2-1 데이터 모델, 계층형, 네트워크형, 관계형
- 다양한 데이터 저장 형식
1. 데이터 모델의 종류
- 데이터 모델: 데이터베이스에는 일정한 규칙을 따라 데이터가 저장되어 있다. 데이터의 구조를 말하며 여러 종류가 있다.
1) 계층(hierarchy)형
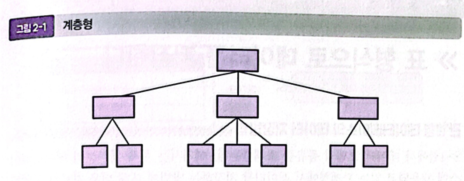
- 회사 조직도와 비슷하다.
- 데이터 검색이 빠르지만, 만약 여러 곳에 속한다면 데이터가 중복되는 단점
2) 네트워크(Network)형
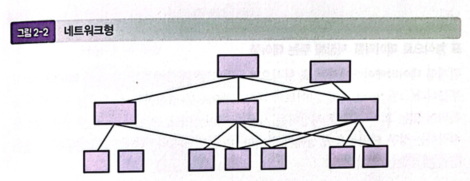
- 데이터를 그물코 모양으로 나타내는 모델.
- 데이터의 중복을 피할 수는 있지만, 현재는 편리성이 보다 높은 관계형이 주류
3) 관계(Relational)형
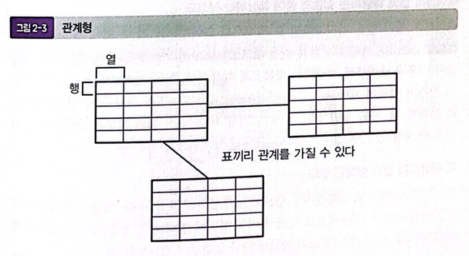
- 행과 열을 가진 2차원 표에 데이터를 저장하는 모델
- 여러 가지 표를 조합하여 다양한 데이터에 유연하게 대응할 수 있다는 특징
- 대표적인 데이터베이스 관리 시스템(DBMS)
2-2 테이블, 컬럼, 레코드, 필드
- 표 형식으로 데이터를 저장한다
- 테이블

- 관계형 데이터베이스에서는 표 형식으로 데이터를 저장
- 저장하는 데이터의 종류별로 테이블을 생성
- 테이블은 행과 열을 가진 2차원 표 형식으로 되어있음
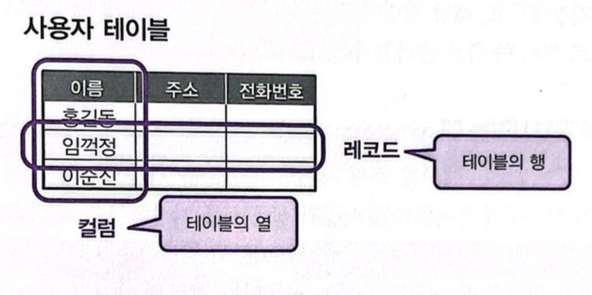
-
열 -> 컬럼(Column) / 행-> 레코드(Record)
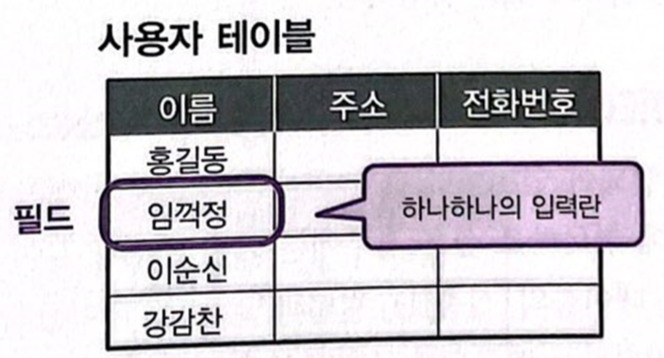
-
각 레코드의 각각의 입력 항목을 필드라고 부른다.
2-3 테이블 결합
-
표끼리 조합하다
1. 테이블 결합이란?
-
테이블 결합 : 관계형 데이터베이스에서는 복수의 관련된 테이블끼리 조합하여 데이터를 취득하는 방법
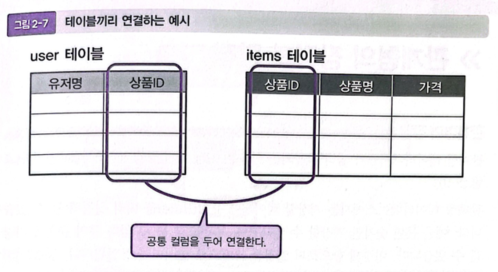
- 테이블 결합을 하기 위해서는
관련된 2개의 테이블에 미리 테이블 간에 연결을 하기 위한 키(Key) 역할을 하는 컬럼을 지정해두고, 해당 컬럼에 저장된 값이 일치하는 2개 테이블의 레코드들을 쌍(Pair)으로 해서 한 줄로 출력할 수 있다.
2. 테이블끼리 결부시키는 예
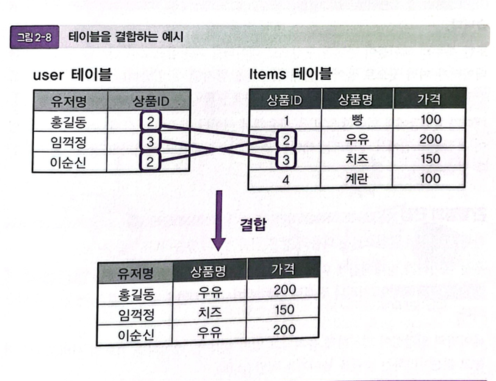
-
① users 테이블, items 테이블을 서로 연결하기 위해서, 상품ID라고 하는 공통되는 컬럼을 가지고 있다.
-
② users 테이블에서는 사용자가 구입한 상품ID를 확인할 수 있으므로,
- 해당 상품에 대한 자세한 정보를 보고 싶은 경우에는 items 테이블의 상품 id 컬럼 값에 일치하는 레코드를 조회할 필요가 있다.
-
2개의 테이블은 독립되어 있는데, 상품을 구매한 사용자의 이름과 구입한 상품의 이름, 가격을 한꺼번에 취득하고 싶은 경우에는 테이블을 결합한다.
2-4 갱신비용, 지연, 분산
- 관계형의 장점과 단점
1. 관계형의 장점
- 갱신비용 최소화
- 데이터의 포맷 통일
- 정확한 데이터 취득
-> 데이터가 깨끗이 정돈된 상태를 유지할 수 있다.
-
저장할 데이터에 규칙(Rule)을 미리 설정해둘 수 있다.
- ex) 숫자만 저장, not null 등
-
규격 이외의 데이터가 등록되려고 하면
처리 전의 상태로 안전하게 되돌리는 구조도 갖춰져 있다. -
복수의 테이블이 관련된 구성으로 데이터를 저장함으로써 설계를 통해 동일한 데이터가 여러 곳으로 흩어져 존재하는 것을 방지.
- 데이터를 갱신할 때는 1곳만 수정하면 되므로 갱신 비용을 줄일 수 있다.
-
SQL을 사용해서 데이터 등록이나 삭제, 조회를 할 수 있어 복잡한 조건에서 수행되는 데이터 검색이나 집계라고 하더라도 정확하게 조회할 수 있다.
2. 관계형의 단점
- 처리 속도가 늦다
- 데이터를 분산할 수 없다
- 표현하기 어려운 데이터도 있다
-
데이터가 방대해짐에 따라 처리하는 속도가 느려진다.
-
복잡한 처리나 집계로 인한 커다란 지연을 유발한다.
-
데이터의 일관성이 철저하게 유지되고 있기 때문에, 데이터를 별도의 서버로 나누어 놓고 분산처리하는 능력을 높이기엔 어려움
-
그래프 형태의 데이터, XML이나 JSON으로 불리는 비구조화된 데이터 등 계층적이고 자유도가 높은 데이터를 표현하는 것도 어려움.
2-5 NoSQL
- 관계형 이외의 형식
1. NoSQL 이란?
- Not Only SQL : 관계형 이외의 데이터베이스 관리 시스템을 가리키는 말
- ex) MongoDB, Redis 등
| 관계형 DB | NoSQL |
|---|---|
| 저장되어 있는 데이터를 엄격하게 관리 | 데이터의 정합성보다는 |
| 일관성 및 정합성 유지 | 대량의 데이터를 빠르게 처리하는 것이 우선 |
| 처리 성능 낮음 | |
| 대용량 데이터에 대한 퍼포먼스(성능) 측면에서 문제 |
이용되는 사례
- 대규모 데이터 분석
- 실시간 처리가 요구되는 게임
- Rich Web 콘텐츠
Rich Web
- 웹 기술을 이용하여 보다 고차원적인 사용자 인터페이스를 제공하면서, 원격 또는 로컬의 웹 애플리케이션과 서로 다른 웹 플랫폼 간의 응용, 서비스, 데이터를 연계하며 구동될 수 있게 하는 표준기술
2. NoSQL의 특징
강점
- 처리 신속, 많은 양의 데이터를 다룰 수 있다.
- 다양한 구조의 데이터를 저장
- 데이터를 분산해서 처리하는 것이 가능
약점
- 관계형인 데이터끼리 결합이 지원되지 않는다
- 데이터의 일관성이나 정합성을 유지하는 기능은 약하다
- 트랜잭션은 사용할 수 없는 경우가 많다
다양한 대용량 데이터를 고속으로 처리할 수 있기 때문에, 데이터 해석이나 실시간(Realtime) 처리가 요구되는 콘텐츠에 활용되고 있다.
2-6 키 밸류형, 컬럼 지향형
NoSQL 데이터베이스 종류 ①
- 키와 밸류를 조합한 모델
1. 키 밸류형
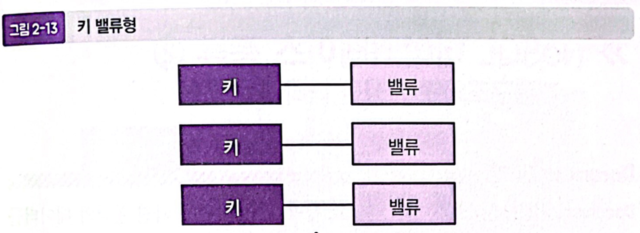
-
키(Key)와 밸류(Value) 2개의 데이터를 쌍으로 묶은 것을 저장할 수 있는 모델
-
밸류에는 기록하고 싶은 정보, 키에는 그 정보를 식별하는 값을 저장
-
ex) 접속 이력, 쇼핑 카트, 페이지 캐시(Page Cache) 등
- 메인이 되는 값과 그것을 식별하기 위한 두 개의 값으로 이루어진 정보를 계속해서 저장할 수 있고, 키를 기반으로 정보를 빠르게 끄집어내고 싶을 때 가장 적합한 모델이다.
- 간단한 구성으로 고속으로 읽고 쓸 수 있으며, 나중에 정보를 분산하기 쉬운 것이 특징이다.
2. 컬럼 지향형
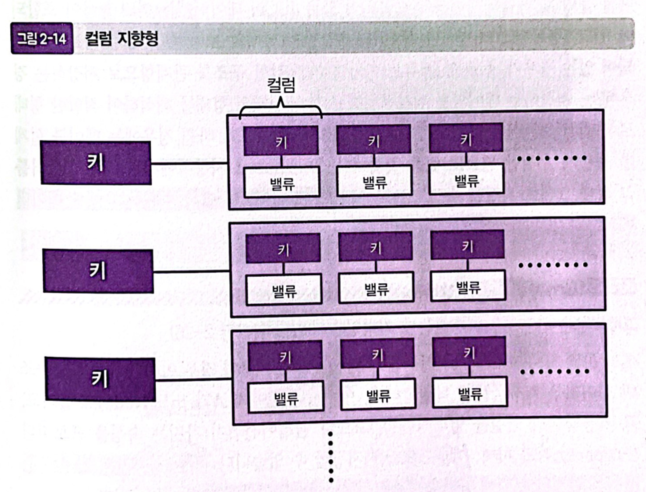
-
하나의 행을 식별하는 키에 대해
여러 개의 키와 벨류 세트를 가질 수 있도록 되어 있는 모델 -
한 행에 여러 개의 열(컬럼)이 있는 구조이므로 관계형과 비슷,
-
열의 이름이나 개수가 고정되어 있는 것이 아니라, 행마다 나중에 열을 동적으로 추가할 수 있고 다른 행에 존재하지 않는 열도 생성 가능
- 행마다 형태가 정해지지 않은 데이터를 저장하는 것이 가능
- ex) 각 사용자가 할당된 행에, 나중에 열을 추가하고, 새로운 정보를 차례차례로 더해가는 식으로 사용하는 방법
2-7 Document 지향형, 그래프형
NoSQL 데이터베이스 종류 ②
- 계층구조와 관계성을 나타내는 모델
1. Document 지향형
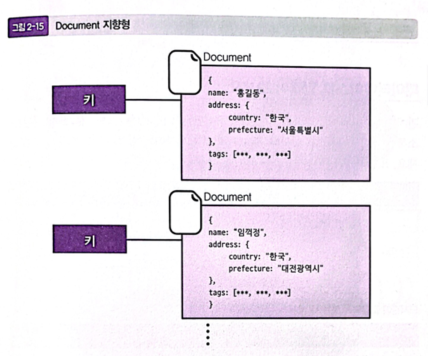
-
JSON이나 XML로 불리는 계층 구조를 가진 형식의 데이터를 저장할 수 있는 모델이다. (ex: MongoDB)
-
미리 테이블 구조를 정해 둘 필요가 없고 자유로운 구조의 데이터를 그대로 가져올 수 있다는 장점
-
Document 지향형에서는 받은 데이터를 상태 그대로 저장할 수 있기 때문에,
나중에 데이터 구조가 바뀐 경우에도 데이터베이스의 설계를 바꿀 필요가 없다.
- ex) 웹 애플리케이션에 보급되어 있는 JSON 데이터에는 여러 항목이 포함되어 있고, 항목별로 배열이나 해쉬(Hash) 같은 형태의 보다 깊은 계층 구조 형태로 되어 있는 경우가 종종 있다.
- 이와 같이 복잡한 구조를 관계형으로 저장하는 경우에는, 저장하는 데이터를 취사선택하고 각 데이터의 형태를 해석하여 적합한 형태로 바꿔서 보존해야 한다.
- 또한, 중간에 데이터 구조가 바뀐 경우에는 테이블 설계를 새롭게 수정할 필요도 있다.
그래프(Graph)형
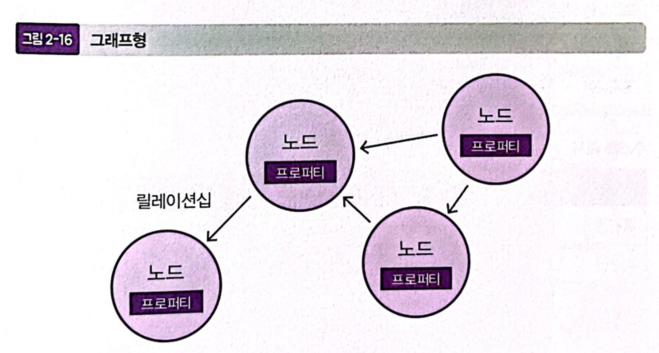
-
관계성을 표현하는 데 최적인 모델
-
어떤 사용자의 친구의 친구라는 관계를 둘러싼 검색을 고속으로 실시할 수 있다는 장점이 있다. -
각 사용자의 연결로부터 흥미가 있는 것을 분석함으로써 쇼핑 사이트의 추천 시스템이나 지도 앱에서 가장 효율적인 경로 탐색에 응용하는 등의 용도를 생각할 수 있다.
- ex) 사용자 A와 B가 친구인데, B는 C, D와 친구인 경우 이러한 네트워크 구조의 데이터를 저장하는데 탁월하다.
- 사용자 A가 노드(Node)로 불리고, 각 사용자끼리 연결을 릴레이션십이 가지는 속성을 프로퍼티(Property)라고 하며, 이들 3요소를 저장할 수 있다.