- 출처: 그림으로 공부하는 오라클 구조
- 데이터를 꺼내고 집어넣을 때, 어떤 식으로 데이터가 보관되는 것이 유리할지 알아보자.
- 테이블 스페이스, 세그먼트, 익스텐트, 블록처럼 용어로 표현하면 어려운 개념들을 그림으로 살펴볼 것.
왜 배워야 하는가?
-
애플리케이션 개발 팀에서도 테이블이나, 인덱스의 생성과 생성 요청을 해야 하므로 어느 정도의 지식은 필요하다.
- 성능과 관련된 부분에서도 데이터 구조와 관련된 지식은 필요하다.
- 성능과 관련된 부분에서도 데이터 구조와 관련된 지식은 필요하다.
-
일반적인 운영에서 발생할 수 있는 에러의 대응에서도, 이런 용어들을 많이 사용하므로 데이터 구조는 반드시 이해해 두어야 한다.
-
오라클은 데이터를 관리하는 시스템이므로, 데이터를 어떻게 저장하고 있는지를 이해하는 것은 오라클을 알기 위해 절대 빼놓을 수 없는 부분이다.
💻💫 데이터 구조는 복잡하므로 어렵다고 느낄 수도 있지만, 이해할 때까지 몇 번이든 반복해서 학습하라!
- 테이블스페이스 (tablespace)
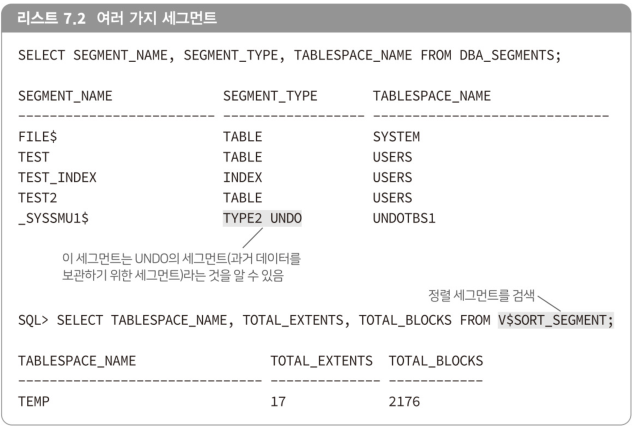
- 세그먼트(segment)
- 익스텐트(extent)
- 블록(block)
- 데이터 파일(datafile)
가변 길이 데이터를 관리할 프로그램을 만들기 위해서는?
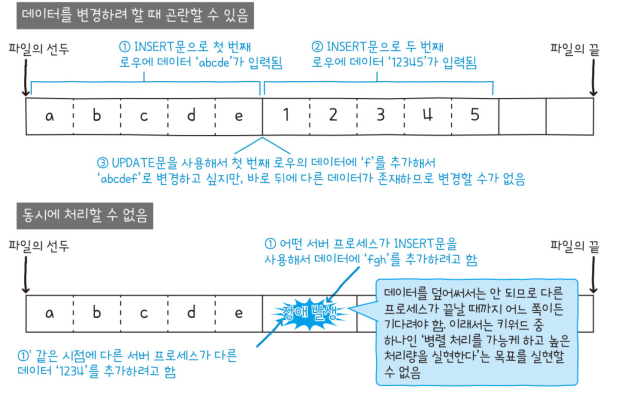
- 데이터를 변경하려 할 때 곤란할 수 있음
- 동시에 처리할 수 없음
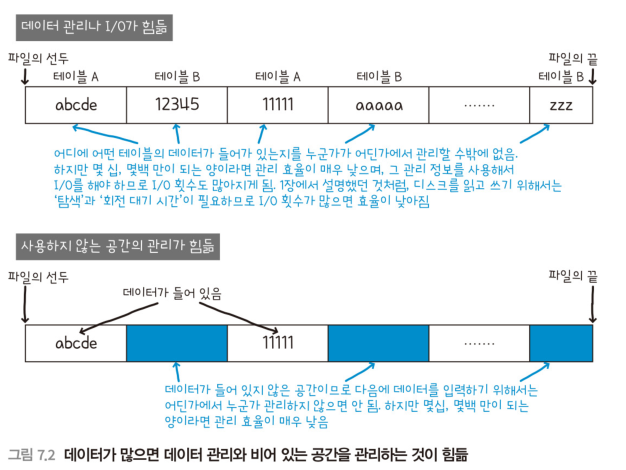
- 데이터가 많으면 데이터 관리나 I/O가 힘듦
- 사용하지 않는 공간의 관리가 힘듦
필요한 데이터 구조
적당한 크기로 정한다(뭉친다)
- 관리를
어디서부터 어느 정도의 크기가 어던 테이블의 데이터인가?라는 방식으로 하면,관리 정보의 수를 줄일 수 있다.
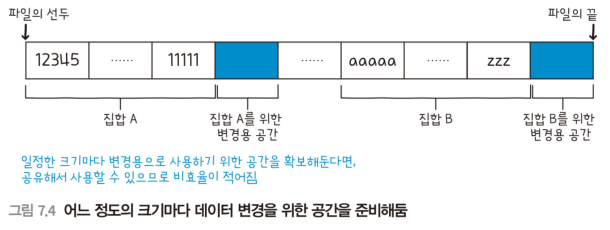
- 일정한 크기마다 변경용으로 사용하기 위한 공간을 확보해둔다면, 공유해서 사용할 수 있으므로 비효율이 적어진다.
세 가지를 구현할 수 있는 구조가 필요하다.
1. 관리 및 I/O의 효율을 고려해 공간을 어느 정도의 크기로 뭉쳐서 할당한다.
2. 데이터 변경에 필요한 공간을 확보한다.
3. 비어 있는 공간을 관리한다.
오라클의 데이터 구조
- 물리 구조
- 데이터 파일 등의 OS에서 보이는 구조
- 논리 구조
- OS에서는 식별할 수 없는 오라클 내부의 구조를 의미
- ex) 데이터 파일 안에 보관된 '테이블'이나 '로우(행)'
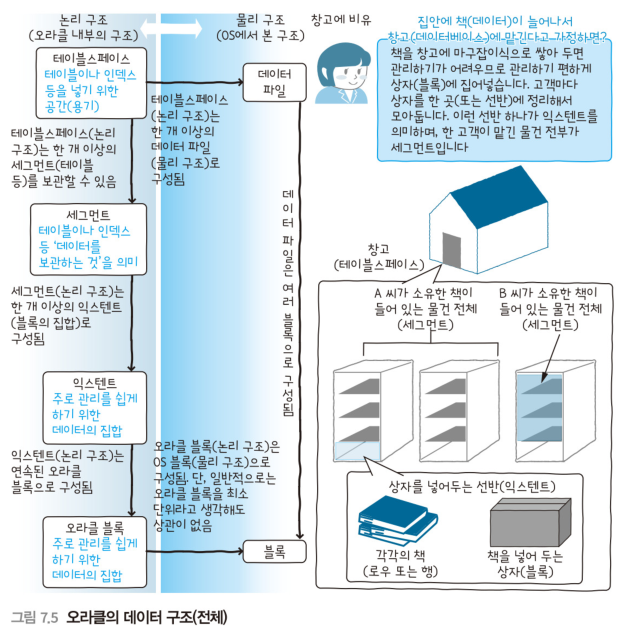
데이터 파일과 테이블의 관계
-
데이터 파일: OS에서 보이는 물리구조
-
테이블: 여러 개의 로우를 갖고, OS에서 보이지 않는다는 의미로 논리적인 구조이다.
-
가장 작은 구조(집합): 오라클 블록이다.
블록: 8KB 같은 크기로 나누니 공간을 말한다.
- 블록 안에, 한 건 이상의 데이터가 보관된다.
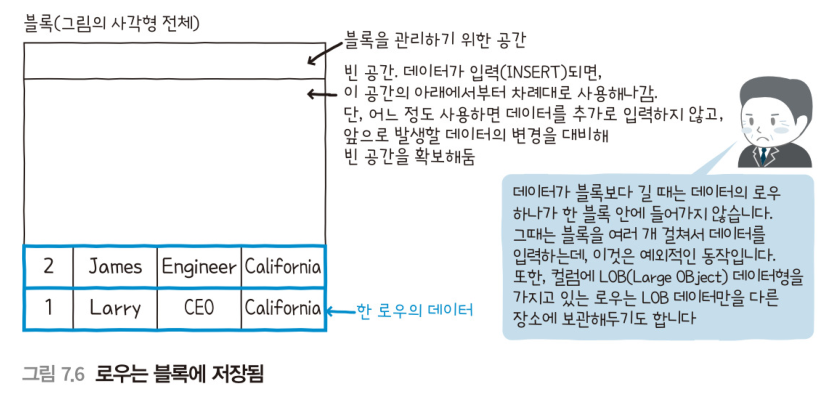
익스텐트
테이블은 여러 개의 블록으로 구성된 것일까?

-
익스텐트라는 구조를 도입
- 연속된 블록의 집합
- 각 블록의 위치가 아니라,
각 익스텐트의 첫 위치와 블록의 개수만으로 데이터를 관리할 수 있다.
-
관리 정보도 줄일 수 있게 됨.
-
데이터를 한 번에 읽어올 수 있으므로, 테이블의 풀 스캔 성능을 향상할 수도 있다.
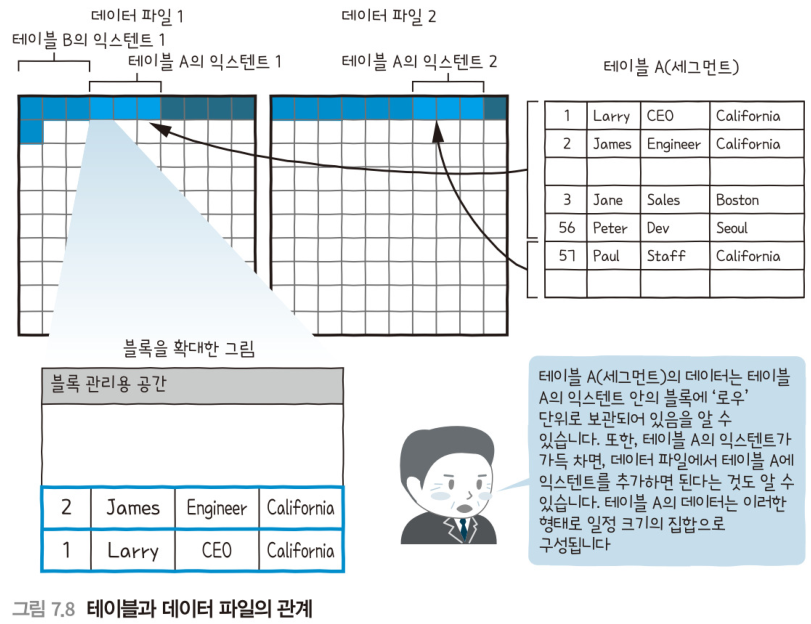
세그먼트
-
테이블이나 인덱스 등의 데이터를 한 번 더 모은 익스텐트의 집합을 '세그먼트'라고 부른다.
- 세그먼트는
많은 데이터를 보관하기 위한 구조- 구조: 데이터베이스 내에 존재하고 있는 것처럼 보이기 때문이다.
- 세그먼트: 익스텐트의 집합
- 세그먼트는
-
사용자용 세그먼트: 테이블, 인덱스 외
-
오라클이 자동으로 생성하는 세그먼트도 있다.
- 데이터를 정렬하기 위한 세그먼트
- UNDO라고 불리는 과거 데이터를 보관하는 세그먼트 등
테이블 스페이스
- 오라클 내부의 구조
테이블스페이스라고 부르긴 하지만,세그먼트를 분류해서 보관하기 위한 상자라고 생각하면 된다.- 테이블 스페이스는 한 개 이상의 데이터 파일로 구성돼있다.
- 오라클이 데이터베이스를 관리하기 위해 사용하는 테이블스페이스와,
- 사용자(여러분)가 사용하는 테이블 스페이스 등
- 몇 가지 종류가 있다.

- 테이블스페이스의 집합(물리적으로는 데이터 파일의 집합)
- REDO로그 파일
- 컨트롤 파일이 모이면 하나의 데이터베이스가 된다.
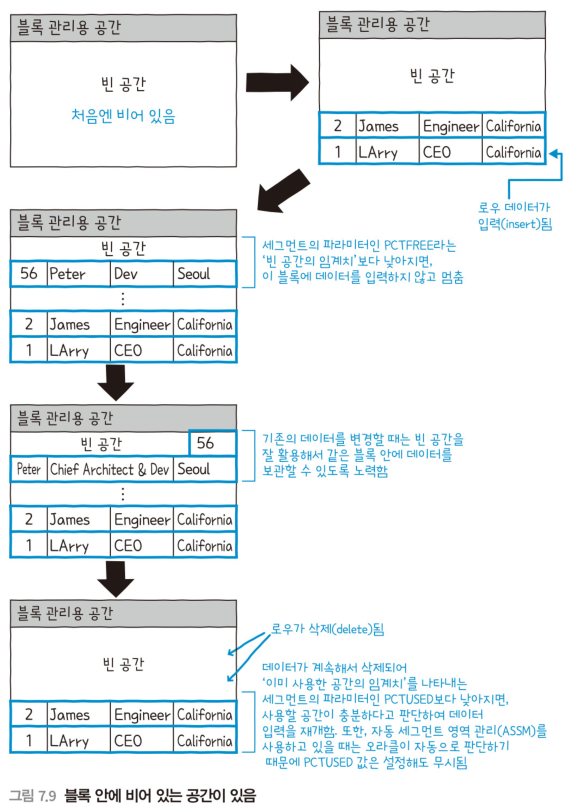
블록 안의 공간
- 오라클은 블록 안에 데이터 변경에 대비한 공간을 남겨둔다.
- 데이터를 입력할 때 가득 채워넣는 것이 아니라, 어느 정도의 공간을 남겨두는 것이다.
데이터가 계속 삭제되어 블록 안의 공간이 늘어나면, 다시 해당 블록으로 데이터를 입력한다.
- 데이터를 입력할 때 가득 채워넣는 것이 아니라, 어느 정도의 공간을 남겨두는 것이다.
- 어떤 블록에 공간이 남아있는지(데이터를 입력할 수 있는가?)를 빠르게 파악하기 위해서, 빈 블록을 세그먼트 단위로 관리하고 있다.
- 세그먼트 안에 공간이 모자란 상황이 오면, 세그먼트에 새로운 익스텐트를 추가하고 빈 블록을 늘린다.
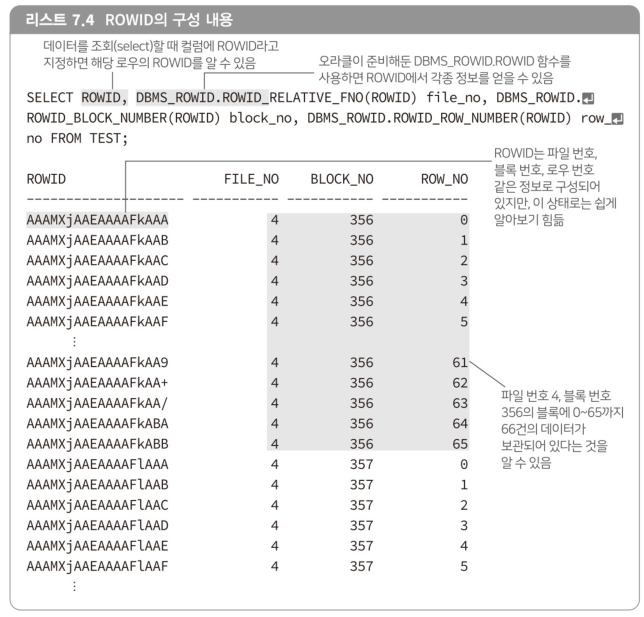
ROWID
- 오라클에서는, 데이터 로우의 주소를
ROWID라고 부른다. - 데이터 파일의 번호나 데이터 파일 안의 블록 번호,
- 블록 안에 로우 번호와 같은 정보로 구성되어 있다.
실제 흐름을 따라 각 동작을 확인
공간 할당하기 및 비어있는 공간의 관리
1. 데이터베이스의 생성
- SYSTEM 테이블스페이스를 시작으로, 몇 가지 테이블스페이스가 생성된다.

2. 사용자용 테이블스페이스의 생성

- 사용자용 테이블스페이스를 생성한다.
- 데이터베이스를 생성할 때 같이 해도 상관 없다.
- 이 시점에서, 테이블스페이스는 비어있는 공간을 갖게 된다는 점에 유의하자.
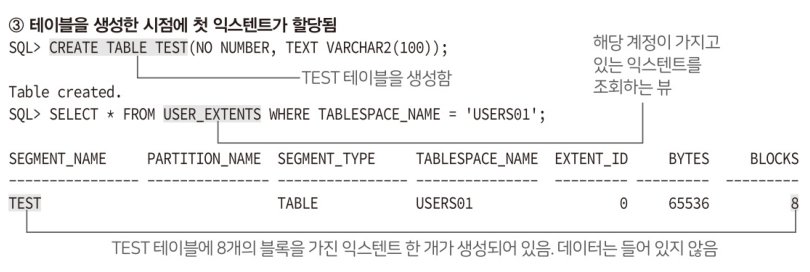
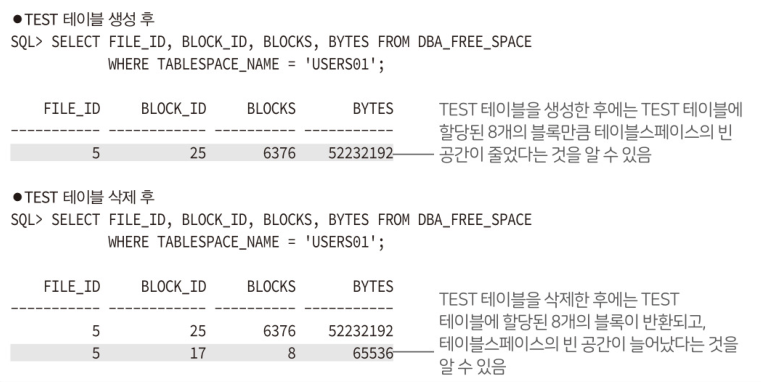
3. 테이블을 테이블 스페이스에 생성
-
테이블스페이스에 테이블을 생성한다.
-
이 시점에서 내부가 비어있는 상태로 익스텐트가 생성된다.
- 익스텐트가 생성된 후, 데이터 입력(insert)가 수행
- 익스텐트의 비어있는 블록에 데이터를 입력한다.
PCTFREE라는 임계치에 도달하면, 해당 블록에 입력하는 것을 멈추고,이 블록에는 공간이 없다고 인식한다.
-
그리고 그 다음으로 비어있는 블록에 데이터를 입력한다.
-
데이터의 입력이 계속되어, 익스텐트가 가득 차게 되면, 테이블스페이스가 가지고 있는 빈 공간을 사용해 새로운 익스텐트를 테이블에 할당하고, 데이터를 입력할 수 있게 한다.
-
그 후 데이터를 삭제하여
PCTUSED라는 임계치(ASSM일 때는 오라클이 자동으로 계산)보다 낮아지면, 다시이 블록은 비어있다고 인식하게 된다. -
테이블이나 인덱스가 DROP(또는 TRUNCATE)되면, 익스텐트 안의 데이터는 불필요하므로, 테이블스페이스의 빈 공간으로 돌아간다.

프로세스에서 본 데이터 구조
- 오라클의 메모리 내부(특히 캐시)에서는 대부분의 데이터를 블록(오라클 블록)이라는 단위로 관리한다.
- 메모리 내부의 동작에 대해 검색(SELECT)와 변경(UPDATE)을 예로 들어 설명.
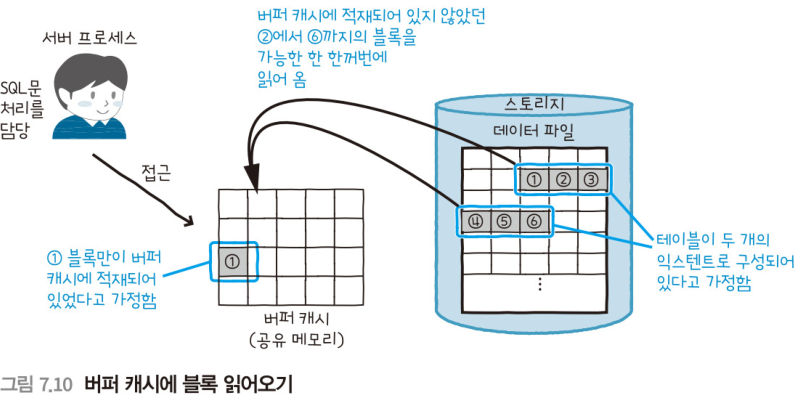
- 검색: 풀스캔이라고 가정
- 테이블의 전체 데이터를 읽어올 필요가 있다.
- 검색: 풀스캔이라고 가정
- 오라클은 해당 테이블의 익스텐트를 조사하고, 버퍼 캐시에 존재하지 않는 블록을 처음부터 읽어온다.
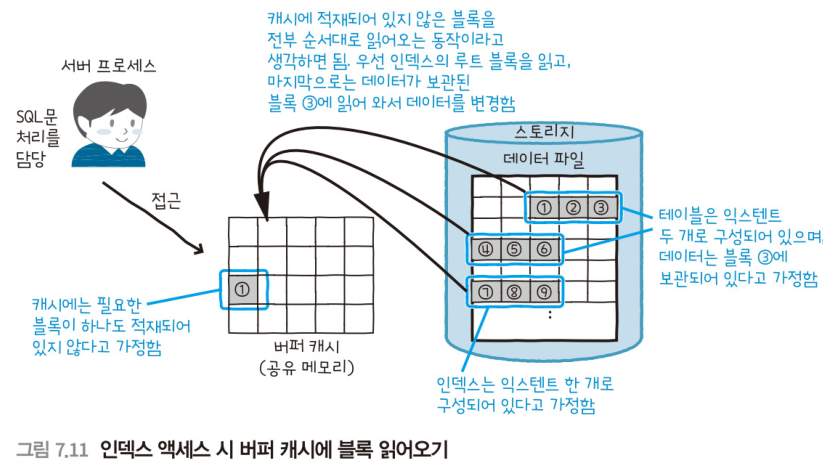
데이터의 변경
-
데이터의 변경은 인덱스를 사용해 한 건만을 변경한다고 가정
-
우선 인덱스에 접근하고, 인덱스의 관리 정보를 토대로 인덱스의 루트 블록(가장 위의 블록)을 찾아간다.
-
캐시에 없으면, 블록을 읽어온다.
-
이어서 루트 블록에서 다음 블록의 주소를 조사하고, 그 블록이 캐시에 적재되어 있지 않다면 디스크에서 읽어온다.
- 반복해서 필요한 데이터의 ROWID를 확인하고, 해당되는 데이터 블록을 찾는다.
-
대상 테이블 데이터의 블록이 캐시에 적재되어 있지 않다면, 해당 블록만을 읽어온다.
-
그리고, 캐시 상에서 블록의 데이터를 변경한다.
- 지금까지 설명한 처리는 서버 프로세스가 수행한다.
- 그런 후, DBWR(Database WRiter)라 불리는 백그라운드 프로세스가 잠시 후 데이터 파일에 변경된 데이터를 기록한다.
- 캐시의 데이터와, 파일의 데이터가 일치하지 않는 시간이 존재한다.
- 응답 시간을 중시한다.
- 데이터를 변경할 때마다, 일일이 기록한다면 그만큼 사용자가 느끼는 응답 시간은 나빠질 것이기 때문이다.
- 데이터의 보증은 REDO 로그라고 불리는 별도의 장치를 통해 지켜지고 있다.
요약
-
테이블스페이스는 세그먼트를 집어넣기 위한 용기로서 하나 이상의 데이터 파일로 구성된다.
-
일반적으로 테이블이나 인덱스는 세그먼트다.
-
세그먼트는 익스텐트로 구성되며, 익스텐트는 연속된 블록으로 구성되어 있다.
-
세그먼트는 테이블스페이스 여러 개에 걸쳐서 존재할 수 없다. (세그먼트는 테이블 스페이스에 소속되므로)
-
익스텐트는 데이터 파일 여러 개에 걸쳐 존재할 수 없다. (익스텐트는 연속된 블록이므로)
-
일반적으로 테이블이나 인덱스는 테이블스페이스가 가지고 있는 공간에서 새로운 익스텐트를 할당받음으로써 크기가 커진다.
-
블록 안의 데이터 변경용 공간은 PCTFREE라는 파라미터로 제어한다.
-
로우(행)은 블록에 보관되어 있다.
테이블스페이스가 가득 차면 어떻게 되지?
-
본문에서도 설명했듯, 익스텐트가 가득 차면 테이블스페이스가 가진 공간에서 세그먼트에 새로운 익스텐트를 할당한다.
- 할당할 공간이 없으면?
-
이때는 익스텐트를 할당하지 못하며 에러가 발생한다.
- 운영 환경에서 테이블스페이스가 가진 여유 공간을 모니터링하는 것은 매우 중요한 작업이다.
-
여유 공간이 부족할 때에는 데이터파일을 추가하여 대처한다.
-
단, 데이터 파일을 자동 확장할 수 있도록 설정했다면, 상한선(ex: OS 파일의 크기 상한이나, 한 개의 데이터 파일에 넣을 수 있는 블록 수의 상한 등)에 도달하지 않은 이상, 자동으로 공간을 확장하기 때문에 공간이 부족하다고 해서 너무 서둘러 대응할 필요는 없다.
-
단, 파일 시스템의 여유 공간을 모니터링할 필요가 있으며, 큰 데이터 파일은 문제가 발생할 여지가 있으므로 너무 크게 할당하지 않는 편이 좋다.
-
이런 이유 때문에 관리용으로 사용하는 테이블스페이스(SYSTEM 테이블스페이스)에는 사용자용의 세그먼트를 생성해서는 안 된다.
-
잘못해서 SYSTEM 테이블스페이스가 가득 차게 되면, 데이터베이스 전체에 영향을 줄 수 있다.