출처
성능분석이란?
- 시스템의 성능 문제(응답 지연, 처리량 저하 등) 을 분석하는 과정
- 성능 분석의 목적은 시스템의 병목 현상을 파악하고, 적절한 대응을 통해 성능을 개선하는 것
- 성능 분석에는 Reactive(사후 대응형)과 Proactive(사전 예방형) 두 가지 방식이 있다.
Reactive한 성능 분석(사후대응형)
-
문제가 발생한 후 원인을 분석하고 대응하는 방식 -
ex) 데이터베이스 트랜잭션이 지연됨 / cpu 사용률이 갑자기 증가
-
목적: 문제가 발생한 후에 그 원인(병목현상, 리소스 부족 등)을 분석하여 해결
-
특징: 이미 발생한 성능 문제를 분석하여 대응하는 방식, 문제를 해결할 수 있지만, 사전에 예방하지 못함
-
단점: 문제가 발생한 후 대응하기 때문에 장애 발생 가능성이 있음
Proactive한 성능분석(사전예방형)
-
문제가 발생하기 전에 미리 성능을 분석하고, 최적화하는 방식 -
예제 상황: 현재는 문제가 없지만, 미래에 CPU, 메모리, 스토리지 부족 가능성이 있음
-
주기적으로 성능 모니터링 및 튜닝을 수행
-
성능 저하가 발생하기 전에 미리 문제를 감지하고 예방
-
특징
- 시스템의 상태를 정기적으로 분석하고 튜닝을 수행
- 성능 문제를 사전에 방지
-
단점
- 성능 분석 및 모니터링에 추가적인 비용과 시간이 필요하다.
-
시스템을 이용하고 있는 서비스에서 reponse 지연/처리량 저하 등의 성능 문제나 리소스 부족 등에 따른 예기치못한 장애를 미연에 방지하기 위해, 정기적으로 실시한다.
-
문제가 발생하기 전에 대응하는, 사전적인 성능분석
성능분석이란?
- 2개의 성능 분석이 중요한 이유
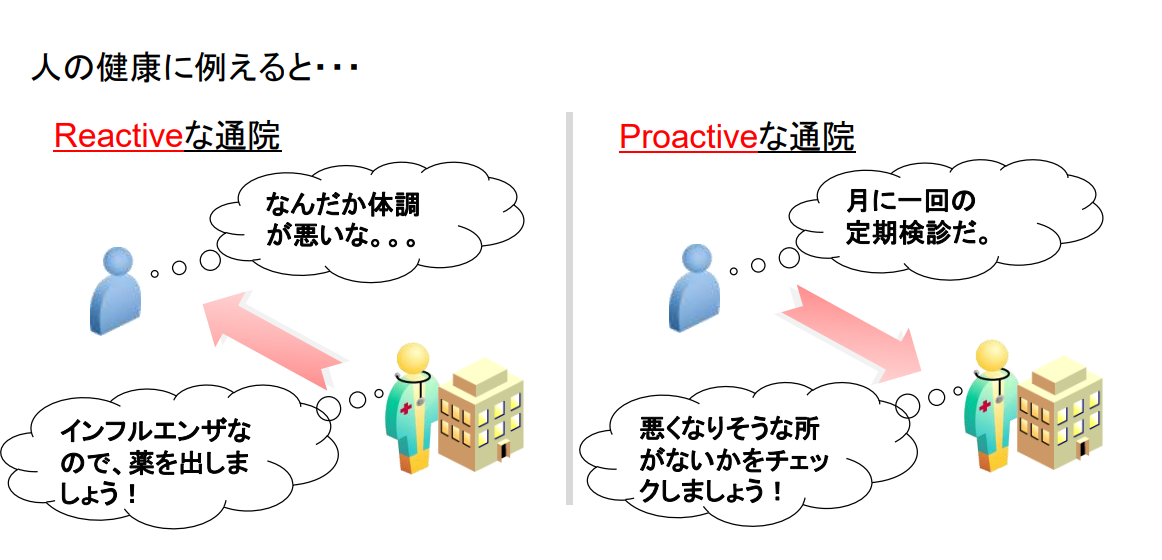
- Reactive: 몸이 안 좋네.. 독감이므로 약을 드리죠!
- Proactive: 달에 한 번 정기검진이다. -- 나빠질 곳이 있는지를 체크합시다!
사람을시스템,병원을성능분석으로 치환하면 성능분석에서는 2개의 패턴으로 중요하다는 것을 알 수 있다.
Reactive한 성능분석
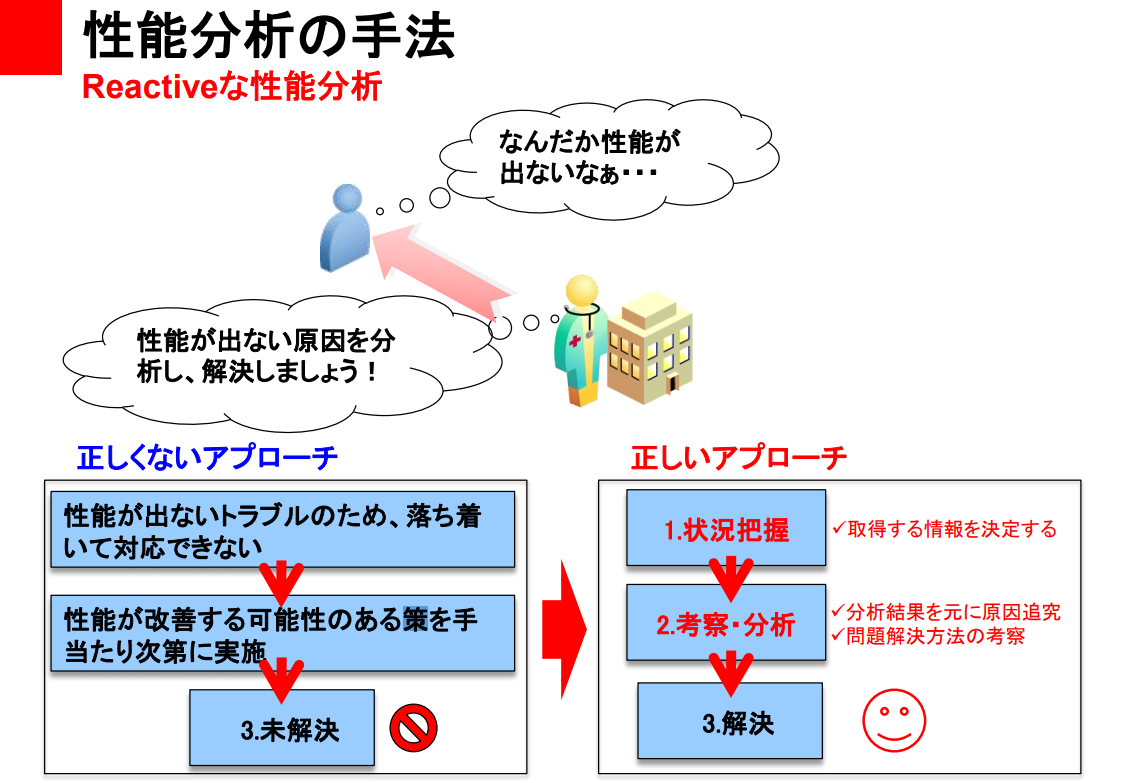
안 좋은 접근
- 성능이 안좋은 문제 때문에, 침착하게 대응할 수 없다
- 성능이 개선될 가능성이 있는 대책을 잡히는대로 실시
- 미해결
올바른 접근
- 상황파악 -- 조회할 정보를 결정함
- 고찰/분석
- 분석결과를 근거로 원인 추궁
- 문제해결 방법의 고찰
- 해결 :)
Proactive한 성능분석
체크포인트
- baseline 활용
- performance를 비교하기 위해서, 정상으로 동작하고 있는 정보를 조회, 베이스라인에 의해 장애 시에 정상적일 때와의 차이를 비교해서 문제점을 파악하는 것이 가능하다.
- Capacity Planning
- 평소부터 정기적으로 성능분석을 행하는 것으로, 향후 리소스의 고갈을 예방하고 미래의 resource 부족에 대비하여 사전에 준비하는 것이 가능하다.
성능 분석에서의 필요 정보
- 성능분석을 실시하기 위한 필요한 정보
- 특정 시스템 뿐만 아니라, 시스템 전체의 성능 정보를 조회
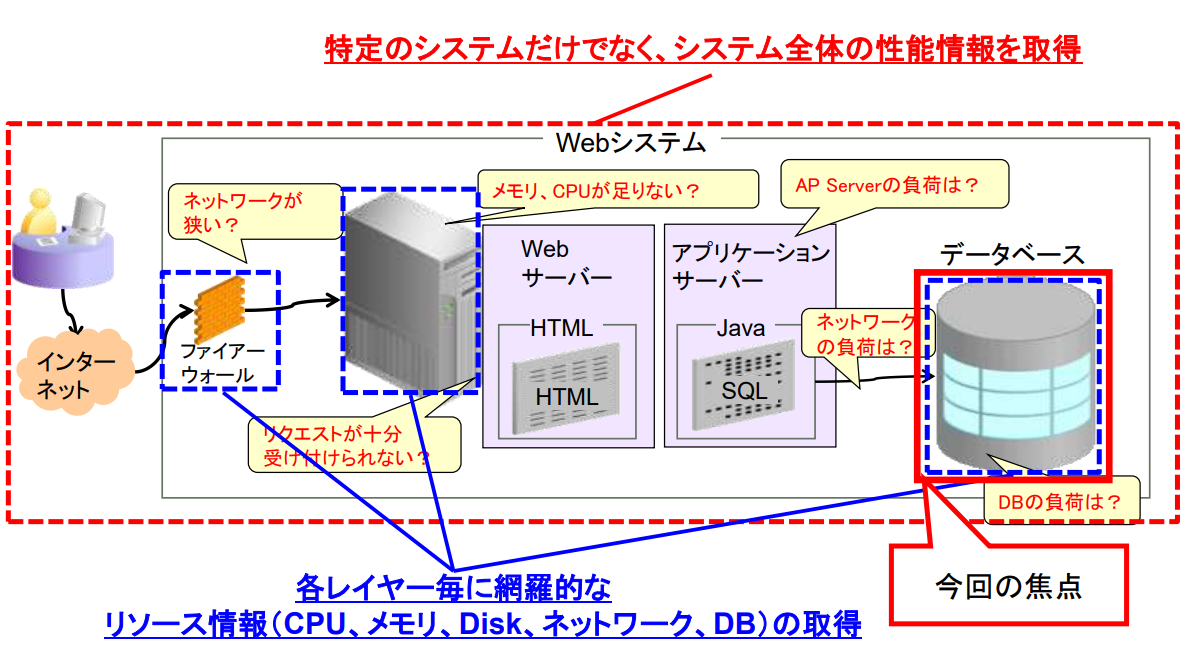
각 레이어별 리소스(CPU, Memory, Disk, Network, DB) 정보를 조회
AWR 레포트를 사용한 성능분석
- proactive에 정기검진을 받은 후, 중요한 것은 검진 결과를 이해하고 현재의 건강상태를 아는 것이다. AWR 레포트를 사용한 성능분석에서는 무엇을 이해하면 시스템의 상태를 이해할 수 있는걸까?
AWR 레포트를 사용한 성능 분석
AWR(Automatic Workload Repository) 개요
- DB 내부의 통계정보(snapshot)을 조회하는 기능
- 어느 두 구간에서 조회한 DB 내부의 통계 정보(snapshot)의 차등(차이)를 근거로 그 사이의 performance 통계 데이터를 report로 출력 가능하다.
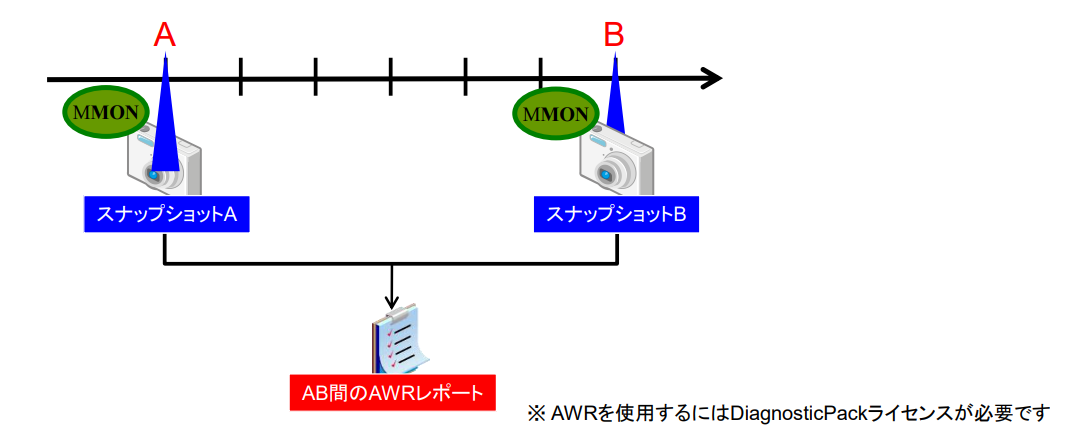
- DiagnosticPack 라이선스가 필요하다
Oracle Database에 특화된 성능분석 정보
Snapshot 관리
- EM
- PL/SQL (DBMS_WORKLOAD_REPOSITORY)
CASE1: 수동으로 스냅샷을 조회하고, 성능 분석을 수행하고 싶을 때
begin
DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT();
end;CASE2: 성능 테스트를 실시하기 위해, 자동 스냅샷 조회 간격을 default 60분에서 10분으로 변경하고, 성능분석을 수행하고 싶음
begin
DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS(11520,10);
end;CASE3.: SYSAUX 테이블스페이스가 용량을 차지해와서, Snapshot id 1000-2000의 snapshot 삭제를 실행하고 싶음
begin
DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE(1000,2000);
end;AWR report 생성
- 생성 방법 2가지: EM, SQL
- 기간 비교: 다른 기간 사이에서의 AWR 레포트를 비교함에 따라, 상세적인 performance를 분석하는 것이 가능하다.
- baseline과 비교하는 것도 가능
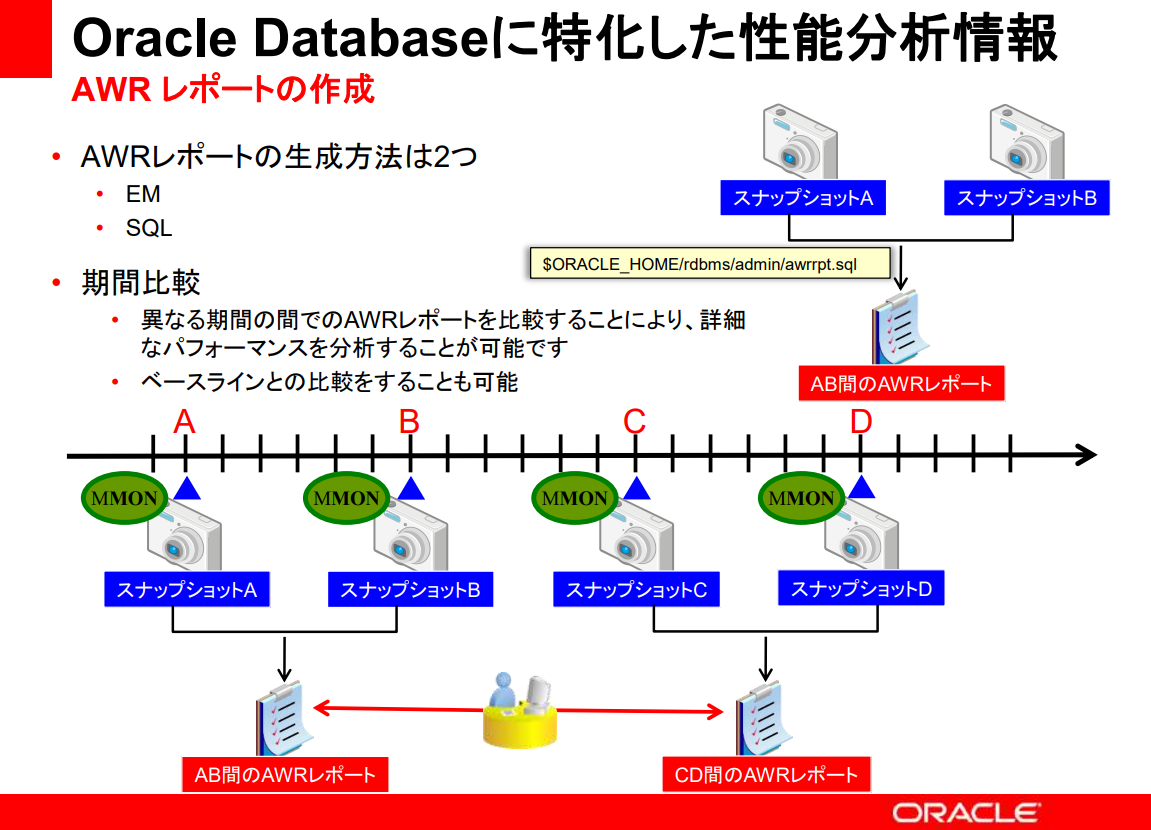
AWR에 저장되는 정보
-
Database Segment Access 정보
-
데이터베이스 내에서 특정 세그먼트가 얼마나 자주 접근되고, 얼마나 많은 I/O 작업이 이루어지는지 등을 보여준다.
-
segment 사용률: 테이블이나 인덱스가 얼마나 자주 읽히고 쓰이는 지에 대한 정보이다. 예를 들어, 특정 테이블이 자주 조회되거나 수정되는 경우, 이 정보를 통해 해당 테이블의 성능 최적화가 필요할 수 있음을 알 수 있다.
-
I/O 정보: 세그먼트에 대한 읽기 및 쓰기 작업이 얼마나 자주 발생하는지, 그리고 그로 인한 디스크 I/O가 얼마나 발생하는지를 추적할 수 있다.
-
-
-
시간 모델의 정보(10g부터의 새로운 통계 정보)
- 어느 처리에서 어느 정도 시간을 소비했는지의 정보
V$SYS_TIME_MODEL, V$SESS_TIME_MODEL동적 성능 뷰로부터 수집- V$SYS_TIME_MODEL : 시스템 전체에서 발생하는 시간 소비를 보여주는 뷰
- V$SESS_TIME_MODEL : 각 세션별로 소모된 시간을 추적하는 뷰, 각 세션이 어떤 자원에 대해 얼마나 많은 시간을 소비했는지 세부적으로 알 수 있다.
-
SYSTEM, session 통계
V$SYSSTAT, V$SESSTAT동적 성능 뷰로부터 수집- V$SYSSTAT: 시스템 수준에서 발생하는 통계 정보를 제공, 전체 데이터베이스의 CPU 사용량, 메모리 소비, 디스크 I/O와 같은 통계 데이터를 추적한다.
- V$SESSTAT: 각 세션별 통계정보를 제공하며, 특정 사용자가 실행하는 SQL문이나 트랜잭션에 대한 세부 성능 데이터를 추적한다. 예를 들어 특정 사용자가 많은 쿼리를 실행하면서 CPU 자원을 많이 사용하는지, 아니면 disk i/o가 많은지 등의 정보를 알 수 있다.
-
부하가 높은 sql 정보
- 실행 시간이나 CPU를 소비한 시간 등에 기반함
-
최신 Session activity의 이력을 나타내는 ASH 통계
- 1초마다 sampling하고 있는, active한 session 정보
-
ASH(Active Session History) 는 1초마다 활성 세션에 대한 정보를 샘플링하여 저장하는 시스템. 이를 통해 실시간으로 활성 세션의 상태를 추적할 수 있다.
- 샘플링 주기: 매초 1번씩 활성 세션을 샘플링, 각 세션이 어떤 작업을 하고 있는지 기록한다.
이를 통해 사용자가 데이터를 조회하거나 트랜잭션을 실행하는 동안의 상태 변화를 추적할 수 있다. - 활성 세션 정보: 각 세션이 어떤 리소스를 대기 중인지, SQL 실행 중인지, 또는 기타 작업을 수행 중인지와 같은 정보를 알 수 있다.
- 샘플링 주기: 매초 1번씩 활성 세션을 샘플링, 각 세션이 어떤 작업을 하고 있는지 기록한다.

Main Report
- Report Summary
- 대기 이벤트 통계
- SQL
- Instance 통계
- I/O 통계
- Buffer Pool 통계
- Advisor 통계
- Wait Statistics
- Undo 통계
- Latch 통계
- Segment 통계
- Dictionary Cache 통계
- Library Cache 통계
- Memory 통계
- Stream 통계
- Resource 제한 통계
- init.ora 파라미터 (초기화파라미터)
More RAC Statistics
- RAC에 관한 추가정보 레포트
- Global Enqueue 통계
- Global CR 통계
- 실행 후의 Global Current 통계
- Global Cache의 송신 통계
AWR 레포트에 대한 분석 접근
AWR 확인 포인트
1. Load Profile: DB의 처리양을 표시한다.
2. Instance Efficiency : Oracle Instance의 사용효율을 표시
3. Top5 Timed Events: 처리시간의 긴 순위 5번째까지의 이벤트를 나타낸다.
4. SQL Section : 각 처리에서의 SQL문 순위를 표시한다.
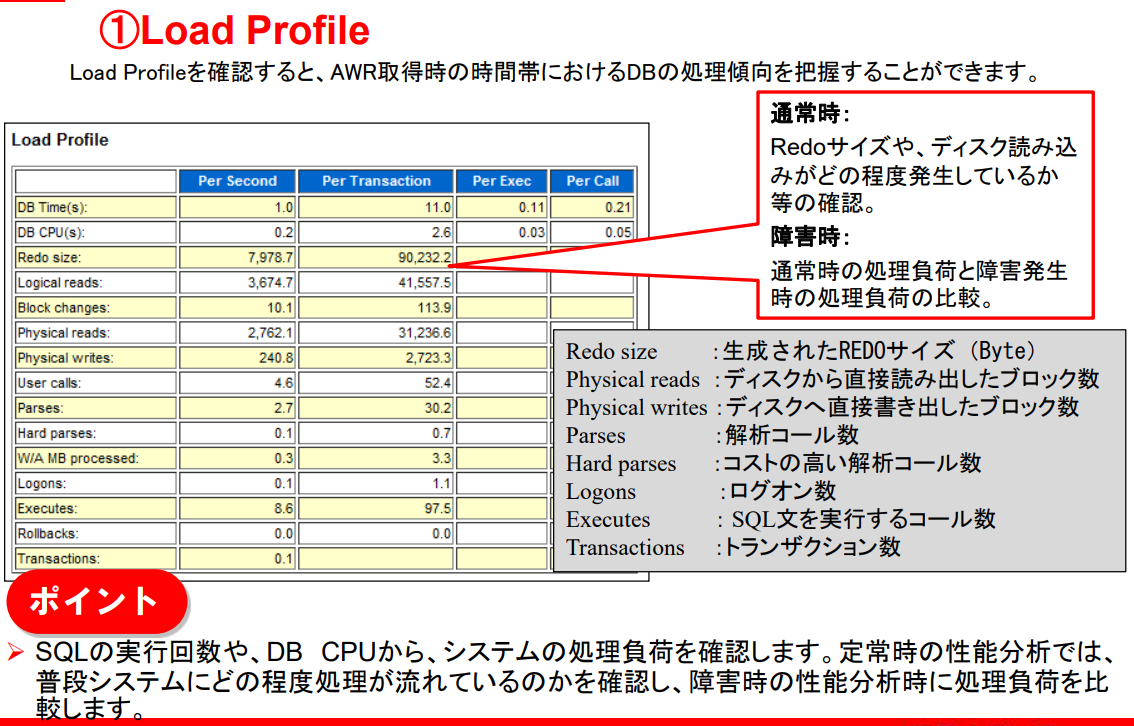
1. Load Profile
- AWR 조회 시의 시간대 DB의 처리 경향을 파악하는 것이 가능하다.
- 데이터베이스의 실행 부하를 측정하는 지표로, 정상 시점과 장애 발생 시점을 분석하여 성능을 분석하는 데 사용된다.
- DB Time(s) : DB에서 처리된 총 시간 (초)
- DB CPU(s) : DB가 CPU에서 처리한 시간 (초)
- Redo size : 생성된 REDO 로그의 크기 (Byte)
- Logical reads : 논리적 블록 읽기 수 (버퍼 캐시에서 읽은 블록)
- Block changes : 데이터 블록 변경 횟수
- Physical reads : 디스크에서 직접 읽은 블록 수
- Physical writes : 디스크에 직접 기록한 블록 수
- User calls : 사용자 요청 (SQL 실행 등) 수
- Parses SQL : 문을 파싱한 횟수
- Hard parses : 성능이 낮은 Hard Parse 횟수 (SQL 재사용 불가)
- W/A MB processed : 작업 영역에서 처리된 데이터 크기 (MB)
- Logons : 로그인 수
- Executes : SQL 문을 실행한 횟수
- Rollbacks : 롤백된 트랜잭션 수
- Transactions : 초당 트랜잭션 수
2. Instance Efficiency
- OLTP 시스템에서는 Buffer Hit%, Library Hit%는 90% 정도가 되어야 한다.
- Library Hit%와 Soft Parse%는 의존 관계에 있어, Library Hit가 낮은 경우엔 Hard Parse가 차지하는 비율이 높아진다.
- 데이터베이스 내부에서 자원을 얼마나 효율적으로 사용하는지를 파악한다.
- 일반적으로 Buffer Hit, Soft Parse 비율을 확인
- 장애 시 평상시와 hit율의 비교
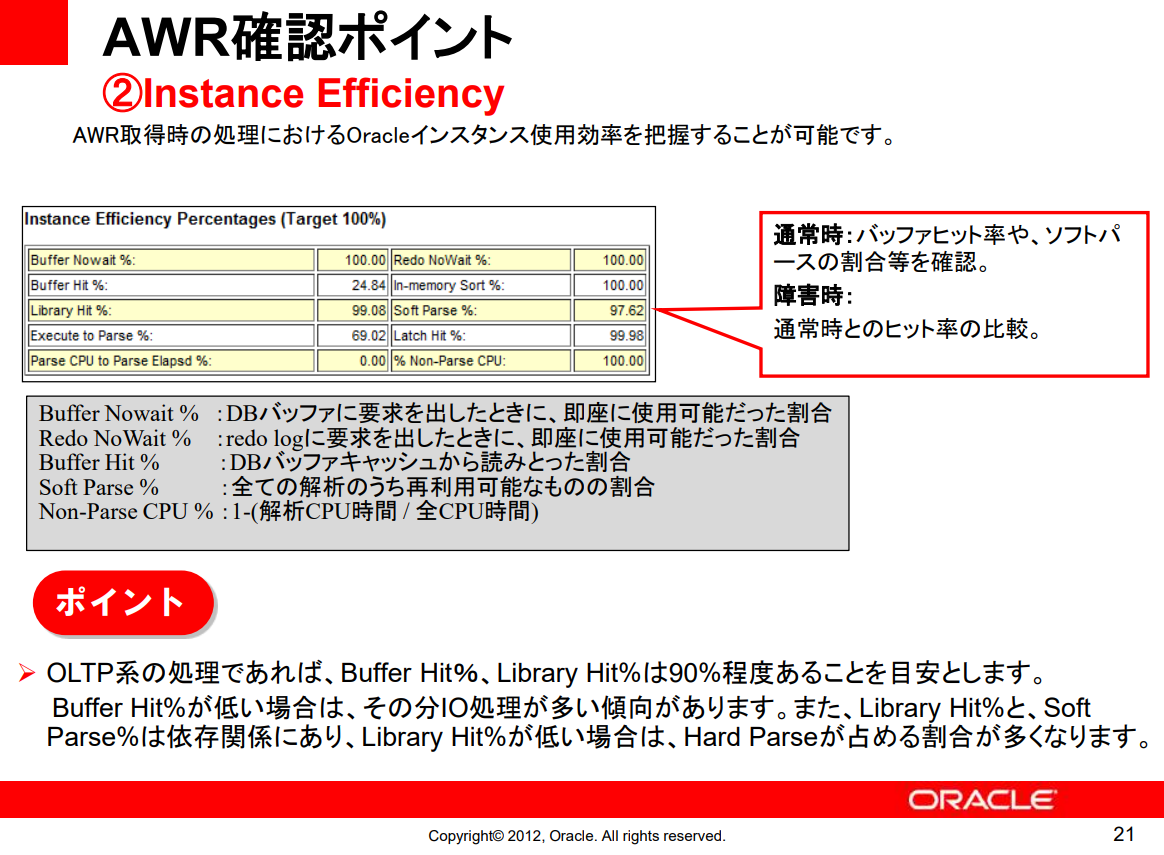
- 장애 시 평상시와 hit율의 비교
- Buffer No wait: DB Buffer에 요청했을 때 즉시 사용가능했던 비율
- Redo No Wait: redo log에 요청했을 때 즉시 사용가능했던 비율
- Inmemory Sort: 정렬(Sort) 작업이 메모리에서 수행된 비율을 나타내는 AWR 리포트 지표
- 디스크를 사용하지 않고, 메모리에서 정렬이 이루어진 비율을 의미한다.
| 항목 | 의미 | 해석 |
|---|---|---|
| Buffer Nowait % | DB 버퍼에서 데이터를 요청했을 때, 즉시 사용 가능했던 비율 | 100 (좋음) → 대기 없이 즉시 버퍼 접근 가능 |
| Redo NoWait % | Redo 로그를 기록할 때, 즉시 사용할 수 있었던 비율 | 100 (좋음) → Redo 로그 버퍼가 부족하지 않음 |
| Buffer Hit % | 데이터 조회 시, 버퍼 캐시에서 읽어온 비율 | 24.84 (문제 가능) → 디스크에서 직접 읽는 비율이 높음 |
| Library Hit % | SQL 실행 시, 라이브러리 캐시에서 재사용된 비율 | 99.08 (좋음) → SQL이 잘 재사용됨 |
| Execute to Parse % | 실행된 SQL 중, 새로운 파싱 없이 실행된 비율 | 69.02 (낮음) → SQL 파싱 비용이 높음 |
| Parse CPU to Parse Elapsed % | SQL 파싱 중, CPU 사용만으로 완료된 비율 | 0 (문제 가능) → 파싱 시 CPU 이외의 대기 시간이 많음 |
| In-memory Sort % | 정렬이 메모리에서 수행된 비율 | 97.62 (좋음) → 대부분의 정렬이 메모리에서 수행됨 |
| Latch Hit % | Latch(동기화 메커니즘) 충돌 없이 성공한 비율 | 99.98 (좋음) → Latch 경합 문제 없음 |
| Non-Parse CPU % | 전체 CPU 사용량 중 SQL 파싱 외의 작업에 사용된 비율 | 100 (좋음) → CPU가 파싱 외의 작업에 효과적으로 사용됨 |
3. Top5 Timed Event

- Event: 이벤트명
- Waits: 이벤트 때문에 대기한 합계횟수
- Time(s): 이벤트 합계 대기시간 및 합계 CPU시간(초)
- % Total Ela TIme: 전체에 대해 이 이벤트 및 CPU 시간의 비율(각 이벤트 대기시간/합계처리시간)
4. SQL Section ~ SQL Order by Gets
- SQL Order by Gets: 버퍼읽기(Buffer Gets)가 많은 SQL을 순위별로 정렬한 리스트로, 즉, 많은 데이터를 논리적으로 읽어들이는 SQL을 파악하는 데 유용한 지표이다.
- Buffer Gets: SQL이 실행될 때 버퍼 캐시에서 데이터를 읽은 횟수를 의미한다.
- 이 값이 크다는 것은 해당 SQL이 메모리에서 많은 데이터를 가져오고 있다는 뜻이다. - 논리적인 데이터 조회(버퍼 읽기)가 많은 SQL을 확인하고, 비효율적인 SQL을 튜닝하는 데 사용된다.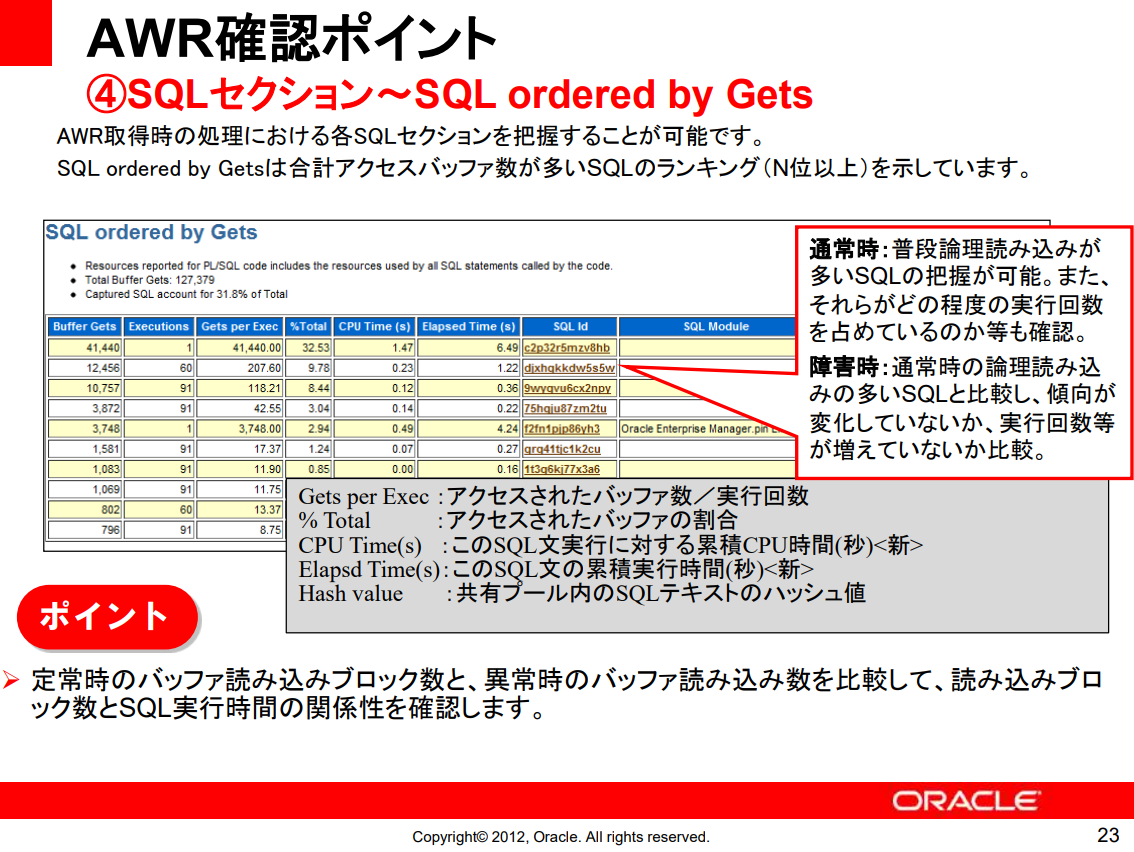
- Buffer Gets: SQL이 실행될 때 버퍼 캐시에서 데이터를 읽은 횟수를 의미한다.
- Gets Per Exec: Access된 Buffer 수/실행횟수
- %Total: Access된 Buffer 비율
- CPU Time(s): 이 SQL문 실행에 대한 누적 CPU시간(초)
- Elapsed Time(s): 이 SQL문의 누적실행시간(초)
- Hash Value: Shared Pool 내 SQL 텍스트 Hash값
Case Study
- AWR 레포트에서의 분석 접근
- A사에서 Proactive한 성능분석을 수행하기 위해 평소부터 AWR를 조회하고 있다. 어느날, Application측으로부터 "고객으로부터 화면 Response가 늦어졌어요 라고 들었지만, DB측에 문제가 있나요?"
- Application측에서는 문제를 발견할 수 없었기에, DB측을 조사해주실 수 있나요? 라는 요구사항을 들었다.
AWR을 사용해서, 어떻게 성능 분석을 진행할 수 있을까?

Top 5 wait event로부터 대기 이벤트 db file sequential read가 발생, 물리적 읽기가 많은 segment는 IO_NECK_TAB_IX로 불리는 INDEX이며, IO대기가 발생하고 있다.
- 특정 Segment에서의 IO대기가 발생하고 있다는 것은...
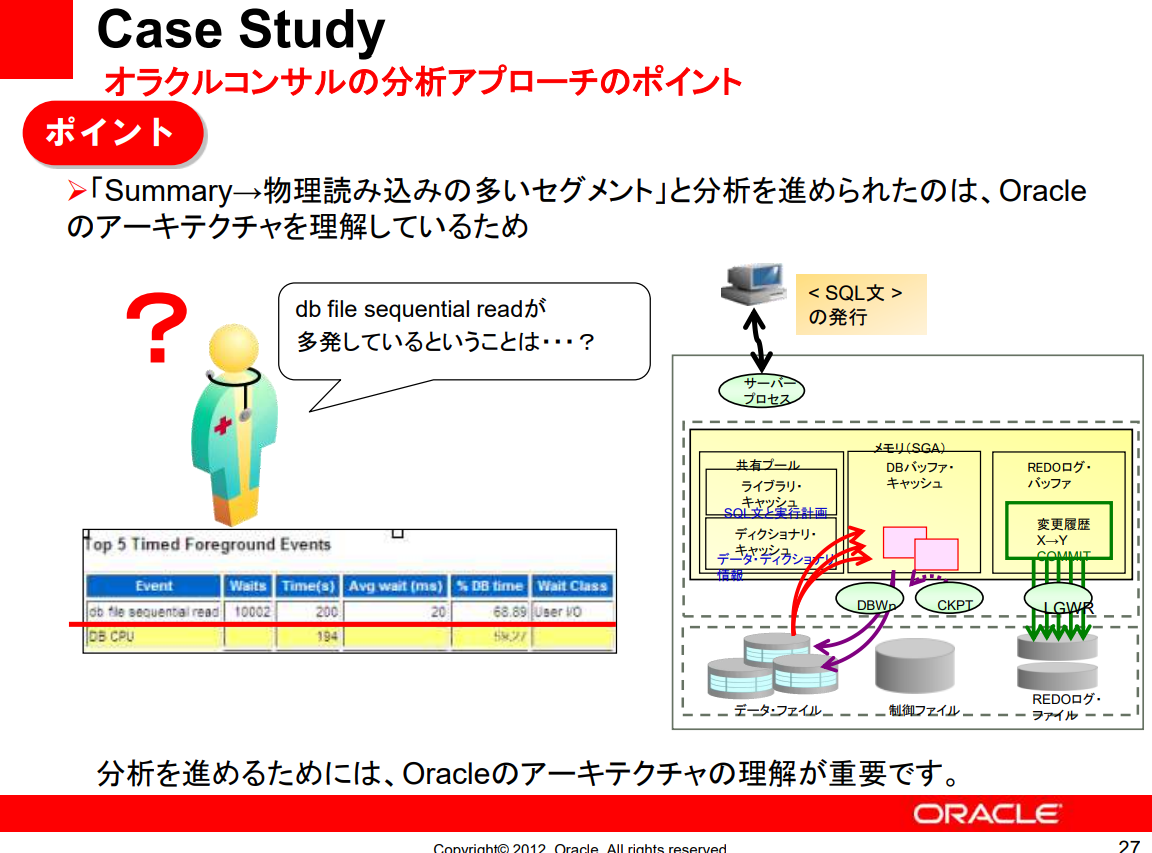
- Summary-> 물리적인 Read가 많은 segment라고 분석을 진행한 것은 Oracle Architecture을 이해하고 있기 때문
- db file sequential read가 발생하고 있다는 것은?