자료구조란?
- 여러 개의 데이터가 묶여있는 자료형을
컨테이너 자료형이라고 하고, 이러한 컨테이너 자료형의 데이터 구조를 자료구조라고 한다
List
- 여러개의 데이터(아이템)를 나열한 자료구조
- 각각의 데이터를 item이라고 함
- 리스트는 item 배열의 메모리 주소를 참조하는 방식임
# 숫자, 문자(열), 논리형 등 모든 기본데이터를 같이 저장할 수 있다.
#strs은 list의 reference 변수
strs = [3.14, '십', 20, 'one']
#리스트안에 또 다른 리스트 저장 가능
dates = [10, 20, 30, [40, 50, 60]]
index
- 아이템에 자동으로 부여되는 번호표로 0부터 시작함
- 리스트 아이템은 인덱스를 이용해 접근 가능함
students = ['홍길동', '박찬호', '이용규', '김지은']
print(students[1])
#출력값: 박찬호아이템 개수 (item)
- 리스트의 길이란, 리스트에 저장된 아이템 개수를 뜻한다.
students = ['홍길동', '박찬호', '이용규', '김지은']
sLenth = len(students)
print(sLenth)
#출력값: 4for문을 이용한 내부 리스트 조회
- for문을 이용하면 리스트 안의 아이템을 자동으로 참조할 수 있다.
studentCnts = [[1, 19], [2, 20], [3, 22], [4, 18]]
# 변수를 2개 주면 리스트 안 리스트도 참조 가능!
for classNo, cnt in studentCnts:
print(f'{classNo}학급 학생수: {cnt}')
#위 코드블럭과 동일한 출력값을 가짐
for i in studentCnts:
print(f'{i[0]}학급 학생수: {i[1]}')
'''
출력값:
1학급 학생수: 19
2학급 학생수: 20
3학급 학생수: 22
4학급 학생수: 18
'''enumerate()
- 아이템을 열거할 수 있음
sports = ['농구', '수구', '축구', '마라톤', '테니스']
strs = 'Hello python.'
for idx, str in enumerate(strs):
print(f'{idx}: {str}\t', end='')
print()
for idx, value in enumerate(sports):
print(f'{idx}: {value}\t', end = '')
아이템 추가: append() / insert(idx, value)
append(): 리스트 끝에 item을 추가하는 함수insert(idx, value): 특정 위치(인덱스)에 item을 추가하는 함수
students = ['홍길동', '박찬호', '이용규', '박승철', '김지은']
students.insert(3, '김은비')
print(students)
#출력값: ['홍길동', '박찬호', '이용규', '박승철', '김지은']
print(students[3])
#출력값: 김은비item 삭제: pop() / remove()
pop(): 마지막 인덱스에 해당하는 item 삭제
pop(n): n index에 해당하는 아이템 삭제 가능- 삭제한 item 값을 반환 함
numbers = [1, 3, 6, 11, 45, 54, 62, 74, 85]
num = numbers.pop()
print(numbers)
#출력값: [1, 3, 6, 11, 45, 54, 62, 74]
print(num)
#출력값: 85
remove(value): 특정 item을 삭제
- 동일한 value를 가진 item이 2개 이상일 경우, 1개만 삭제됨
students = ['강호동', '박찬호', '이용규', '강호동', '박승철', '김지은', '강호동']
print(students)
#출력값: ['강호동', '박찬호', '이용규', '강호동', '박승철', '김지은', '강호동']
#list 안의 모든 value값을 삭제하고 싶을 때는, while문 이용하면 됨!
while '강호동' in students:
students.remove('강호동')
print(students)
#출력값: ['박찬호', '이용규', '박승철', '김지은']
del키워드를 사용한 삭제
- del list_name[index]
리스트 연결(확장): expend(), +
expend()와
+의 차이점
- expend()를 이용해서 연결할 경우 두 개의 list 자체가 합쳐지는 개념
+연산자를 이용해서 연결할 경우 두 개의 list가 합쳐진 새로운 list가 생성 되는 개념!
리스트 정렬: sort()
sort(): 오름차순(기본값)으로 아이템 정렬- 문자, 숫자 등 크키 비교가 가능한 item에 모두 적용 가능
students = ['홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은']
print(students)
#출력값: ['홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은']
students.sort()
print(students)
#출력값: ['강호동', '김지은', '박승철', '박찬호', '이용규', '홍길동']
#오름차순 정렬
students.sort(reverse=True)
print(students)
#출력값: ['홍길동', '이용규', '박찬호', '박승철', '김지은', '강호동']리스트 순서 뒤집기: reverse()
- 리스트 item의 정렬 순서를 뒤집어 주는 함수, sort는 정렬임으로 다름
리스트 슬라이싱: list_name[n:m] / list_name[slice(n,m)]
- 리스트에서 원하는 아이템만 뽑아내는 함수
- n <= index < m의 아이템을 추출해 줌
- n, m 모두 생략 가능하고, 음수 값도 가능
numbers = [2, 50, 0.12, 1, 9, 7,17, 35, 100, 3.14]
print(f'numbers: {numbers[2:-2]}')
#출력값: numbers: [0.12, 1, 9, 7, 17, 35]
#마지막 인수는 출력 단계
print(f'numbers: {numbers[2:-2:2]}')
#출력값: numbers: [0.12, 9, 17]
print(f'numbers: {numbers[:-2:2]}')
#출력값: numbers: [2, 0.12, 9, 17]
print(f'numbers: {numbers[::2]}')
#출력값: numbers: [2, 0.12, 9, 17, 100]슬리이싱을 이용하여 아이템 변경 가능
리스트의 곱셈
students = ['홍길동', '박찬호', '이용규']
print(f'students: {students}')
studentsMul = students * 2
print(f'students: {studentsMul}')
numbers = [2, 50, 0.12, 1, 9]
print(f'numbers: {numbers}')
#각 숫자에 2가 곱해지는 것이 아닌 리스트 item이 두 번 반복됨
mumbersMul = numbers * 2
print(f'numbers: {mumbersMul}')특정 item의 index 찾기: index()
students = ['홍길동', '강호동', '박찬호', '이용규', '박승철', '강호동', '김지은']
print(students.index('강호동'))
#index 2와 6 사이에 있는 '강호동'을 찾음
print(students.index('강호동', 2, 6))특정 item의 갯수 찾기: count()
students = ['홍길동', '강호동', '박찬호', '이용규', '박승철', '강호동', '김지은']
print(students.count('강호동'))
#출력값: 2문자열을 리스트로, 리스트를 문자열로 바꾸는 함수: split(), join()
1) split(): 문자열을 특정 구분자를 기준으로 분할하여 리스트를 반환하는 함수
- 기본적으로는 공백(스페이스, 탭, 개행문자 등)이지만, 사용자가 직접 구분자를 지정할 수도 있음
sentence = "Hello, how are you?"
words = sentence.split() # 기본적으로 공백을 구분자로 사용하여 문자열을 분할합니다.
print(words)
# 출력: ['Hello,', 'how', 'are', 'you?']
sentence = "apple,banana,orange"
fruits = sentence.split(",") # 쉼표를 구분자로 사용하여 문자열을 분할합니다.
print(fruits)
# 출력: ['apple', 'banana', 'orange']2) join(): 리스트의 각 요소를 구분자와 함께 결합하여 하나의 문자열로 반환해줌
- split의 반대작업을 수행
구분자.join(list_name)
words = ['Hello', 'how', 'are', 'you?']
sentence = ' '.join(words) # 리스트의 각 요소를 공백으로 구분하여 하나의 문자열로 결합합니다.
print(sentence)
# 출력: 'Hello how are you?'
fruits = ['apple', 'banana', 'orange']
sentence = ', '.join(fruits) # 리스트의 각 요소를 쉼표와 공백으로 구분하여 하나의 문자열로 결합합니다.
print(sentence)
# 출력: 'apple, banana, orange'Tuple
- list와 비슷하지만 한 번 정의되면, 내부 데이터를 바꿀 수 없음
- list와 달리 tuple은 선언 시, 괄호 생략이 가능함
- list와 tuple은 자료형 변환이 가능함
extend(), append(), sort(), pop() 등의 item을 변경하는 method 사용 불가능
myFavortieNumbers = (1, 4, 5, 6, 7, 8)
friendFavortieNumbers = (2, 6,3, 8, 4, 5, 9)
#중복되는 item 없이 두 개의 튜플을 합치기!
for numbers in myFavortieNumbers:
if numbers not in friendFavortieNumbers:
myFavortieNumbers = myFavortieNumbers + (numbers, )
#int를 tuple로 만들려면 콤마 + 소괄호!
print(myFavortieNumbers)sorted()
sorted()를 이용해서 tuple을 정렬할 수 있다.- tuple 자체가 바뀌는 것이 아닌, 새로운
리스트 자료형을 만드는 method이다.
score = 9.5, 8.9, 9.2, 9.8, 8.8, 9.0
print(type(score))
#출력값: <class 'tuple'>
scoreSorted = sorted(score)
print(type(scoreSorted))
#출력값: <class 'list'>
print(scoreSorted)
#출력값: [8.8, 8.9, 9.0, 9.2, 9.5, 9.8]Dictionary
key값과 각 key값에 대응하는value값이 있음key와value한 세트를 item 이라고 부름- Dictionary는
index가 없음! (index를 key가 대신함) key는 어떤 데이터를 구분하기 위한유일한 값이기 때문에 중복되면 안됨- 선언방법:
#중괄호로 선언, s1: key값, 홍길동: value값
students = {'s1':'홍길동', 's2': '박찬호', 's3': '이용규', 's4': '박승철'}
memInfo = {'이름': '홍길동',
'메일': 'gildong@gmail.com',
'학년': 3,
'취미': ['농구' ,'게임']}
key와value에는 숫자, 문자(열), 논리형 뿐만 아니라 컨테이너 자료형도 올 수 있다.- 단,
key에는 immutable 값만 올 수 있다. ex) list는 올 수 없음
dictionary 조회
1) dic_name[key] : value값 반환
- 없는 key값 입력 시, error 발생

2) dic_name.get(key): value 값 변환
- 없는 key값 입력 시에도, error가 발생하지 않음 > 'None'출력
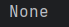
memInfo = {'이름': '홍길동',
'메일': 'gildong@gmail.com',
'학년': 3,
'취미': ['농구' ,'게임']}
print(memInfo['이름']) #출력값: 홍길동
print(memInfo.get('이름')) #출력값: 홍길동
print(memInfo.get('거주지')) #출력값: None
dic 추가
dic_name[key] = value형태로 item 추가 가능
myInfo = {}
myInfo['이름'] = 'gracie'
myInfo['전공'] = 'data science'
myInfo['나이'] = 26
myInfo['e-maeil'] = 'gracie@maeil.com'
myInfo['취미'] = ['맛집탐방', '요리', '여행', '책읽기']
print(myInfo)
#출력값: {'이름': 'gracie', '전공': 'data science', '나이': 26, 'e-maeil': 'gracie@maeil.com', '취미': ['맛집탐방', '요리', '여행', '책읽기']}
#이미 존재하는 key값에 value를 추가할 경우, value가 변경 됨
myInfo['취미'] = '드럼'
print(myInfo['취미']) #출력값: 드럼keys(), values(), items()
keys(): key값을dict_keys객체로 반환values(): value값을dict_values객체로 반환items(): item들을dict_items객체로 반환
dict_keys, dict_values, dict_items 모두 iterable 객체이다. (list로 자료구조 변경가능)
myInfo = {'이름': 'graice', '전공': 'data science', '나이': 26, 'e-mail': 'gracie@maei.com', '취미': ['책읽기', '수영']}
ks = myInfo.keys()
print(f'keys: {ks}')
print(type(ks))
vs = myInfo.values()
print(f'values: {vs}')
print(type(vs))
items = myInfo.items()
print(f'items: {items}')
print(type(items))- 출력값:

dic_items객체를list로 바꾸면, 리스트의 각items은tuple구조로 저장된다itemsList = list(items) print(itemsList) #출력값: [('이름', 'graice'), ('전공', 'data science'), ('나이', 26), ('e-mail', 'gracie@maei.com'), ('취미', ['책읽기', '수영'])] print(type(itemsList[0])) #출력값: <class 'tuple'>
item 삭제
1) del 키워드를 사용한 삭제
- del dic_name[key]
2)pop()method를 사용한 삭제 - dic_name.pop(key)
del vs pop() 차이점: pop()은 함수이기 때문에 삭제된 value를 반환 함
myInfo = {'이름': 'graice', '전공': 'data science', '나이': 26, 'e-mail': 'gracie@maei.com'}
print(myInfo)
#{'이름': 'graice', '전공': 'data science', '나이': 26, 'e-mail': 'gracie@maei.com'}
del myInfo['전공']
del myInfo['e-mail']
print(myInfo) #{'이름': 'graice', '나이': 26}
age = myInfo.pop('나이')
print(myInfo) #{'이름': 'graice'}
print(age) #26
dic의 in, not in 키워드
- key의 존재 유/무를 판단하는 키워드 (value 값은 판단 X)
len()
- item의 개수를 알아낼 수 있음
clear()
- 모든 아이템을 삭제할 수 있음
Set: 중복된 데이터를 허용하지 않음

비전공자의 Data Analyst 도전기 🥹✨