리두 로그 버퍼 (SGA 메모리 공간)
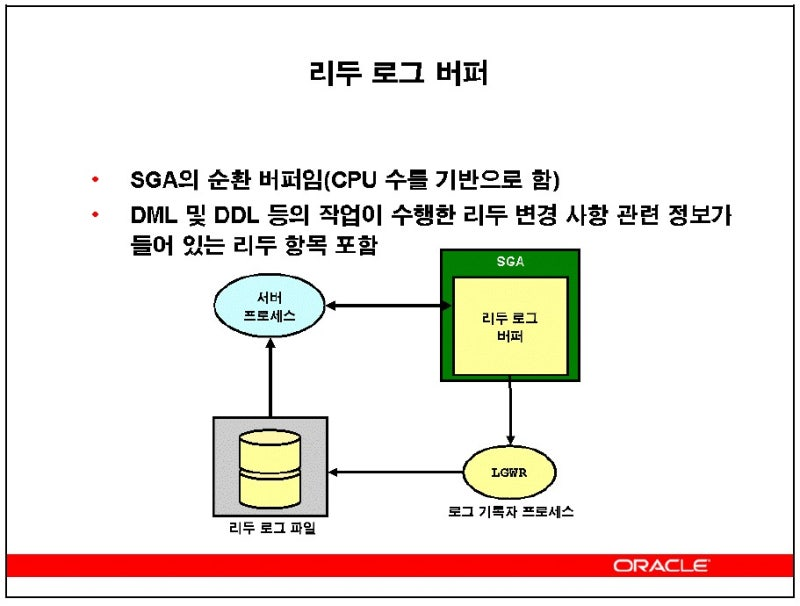
- log_buffer, show sga; --> Redo Buffers가 리두로그 버퍼 크기
- 해당 작업의 리두로그 버퍼 내용을 리두 로그 파일에 기록
순서
1. 데이터 블록 변경 제한
2. 리두 로그 생성
- DML 전 여러 개의 리두로그 생성, 리두 로그 버퍼에 기록한다.
3. 통계 정보 수집
- 해당 리두로그의 통계 정보 수집
4. 리두 Copy Latch 획득 <<---- N개
- 리두로그 버퍼에 기록하기 위해서는 리두 Copy Latch를 획득해야 한다.
5. 리두 Allocation Latch 획득 <<----- 1개
- 리두로그 버퍼로부터 로그 기록할 여유 공간 할당 받아야
6. SCN 할당
7. 리두로그 버퍼 공간 확인
- 공간 존재: ⑧
- 공간 부족: ⑨,⑩
8. 리두 로그 기록
- 리두 로그를 리두 로그 버퍼에 기록
9. 리두 Writing Latch 획득 <<------- 1개
- DB에 하나만 존재, 해당 latch 획득한 서버 프로세스만이 LGWR 프로세스 기동
10. LGWR 기동
- 리두 Writing Latch 획득한 프로세스는 LGWR 프로세스를 기동시켜, 리두 로그 버퍼의 내용을 리두로그 파일에 기록하고, 여유 공간을 확보한다.
Latch, Enqueue
Latch
- 짧은 시간 동안 메모리 등의 자원에 락 수행하는 부분에서 사용
Enqueue
- 테이블 및 인덱스 등의 작업 시 오랜 시간 동안 락을 수행
Streams Pool
기존의 데이터 복제 및 Event를 Remote의 다른 데이터베이스로 전송할 수 있다.
Streams Pool 사용하는 프로그램
-
Oracle Streams
- DBMS_STREAMS 패키지
- Oracle 데이터베이스 데이터 변경 사항을 복제, 전파하여 이벤트를 관리한다.
- ex) 특정 테이블의 데이터를 다른 데이터베이스에 복제하거나, 데이터 변경 사항을 감지하여 이벤트를 발생시키는 데 사용
-
Advanced Queuing
- DBMS_AQADM 패키지
- 메시지를 큐에 저장, 전달 큐를 통해 메시지를 관리하고 전송하는 시스템
- Oracle Streams와 통합되어 큐 관리, 메시지 전달하는 역할
-
Datapump export/import
-
OGG Integrated Mode
- 실시간으로 데이터를 캡쳐, 전파, 변환
1) Capture
- 해당 Object에 대한 변경된 데이터를 리두로그로부터 액세스하는 역할.
- 데이터베이스의 변경사항(DML, DDL)등 감지.
- 그 정보를 LCR(Logical Change Record) 형태로 기록하여 어떤 변화가 있었는지 큐에 수집한다.
큐: 임시 장소로, 데이터를 다음 단계 전달 전까지 대기. Oracle Streams 에서 데이터가 잠시 대기한다.
비유: 우편물 수집 단계
2) Staging
- LCR 데이터를 큐(Queue) 안에 대기
- 큐에서 데이터 이동할 준비가 될 때까지 저장.
비유: 우편물을 분류하고 대기시킴
3) Apply
- Destination queue 에서 LCR을 액세스
- LCR 형태를 읽어, 실제 DB의 변경 사항으로 적용한다.
비유: 우편물을 배달하는 작업
Script
-ge
- 왼쪽 값이 오른쪽 값보다 같거나 클 때 true
tee -a
- 출력도니 결과를 파일에 저장 + 동시에 화면에도 출력
SQL Plus에서 결과값 html로 출력
set markup html on spool 파일명;(ex: result.html) 쿼리문 수행 spool off;
- exit 하고 파일 생성된 것 확인하기
RMAN
- 유틸리티이므로 sqlplus 밖 os단에서 실행해야함
- 백업 가능 대상😊
- database, tablespace, datafile, archived redo log, control file (Current 또는 image copy)
- 백업 불가능 🤷♀️
- online redo log, init.ora, password file, listener.ora, tnsnames.ora
rman target / ----> rman 접속
show all; ----> 설정된 항목들 모두 조회
list backup of database -----> 데이터베이스 백업에 대한 세부 정보를 조회
list backup of summary -----> rman 백업의 요약 정보를 간단하게 확인할 때 사용list backup of database: 데이터베이스의 개별 백업 세트에 대한 상세 정보를 조회list backup summary: 모든 백업에 대한 요약 정보를 표시한다. 백업 전체 현황을 빠르게 확인하고 싶을 때 사용한다.
각 백업 파일별로 Input Buffer 사용내역, 크기
> set line 200;
> set pagesize 50;
> col filename for a50;
>
> SELECT SET_COUNT, DEVICE_TYPE, TYPE, FILENAME, BUFFER_SIZE, BUFFER_COUNT, OPEN_TIME, CLOSE_TIME
> FROM V$BACKUP_ASYNC_IO
> ORDER BY SET_COUNT, TYPE, OPEN_TIME, CLOSE_TIME;Output Buffer
- 백업 셋에 내려 쓰이기 전, 사용되는 버퍼
- 출력장치 --> 디스크 / 테이프
- 디스크: Channel 당 4개 버퍼, 각 버퍼의 크기 1M
- 테이프: 테이프 디바이스 속도에 따라 달라짐. 테이프로부터 데이터를 복원할 경우, Channel 당 4개의 버퍼 할당, 각 버퍼의 크기 256kb
Recovery Catalog 저장되는 정보
- 이번 site에서는 사용되지 않았지만... 설명주셔서 다시 한 번 찾아봤다.
- Data file, 아카이브 리두로그 파일의 백업 셋과 copy 된 이미지에 대한 정보
- 백업 대상 서버의 물리적인 구조
- 자주 사용하는 백업 스크립트
→ Catalog server 사용 시 접속: rman target / catalog rcuser/rcuser@rcserver
%U
- 파일명이 중복되지 않도록, RMAN이 Unique한 번호로 이름을 생성한다.
%T
- 백업 날짜
백업과 복구
백업
- 체크포인트 SCN을 기준으로, RMAN 백업을 수행한다. --> 일관성 보장
복구
- 체크포인트 정보 + 리두로그 활용
증분 백업
- 이전에 백업 받았던 백업 파일과 비교해서, 변경된 부분만 골라서 백업을 수행한다.
- 차등 증분 백업
- 누적 증분 백업
차등 증분 백업
- 현재 날짜와, 이전 날짜의 level 숫자가 작거나 또는 같으면, 그 이전의 날짜와 지금 날짜 사이의 변경된 모든 데이터를 백업한다.
누적 증분 백업
- 기준되는 날짜를 찾기 위해 작은 날짜가 와야한다. (나머지는 차등 증분 백업과 동일한 방식으로..)
스키마 생성 확인
set lines 200 pages 9999; col username for a20 col account_status for a20 select username, account_status, created from dba_users order by created desc;
nmon 스크립트
nohup [nmon실행경로] -f -s 10 -c 10 -m [nmon 수행결과 저장될 디렉토리] &