
0. 서론
모던 데이터 엔지니어링에서 필수적인 기술 스택 중 하나는 바로 Workflow Orchestration이다. Apache Hadoop Ecosystem의 Oozie부터 AWS의 Step Functions, GCP의 Cloud Composer와 같은 클라우드 네이티브 서비스도 한 축을 차지하고 있으며, 더욱 더 모던한 기능들을 갖춘 Prefect 등 다양한 Workflow 플랫폼이나 어플리케이션이 시장에 퍼져있다. Apache Airflow는 최근 가장 많이 쓰이는 워크플로우 플랫폼으로, 오픈소스 재단인 Apache Foundation의 프로젝트로 공개되어 있다.
필자의 팀 역시 Apache Airflow로 ETL과 머신러닝 자동화가 구성되어 있는데, 어느날부터 평화로웠던(?) Airflow가 새로운 프로젝트들로 인해 수집, 프로파일과 모델 파이프라인들이 쏟아져나오며 비명을 지르기 시작했다. 갑작스럽게 병렬 처리되는 Task가 급격하게 증가하기 시작하여 스케쥴러의 대기열에 경합이 일어나기 시작했고, 이는 수행되어야 할 작업들을 오랜 시간 대기 상태에 빠트려 장애를 발생시키기 시작했다. 결과적으로 추천과 검색 서비스의 데이터 최신성에 지연을 가져오게 되었으며, 서비스에 영향을 미치는 사안인 만큼 긴급하게 해결할 이슈로 부상했다.
이 이슈의 해결 과정에서 Airflow에서 동시성(Concurrency)에 관여하는 옵션에 대해 알 수 있었다. 이 계기를 통해 알게 된 것들을 정리하고, 이어서 작성할 예제편을 통해 해당 옵션들이 어떻게 작동하는지 확인해 볼 것이다.
1. Airflow 동시성 제어 구조 개요
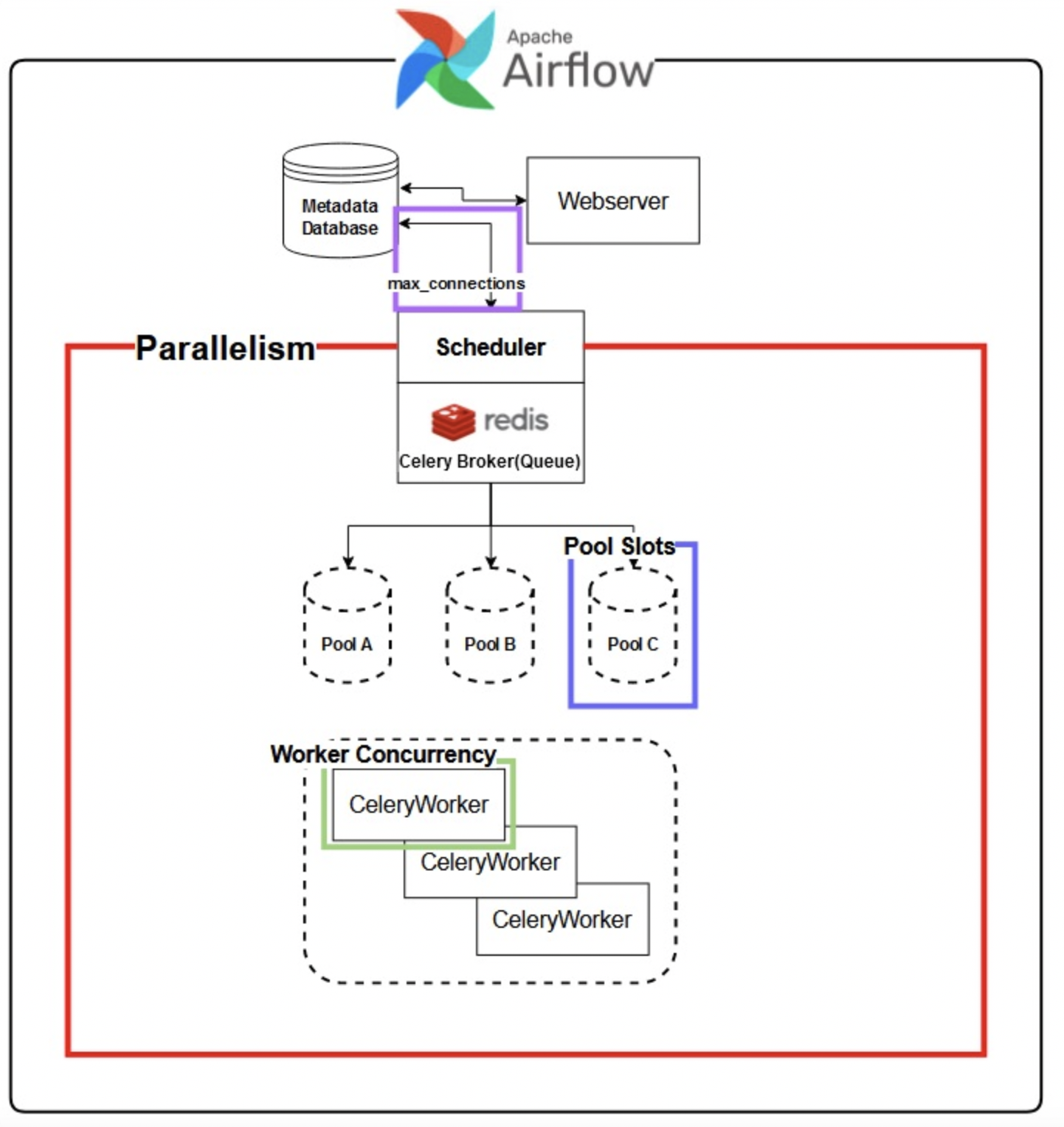
Airflow Cluster 내에서 동시성에 영향을 줄 수 있는 요소들은 크게 다음으로 나눌 수 있다.
- Scheduler 단계에서 설정 가능한 Parallelism과 Pools
- Celery Worker 사용시에 설정 가능한 Worker Concurrency
- Scheduler~Metadata Database 사이의 Connection 설정
2. 설정값 이해하기
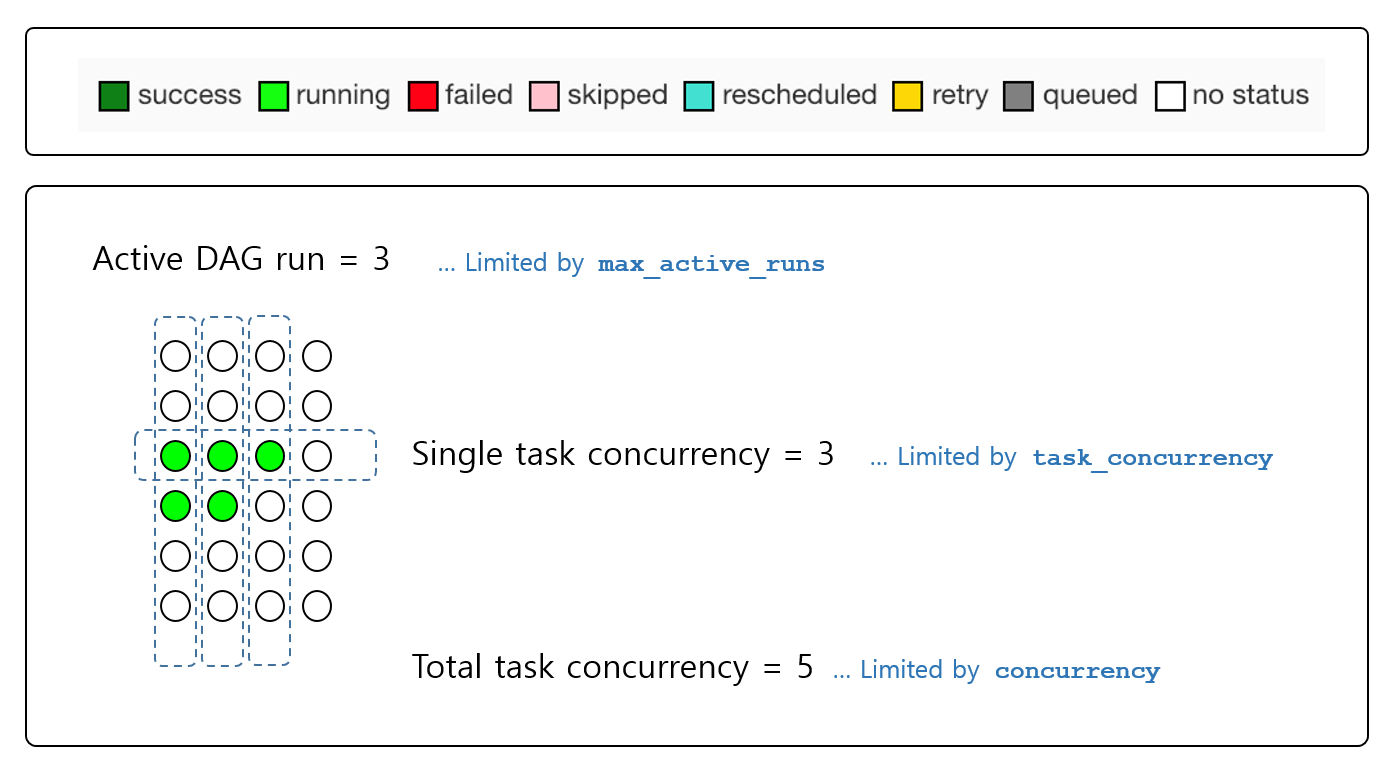
최근 버전의 경우 위 그림에서 설정값들이 이름이 변경되었으므로 참고!
max_active_runs->max_active_runs_per_dagtask_concurrency->max_active_tis_per_dagconcurrency->max_active_tasks_per_dag
2.1. Airflow configuration
core.parallelism(AIRFLOW__CORE__PARALLELISM)
Parallelism(병렬성)은, Scheduler별로 Worker 수와 관계 없이 Airflow Cluster 내에서 동시에 수행될 수 있는(= Runnning state에 진입할 수 있는) Task instance의 전체 갯수
기본 설정 값은32이며, 최상위의 설정값이므로 후술할 Pool이나 Worker Concurrency가 아무리 높은 값을 가지고 있더라도 동시 실행이 가능한 최대 Task 수는 반드시 이 값을 초과할 수 없다.2.3.3 버전 이전 문서에서는 Scheduler 당이 아닌 "Scheduler의 수와 상관없이(= 전체가 같은 값을 공유하는 뉘앙스)"로 표현되었으나 표현오류로 수정되었음 (링크)
-
core.max_active_tasks_per_dag(2.2.0 이전의dag_concurrency와 같음)
DAG 당 최대로 실행 가능한 Task 수 (1개의 DAG 내 모든 실행이 값을 공유) -
core.max_active_runs_per_dag(AIRFLOW__CORE__MAX_ACTIVE_RUNS_PER_DAG)
각 DAG 당 실행중인 최대 DAG Run의 수 -
celery.worker_concurrency(AIRFLOW__CELERY__WORKER_CONCURRENCY)
Celery Worker 사용 시, 각 Worker가 처리할 수 있는 최대 Task instance 수그러나
core.worker_autoscale옵션이 활성화될 경우 이 옵션은 적용되지 않음적용방법
-
$AIRFLOW_HOME/airflow.cfg >> 해당 옵션 값 변경 (공식 문서)
... [core] ... paralellism = 32 -
Airflow Scheduler 재시작
-
2.2. Pools
Pool은 Airflow에서 동시 실행을 제어하기 위한 실행 대기열의 개념이다. Parallelism은 Airflow 환경 내의 전체 Task 실행의 최대 수를 제한할 수 있는 Scheduler의 옵션이며, Configuration에서만 설정할 수 있기 때문에 Scheduler 내의 Configuration에 접근해야만 이 값을 변경할 수 있다.
하지만 pool은 Webserver GUI에서 설정과 관리가 가능하며, 여러 개의 pool을 정의하고, Task를 사용자 임의의 기준으로 분류하여 각 pool의 Slot(concurrency)을 제한하여 pool에 따라 개별적인 동시 실행을 제어할 수 있다.
이 Slot의 개념은 다른 동시성 관련 설정값과 다른 특징이 하나 있는데, 바로 각 Task가 가지는 slot 값은 사용자가 유동적으로 조절할 수 있다. Task의 경중에 상관없이 Concurrency에서는 1개의 task로써 동시성을 제어받게 된다.
예를 들어 Task A는 부하 1, Task B는 부하 3을 가지고 있다고 가정해보자. 각 Task의 20개가 동시에 수행될 경우 Server와 Worker에게는 차원이 다른 부하가 될 것이다. 이를 다른 동시성 설정으로는 통제할 수 없지만, Pool을 사용할 경우 slot 값을 부여하여 작업의 무게(Weight)를 반영한 동시성 제어를 수행할 수 있게 한다.
Airflow는 default_pool 이라는 기본 pool을 가지고 있으며, 기본 설정값은 128이다. 이 기본 값은 airflow.cfg의 core.default_pool_task_slot_count을 변경하여 조정할 수 있다.
적용 방법
- DAG 내 Task 정의 시
pool및pool_slots매개변수 삽입task_name = BashOperator( task_id="test_task", pool="pool_name", # Pool 이름 입력. 기본값은 "default_pool" pool_slots=2, # 해당 Task가 사용할 Slot 갯수. 기본값은 1 bash_command="sleep 10", dag=dag, )
주의사항
default_pool은 삭제 불가능- 1개의 Task는 1개의 Pool에만 등록 가능
- SubDAG을 사용할 경우 SubDAG 안의 Task들에만 Pool 적용 가능.
SubDAGOperator자체는 Pool에 등록되지 않음 - 잘못된 Pool 이름 입력 시 Task가 작동하지 않으므로 오타로 인해 작동불능이 되지 않도록 주의할 것
2.3. Operator Weight Rule
만약 여러개의 DAG가 실행중이며, 수많은 Task가 당신의 Workflow에 몰려들고 있다면, 어떤 Task를 먼저 실행시킬 것인가? Airflow는 이를 Priority Weights라는 개념을 통해 Task의 우선도를 결정하고 실행 순서를 지정한다.
Priority Weights는 Executor 내 Queue에서 실행 순서를 지정하는데 사용하는 정수값이다. Priority Weights를 산정하는 방법인 weight_rule은 BaseOperator 객체 내의 인수에 의해 정의되어 모든 Operator에 상속된다.
Weight rule은 airflow.utils.WeightRule에 정의되어 있으며 다음과 같이 3가지가 존재한다.
UPSTREAM: 처음 실행되는 Task부터 낮은 값을 가지며, 마지막에 가까운 Task일수록 높은 값을 가진다.DOWNSTREAM:BaseOperator의 기본 값. 선순위 Task부터 높은 값을 가지며, 후순위 Task는 낮은 값을 가진다(내림차순)ABSOLUTE: 모든 Task가 동일한 실행 우선순위를 가진다.
기본값인 DOWNSTREAM의 경우 DAG 앞에서 실행되는 Task는 높은 실행 우선순위를 갖게 되는 반면, 뒤쪽에서 실행되는 Task는 낮은 실행 순위를 가지게 되어 전반적인 DAG 실행시간이 길어질 수 있어 DAG의 동시성에 영향을 줄 수 있다.
적용방법
$AIRFLOW_HOME/models/baseoperator.py또는 각 Operator의 Class 내 매개변수 수정class BaseOperator: def __init__(self, ...): ... weight_rule=WeightRule.DOWNSTREAM # UPSTREAM 또는 ABSOLUTE ...
주의사항
- Priority Weight의 기본 값은 1
참고자료
- Apache Airflow Documentation
- Astronomer - https://docs.astronomer.io/learn
- 쏘카 데이터 그룹 - https://tech.socarcorp.kr/data/2021/06/01/data-engineering-with-airflow.html
- LINE ENGINEERING - https://engineering.linecorp.com/ko/blog/data-engineering-with-airflow-k8s-1/
