사전스터디 토이 프로젝트 주제로 서점 사이트를 크롤링해와 리뷰를 나누는 페이지를 만들기로 했다.
필요한 정보
- 책의 이미지
- 제목
- 글쓴이
- 별점
- 가격
그래서 크롤링을 해보긴 했는데...
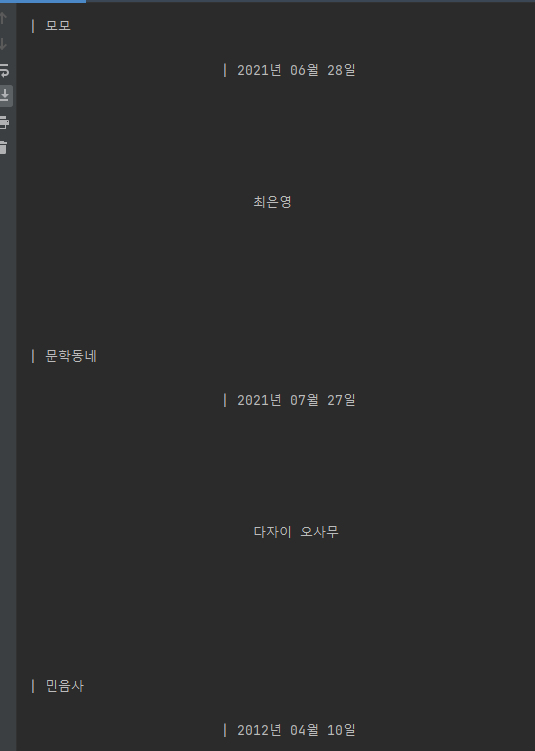
크롤링하기 가장 깔끔해보였던 교보문고 사이트는 저자, 출판사, 출간일이 한 셀렉터 안에 합쳐져있어서, 그 모든 게 이렇게 엄청난 공백과 함께 튀어나와버렸다. 예상 외의 복병 ㅡㅜ.
일단 거슬리는 '|'를 지워주고, strip()을 사용해보았으나
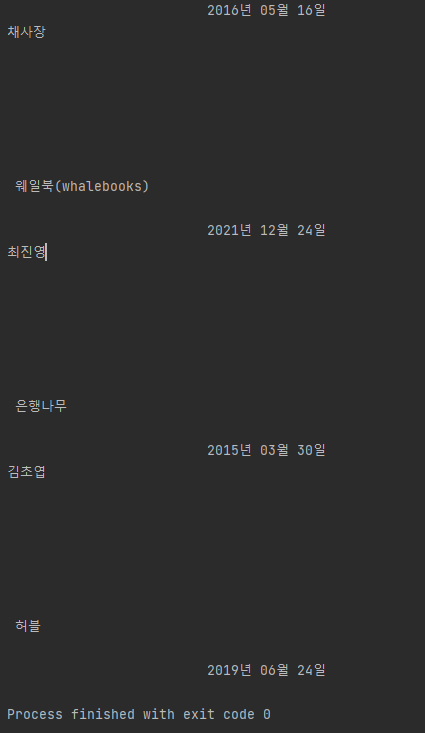
크게 개선된 게 없는 모습...!
일단 출간일과 다음 책의 저자명 사이 공백이 줄어들긴 했으나 여전히 원하는 결과와는 거리가 멀었다. 사람살류ㅜ

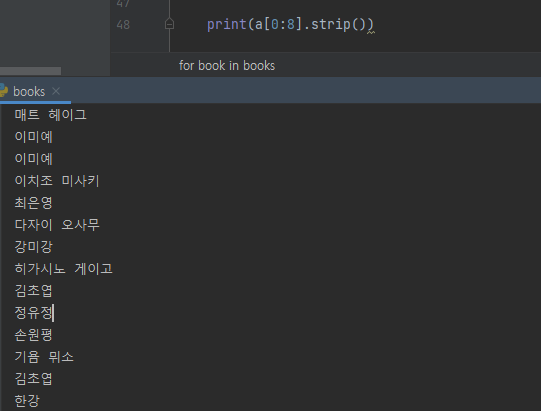
세번째 시도. 베스트셀러 20위권 내에 공백 포함 8글자를 초과하는 저자명이 없다는 점을 이용해 글자수를 제한해버렸다.
print(a[0:8])야매지만 나름의 성과가 있었다...
네번째 시도.
글자수를 제한했던 것에 더해 한 번 더 strip()으로 공백을 제거해버림.
print(a[0:8].strip())어쩌다보니 원하는 결과를 얻긴 했는데 이렇게 해도 되는지 모르겠다. 일단은 기록을 해둠...
광활한 공백 사이에 있는 텍스트 문단을 깨끗하게 따오는 방법은 없을까 ㅡ ㅜ......
추가!! 0224
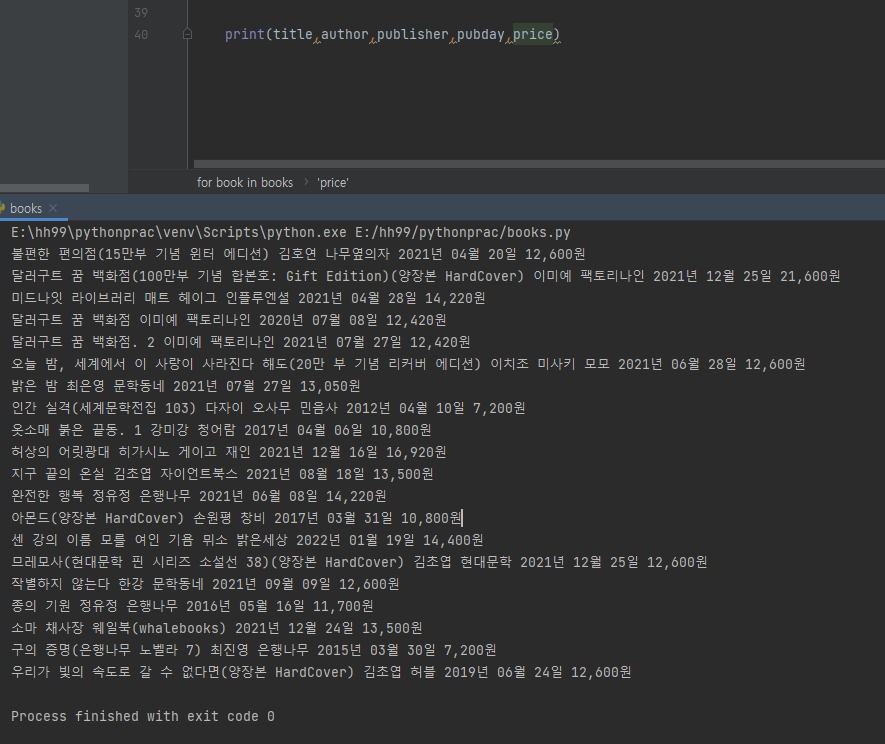
for book in books :
image = book.select_one('div.cover > a > img').get('src')
title = book.select_one('div.detail > div.title > a > strong').get_text()
info = book.select_one('div.detail > div.author').text.split('|')
rank = book.select_one('div.detail > div.review > img').get('src')
price = book.select_one('div.detail > div.price > strong').get_text()
author = info[0].strip()
publisher = info[1].strip()
pubday = info[2].strip()
doc = {
'image':image,
'title':title,
'author':author,
'publisher':publisher,
'pubday':pubday,
'rank':rank,
'price':price
}
db.books.insert_one(doc)
훨씬 깔끔하고 아름다운 방법이 있었다
조언해준 친구에게 무한한 감사의 인사...

가보자고