Hugging Face의 attn_implementation("eager", "sdpa", "flash_attention_2", "flash_attention_3")
이 4개는 attention의 수학 자체가 완전히 다른 것이라기보다, 같은 scaled dot-product attention을 어떤 구현체/backend로 계산하느냐의 차이에 가깝습니다. Hugging Face는 attn_implementation으로 "eager", "sdpa", "flash_attention_2", "flash_attention_3"를 지원한다고 설명합니다. 기본적으로는 가능하면 sdpa를 사용합니다. (Hugging Face)
0. 먼저 큰 그림
Transformer attention의 기본 수식은 거의 같습니다.
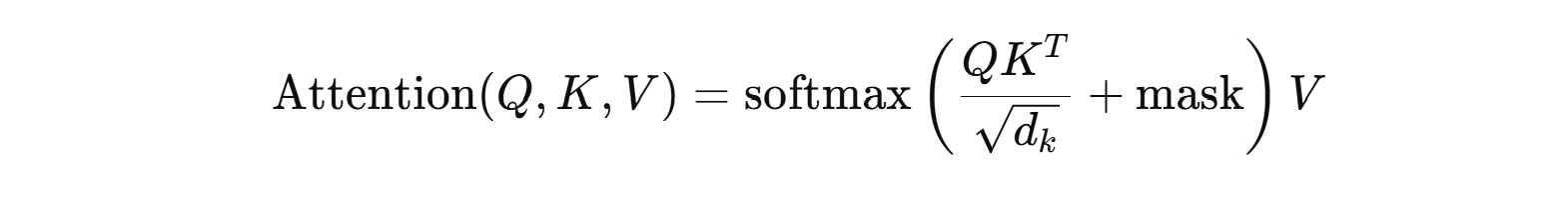
PyTorch의 scaled_dot_product_attention도 바로 이 계산을 수행한다고 설명합니다. 차이는 이 수식을 그대로 순진하게 계산하느냐, 아니면 GPU 메모리 접근과 커널 융합을 최적화해서 더 빠르고 메모리 효율적으로 계산하느냐입니다. (PyTorch Documentation)
1. eager
정의
Hugging Face 문서 기준으로 "eager"는 manual implementation of the attention, 즉 일반적인 수동 구현 attention입니다. (Hugging Face)
어떤 알고리즘인가?
가장 전통적인 방식입니다.
대략 흐름은:
- (QK^T) 계산
- scaling
- mask 더하기
- softmax
- (V)와 곱하기
즉, attention 행렬을 비교적 “정직하게” 계산하는 방식이라고 보면 됩니다.
PyTorch 블로그에서 말하는 SDPA의 fallback인 math implementation과 비슷한 성격의, 가장 일반적이고 하드웨어 중립적인 방식으로 이해하면 됩니다. (PyTorch)
특징
- 호환성 최고
- 디버깅이 쉬움
- 보통 가장 느림
- 메모리도 더 많이 먹는 편
언제 쓰나?
- FlashAttention 설치가 안 될 때
- 모델/환경 호환성이 애매할 때
- “일단 돌아가기만 하면 된다”가 중요할 때
한 줄 느낌
가장 기본형 / 가장 안전 / 보통 가장 느림
2. sdpa
정의
Hugging Face 문서에서는 "sdpa"를 PyTorch built-in implementation of scaled dot product attention이라고 설명합니다. 즉 torch.nn.functional.scaled_dot_product_attention을 사용하는 방식입니다. (Hugging Face)
어떤 알고리즘인가?
이름 그대로 Scaled Dot-Product Attention입니다.
중요한 점은, sdpa가 단일 구현 하나를 뜻하는 게 아니라, PyTorch가 내부에서 가장 적절한 backend를 고르는 인터페이스라는 점입니다.
PyTorch는 SDPA 내부에서 세 가지 계열 backend를 사용할 수 있다고 설명합니다.
- Flash Attention
- Memory-Efficient Attention
- Math implementation fallback (PyTorch)
즉 sdpa는 “이 attention을 계산해줘”라는 상위 인터페이스이고, 실제 아래에서는 상황에 따라 최적화된 구현을 탈 수 있습니다. PyTorch 문서도 “automatically select the most optimal implementation”이라고 설명합니다. (PyTorch Documentation)
특징
- 별도
flash-attn패키지 없이도 되는 경우가 많음 - 보통
eager보다 빠름 - PyTorch가 내부 최적 backend를 골라줌
- 실무적으로 가장 무난
언제 쓰나?
- 대부분의 일반적인 추론/학습
- 설치 스트레스 없이 성능도 어느 정도 챙기고 싶을 때
- 네 상황처럼
flash_attention_2가 안 될 때
한 줄 느낌
가장 밸런스 좋음 / 기본 추천
3. flash_attention_2
정의
Hugging Face 문서 기준으로 "flash_attention_2"는 Dao-AILab/flash-attention 구현을 사용합니다. 그리고 설명상 작은 타일(block) 단위로 계산을 나눠 fast on-chip memory를 활용합니다. (Hugging Face)
어떤 알고리즘인가?
핵심 아이디어는 attention 행렬 전체를 크게 메모리에 만들지 않고,
tile 단위로 잘게 쪼개서 SRAM/shared memory 같은 빠른 on-chip memory를 최대한 활용하는 것입니다.
그래서 HBM/global memory 왕복을 줄여 속도와 메모리 효율을 크게 높입니다. (Hugging Face)
쉽게 말하면:
- 일반 방식: 큰 attention matrix를 상대적으로 많이 드나듦
- FlashAttention-2: 메모리 traffic을 줄이도록 재구성된 fused kernel
특징
- 보통 매우 빠름
- 메모리 효율 좋음
- 긴 시퀀스에서 특히 강점
- 하지만 설치/빌드 난이도가 있음
- GPU 제약이 있음
FlashAttention-2 CUDA 지원은 현재 Ampere, Ada, Hopper GPU 중심이며 예시로 A100, RTX 3090, RTX 4090, H100을 듭니다. dtype도 fp16/bf16 중심입니다. (GitHub)
언제 쓰나?
- GPU가 Ampere 이상이고
- Linux/CUDA 환경이 맞고
- 최대 성능이 중요할 때
한 줄 느낌
빠르지만 설치와 호환성 조건이 까다로운 고성능 옵션
4. flash_attention_3
정의
Hugging Face 문서에서는 "flash_attention_3"가 FlashAttention-2를 개선한 버전이며, 연산 overlap과 더 강한 fusion을 통해 성능을 높인다고 설명합니다. 그리고 Transformers에서는 Dao-AILab의 flash-attention/hopper 구현을 가리킵니다. (Hugging Face)
어떤 알고리즘인가?
기본 철학은 FlashAttention-2와 같습니다.
즉:
- attention을 메모리 효율적으로 tile/block 단위 계산
- GPU의 on-chip memory 적극 활용
- kernel fusion 극대화
여기에 FlashAttention-3는 특히 Hopper 세대 GPU에서 더 잘 맞도록 설계된 최적화가 들어간 형태로 이해하면 됩니다. Hugging Face 문서도 FlashAttention-2 대비 overlap/fusion 개선을 명시합니다. (Hugging Face)
특징
- 이론상 4개 중 가장 공격적인 고성능 옵션
- 하지만 지원 환경이 가장 까다로움
- Hopper 계열 중심
관련 요구사항 자료에서는 Hopper GPUs, CUDA 12.3 이상, 그리고 CUDA 12.8 권장이라고 적혀 있습니다. (GitHub)
언제 쓰나?
- H100 같은 Hopper GPU가 있고
- 최신 CUDA 환경을 맞출 수 있고
- 최고 성능이 필요할 때
한 줄 느낌
Hopper 전용에 가까운 초고성능 옵션
5. 4개를 한 번에 비교
| 옵션 | 본질 | 구현 성격 | 장점 | 단점 | 추천 상황 |
|---|---|---|---|---|---|
eager | 기본 attention 수동 구현 | 가장 전통적 | 호환성 최고, 디버깅 쉬움 | 느리고 메모리 비효율적 | 일단 안정적으로 돌리고 싶을 때 |
sdpa | PyTorch의 scaled dot-product attention 인터페이스 | 내부 backend 자동 선택 | 성능/안정성 균형 좋음 | 환경 따라 성능 편차 가능 | 대부분의 사용자에게 기본 추천 |
flash_attention_2 | FlashAttention-2 최적화 커널 | tile + on-chip memory 활용 | 빠르고 메모리 효율 좋음 | 설치/호환성 까다로움 | Ampere/Ada/Hopper에서 성능 중요할 때 |
flash_attention_3 | FlashAttention-3 최적화 커널 | Flash-2보다 더 공격적 최적화 | 최고 성능 지향 | Hopper/CUDA 조건 매우 까다로움 | H100급 환경에서만 적극 고려 |
이 비교는 Hugging Face의 backend 설명, PyTorch의 SDPA 설명, FlashAttention 저장소의 요구사항을 바탕으로 정리한 것입니다. (Hugging Face)
6. “알고리즘이 다르다”는 말이 정확히는 무슨 뜻인가?
엄밀히 말하면 attention의 수학적 정의는 거의 같습니다.
차이는 주로 다음입니다.
eager
- 수학식을 비교적 직접 구현
- 중간 텐서를 더 명시적으로 생성하는 경향
sdpa
- 같은 attention 수식을 PyTorch의 통합 API로 계산
- 내부에서 더 좋은 구현을 선택 가능
flash_attention_2, flash_attention_3
- 같은 attention 결과를 목표로 하지만
- GPU 메모리 이동량을 줄이도록 계산 순서와 kernel 구조를 재설계
- 핵심은 속도/메모리 최적화
즉,
수학 문제는 비슷하고, 공학적 구현이 다르다
라고 보면 가장 정확합니다. (PyTorch Documentation)
7. 네 상황에서 뭘 고르면 되냐
네가 지금 flash-attn 설치에서 막혔으니까:
1순위
attn_implementation="sdpa"이게 제일 좋습니다.
Transformers도 torch>=2.1.1이면 기본적으로 SDPA를 우선 사용한다고 설명합니다. (Hugging Face)
2순위
attn_implementation="eager"이건 속도는 손해 보더라도 제일 안전합니다. (Hugging Face)
3순위
flash_attention_2
- GPU, CUDA, torch, flash-attn 버전이 딱 맞을 때만
4순위
flash_attention_3
- 사실상 Hopper급 환경 아니면 보통 우선순위 낮음 (GitHub)
8. 아주 짧게 비유하면
- eager: 교과서 방식으로 직접 계산
- sdpa: PyTorch가 알아서 최적 구현 선택
- flash_attention_2: 고성능 GPU용 특수 최적화 엔진
- flash_attention_3: 더 최신 GPU(Hopper)용 초고성능 엔진
