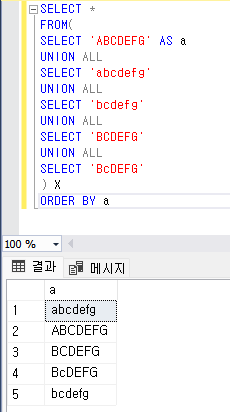
이와 같이 된다 하지만 동일한 문자열에 대하여 pyspark 에서 정렬을 진행한다면.
+-------+
| a|
+-------+
|ABCDEFG|
| BCDEFG|
| BcDEFG|
|abcdefg|
| bcdefg|
+-------+결과가 완전히 다르며 pyspark에서는 대문자가 우선 순위를 가지게 되며 이를 T-SQL과 맞추기 위해서는
pdf.orderBy(lower(col("a"))).show()lower() 를 사용해 주면 그 결과가 동일해 진다.
+-------+
| a|
+-------+
|abcdefg|
|ABCDEFG|
| BCDEFG|
| BcDEFG|
| bcdefg|
+-------+
어려움에 성장하는 데이터 엔지니어