Programming Massively Parallel Programming -1
I. Introduction
CPU : Latency Oriented Design
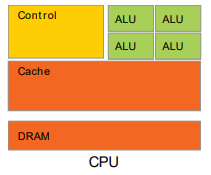
-
High Clock Frequency
-
Large Caches
- Convert long latency memory accesses to short latency cache accesses
- Sophisticated Control
- Branch prediction for reduced branch latency
- Data forwarding for reduced data latency
- Powerful ALU
- Reduced operation latency
GPU: Throughput Oriented Design
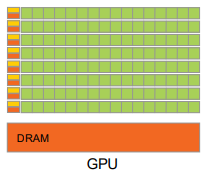
-
Moderate Clock Frequency
-
Small Caches
- To boost memory throughput
- Simple Control
- No branch prediction
- No data forwarding
- Energy Efficient ALUs
- Many, long latency but heavily pipelined for high throughput
- Require masive number of threads to tolerate latencies
Application Benefit
CPUs for sequential parts where latency matters
- CPUs can be 10+X faster than GPUs for sequential code
GPUs for parallel parts where throughput wins
- GPUs can be 10+X faster than CPUs for parallel code
Parallelism Scalability
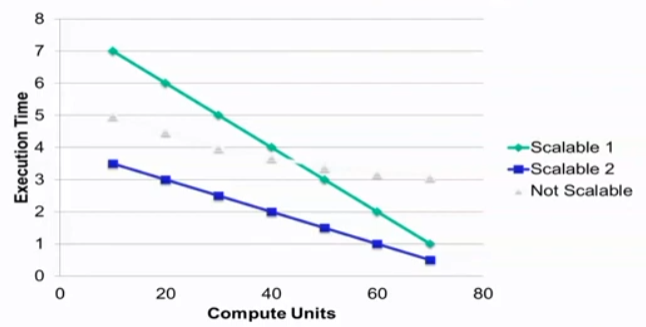
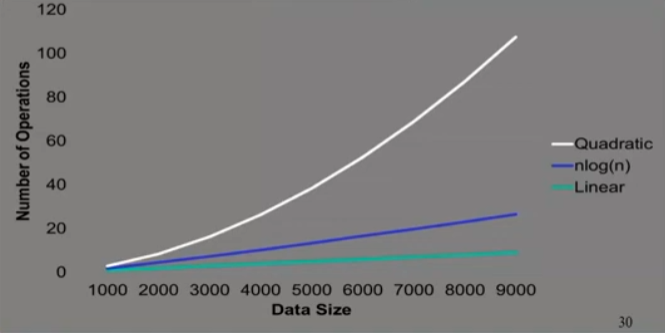
Algorithm Complexity and Data Scalability
Load Balance

The total amout of time to complete a parallel job is limited by the thread that takes the longest to finish
II. CUDA intro
Integrated host+device app C program
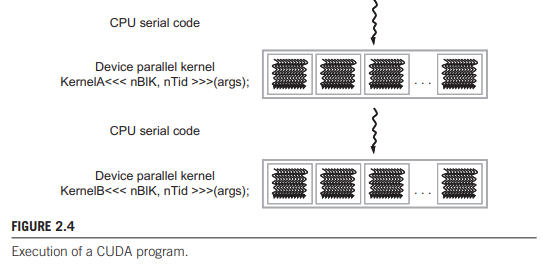
- Serial or modestly parallel parts in host C code
- Highly parallel parts in device SPMD 'kernel' C code
Threads
Array of Parallel Threads
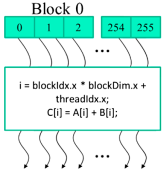
A CUDA kernel is executed by a grid(array) of threads
- All threads in a grid run the same kernel code (SPMD)
- Each thread has an index that it uses to compute memory addresses and make control decision
Thread Blocks: Scalable Cooperation
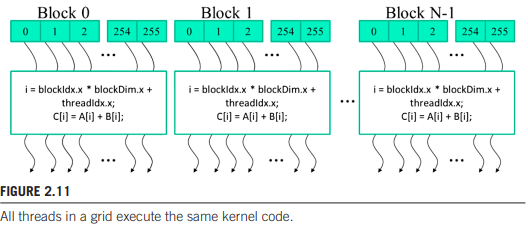
Divide thread array into multiple blocks
- Threads within a block cooperate via shared memory, atomic operations and barrier synchronization
- Threads in different blocks cooperate less
API Functions
CUDA Device Memory Management API Functions
cudaMalloc()
- Allocates object in the device global memory
- Two parameters
- Address of a pointer to the allocated object
- Size of allocated object in terms of bytes
cudaFree()
- Frees object from device global memory
- Pointer to freed object
Host-Device Data Transfer API functions
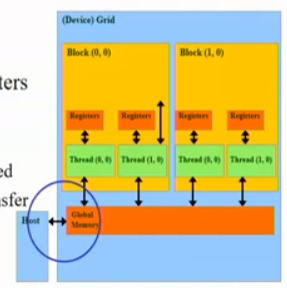
cudaMemcpy()
- Memory data transfer
- Requires four parameters
ο Pointer to destination
ο Pointer to source
ο Number of bytes copied
ο Type/Direction of transfer
vecAdd.function
#include <cuda.h>
void vecAdd(float* h_A, float* h_B, float* h_C, int n)
{
int size = n* sizeof(float);
float *d_A *d_B, *d_C;
// Allocate Device Memory for A,B and C
cudaMalloc((void **) &d_A, size);
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &d_B, size);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
cudaMalloc((void **) &d_C, size);
// Kernel invocation code
vecAddKernel<<<ceil(n/256.0), 256>>>(d_A, d_B, d_C, n);
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory for A, B, C
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);
}Kernel Function
// Compute vector sum C = A + B
// Each thread performs one pair-wise addition
__global__
void vecAddKernel(float* d_A, float* d_B, float* d_C)
{
int i= blockIdx.x * blockDim.x + threadIdx.x;
if(i<n) d_C[i] = d_A[i] + d_B[i];
}
CUDA C keywords
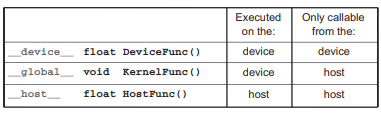
__global__ defines a kernel function
- Each '__' consists of two underscore characters
- A kernel function must return void
__device__ and __host__ can be used together
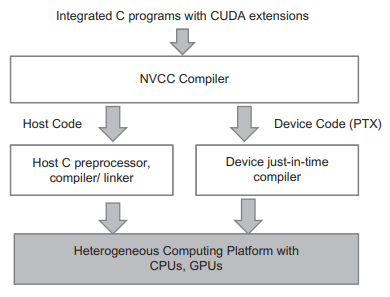
Compiling a CUDA Program

올해는 진짜 갓생 산다