
kafka connect
Kafka Connect는 다양한 소스와 싱크 데이터베이스 또는 시스템간의 데이터 통합을 손쉽게 구현할 수 있도록 설계된 플랫폼입니다.
connect를 통해 kafka에 메시지를 보내거나 kafka에 도착한 메시지를 원하는 플랫폼으로 보내도록 할 수 있습니다.
Kafka 데이터를 MySQL 데이터베이스로 실시간으로 동기화하는 방법을 알아보겠습니다.
🎃MySQL Kafka Connect 커넥터 구성
Config 설정
MySQLConfig 클래스는 데이터베이스 연결에 필요한 구성 요소들을 정의합니다. 이 구성에는 데이터베이스의 연결 URL, 사용자 이름 및 비밀번호가 포함됩니다.
public class MySQLConfig extends AbstractConfig {
public static final String CONNECTION_URL_CONFIG = "connection.url";
public static final String CONNECTION_USER_CONFIG = "connection.username";
public static final String CONNECTION_PASSWORD_CONFIG = "connection.password";
public MySQLConfig(Map<?, ?> originals) {
super(config(), originals);
}
public static ConfigDef config() {
return new ConfigDef()
.define(CONNECTION_URL_CONFIG, ConfigDef.Type.STRING, ConfigDef.Importance.HIGH, "The JDBC connection URL for the MySQL database.")
.define(CONNECTION_USER_CONFIG, ConfigDef.Type.STRING, ConfigDef.Importance.HIGH, "The username for the MySQL database connection.")
.define(CONNECTION_PASSWORD_CONFIG, ConfigDef.Type.PASSWORD, ConfigDef.Importance.HIGH, "The password for the MySQL database connection.");
}
}SinkConnector
MySQLSinkConnector 클래스는 Kafka Connect Sink Connector의 주요 구성 요소를 설정합니다. 해당 클래스는 커넥터가 시작될 때 필요한 구성을 로드하고, 데이터 처리 작업을 위한 SinkTask 클래스를 지정합니다.
public class MySQLSinkConnector extends SinkConnector {
private Map<String, String> configProperties;
@Override
public void start(Map<String, String> props) {
this.configProperties = props;
try {
new MySQLConfig(props);
} catch (ConfigException e) {
throw new ConfigException(e.getMessage(), e);
}
}
@Override
public Class<? extends Task> taskClass() {
return MySQLTask.class;
}
@Override
public List<Map<String, String>> taskConfigs(int maxTasks) {
List<Map<String, String>> configs = new ArrayList<>();
HashMap<String, String> taskConfig = new HashMap<>(configProperties);
for (int i = 0; i < maxTasks; i++) {
configs.add(taskConfig);
}
return configs;
}
@Override
public void stop() {
}
@Override
public ConfigDef config() {
return MySQLConfig.config();
}
@Override
public String version() {
return "1.0";
}
}start를 통해 connect 시작시 필요한 설정파일을 저장합니다. 아래의new MySQLConfig(props);는 설정파일을 검사하는 용도입니다.taskClass를 통해 실제 작업을 진행하는 클래스를 지정해줍니다.taskConfigs는 task별로 설정파일을 지정해 줄 수 있는데 여기서는 모두 통일 시켜서 넣어주었습니다.config는 설정파일을 지정해주는 작업입니다.version버전을 지정해면 됩니다. task와 동일하게 해주시는 편이 좋습니다.
SinkTask
MySQLTask 클래스는 실제 데이터베이스 작업을 수행합니다. 이 클래스는 데이터베이스에 연결을 생성하고, Kafka로부터 받은 데이터를 MySQL 데이터베이스에 삽입합니다.
public class MySQLTask extends SinkTask {
private Connection connection;
@Override
public String version() {
return "1.0";
}
@Override
public void start(Map<String, String> map) {
String url = map.get("connection.url");
String username = map.get("connection.username");
String password = map.get("connection.password");
try {
this.connection = DriverManager.getConnection(url, username, password);
} catch (SQLException e) {
throw new RuntimeException("Failed to open connection to MySQL", e);
}
}
@Override
public void put(Collection<SinkRecord> records) {
if (records.isEmpty()) {
return;
}
String sql = "INSERT INTO Member (username, age) values (?, ?)";
try (PreparedStatement stmt = connection.prepareStatement(sql)) {
for (SinkRecord record :
records) {
Map<String, Object> valueMap = (Map<String, Object>)record.value();
String username = (String)valueMap.get("username");
long age = Long.parseLong(String.valueOf(valueMap.get("age")));
stmt.setString(1, username);
stmt.setLong(2, age);
stmt.addBatch();
}
stmt.executeBatch();
} catch (Exception e) {
throw new RuntimeException("Failed to write to MySQL", e);
}
}
@Override
public void stop() {
try {
if (connection != null) {
connection.close();
}
} catch (Exception e) {
throw new RuntimeException("Error while closing MySQL connection", e);
}
}
}start작업전에 필요한 설정값이나 연결 등을 진행해주면 됩니다.put을 통해 실제 어느 작업을 진행할 것인지를 설정해주면 됩니다.stop종료시에 할 작업을 지정해주시면 됩니다. 여기서는 mysql연결을 해제해주었습니다.
정말 간단한 insert를 만든 것이므로 알맞게 수정하시면 될 것 같습니다.
gradle
dependencies {
implementation 'org.apache.kafka:connect-api:3.0.2'
implementation 'com.mysql:mysql-connector-j:8.4.0'
}
java {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
jar {
duplicatesStrategy = DuplicatesStrategy.EXCLUDE
from {
configurations.runtimeClasspath.collect { it.isDirectory() ? it : zipTree(it) }
}
}- 필요한 의존성을 주입받아주시면 됩니다. 특히 버전의 경우를 잘 맞춰주셔야 합니다.(버전때문에 계속 에러가 나서...)
- java version의 경우도 사용할 kafka에 맞게 설정해주시면 됩니다.
- jar의 경우 fat-jar로 만들어야 하기 때문에 위와 같이 설정하였습니다.
🚩connect 실행
docker compose
mysql, kafka, kafka-connect 등이 필요하기에 docker-compose를 이용하였습니다.
version: '3.7'
services:
zookeeper:
image: docker.io/bitnami/zookeeper:3.9
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka-ui:
image: provectuslabs/kafka-ui
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka1:29092
- KAFKA_CLUSTERS_0_ZOOKEEPER=zookeeper:2181
ports:
- "9090:8080"
kafka1:
image: confluentinc/cp-kafka:7.0.1
container_name: kafka1
ports:
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092,PLAINTEXT_INTERNAL://kafka1:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
connector:
image: confluentinc/cp-kafka-connect:7.0.1
ports:
- 8083:8083
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka1:29092
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: "quickstart-avro"
CONNECT_CONFIG_STORAGE_TOPIC: "quickstart-avro-config"
CONNECT_OFFSET_STORAGE_TOPIC: "quickstart-avro-offsets"
CONNECT_STATUS_STORAGE_TOPIC: "quickstart-avro-status"
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_REST_ADVERTISED_HOST_NAME: "localhost"
CONNECT_LOG4J_ROOT_LOGLEVEL: INFO
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "false"
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "false"
CONNECT_PLUGIN_PATH: "/usr/share/java,/etc/kafka-connect/jars"
volumes:
- "./kafka-connect/jars:/etc/kafka-connect/jars"
depends_on:
- kafka1
mysql:
image: mysql:latest
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: 1234위 여러 설정값중에서 CONNECT_PLUGIN_PATH: "/usr/share/java,/etc/kafka-connect/jars"이 부분이 중요합니다.
해당 파일에 저희가 만든 jar를 넣어야 하기 때문에 volumes: - "./kafka-connect/jars:/etc/kafka-connect/jars"를 통해 mount를 해주었습니다.
connect를 실행할때 새로운 플러그인을 넣게 된다면 connector를 다시 재실행해주셔야 합니다.
connect 등록
kafka connect를 사용하기 위해서는 해당 요청을 rest api로 요청을 해야합니다.
아래의 순서로 요청을 해주시면 됩니다.
- 커넥터 생성 요청:
curl -X POST \
http://localhost:8083/connectors \
-H 'Content-Type: application/json' \
-d '{
"name": "my-mysql-connector", # 커넥터의 고유 이름 설정
"config": {
"connector.class": "com.example.MySQLSinkConnector", # MySQLSinkConnector 클래스 지정
"tasks.max": "1", # 최대 작업 수 설정
"topics": "test", # 연결할 Kafka 토픽 지정
"connection.url": "jdbc:mysql://{database ip}/{database schema}?useSSL=false&serverTimezone=UTC", # MySQL 데이터베이스의 URL 설정
"connection.username": "root", # MySQL 데이터베이스에 접속할 사용자 이름
"connection.password": "1234", # MySQL 데이터베이스에 접속할 사용자 비밀번호
"auto.create": "true" # 필요한 경우 테이블 자동 생성 설정
}
}'
- 생성된 커넥터의 상태 확인 요청:
curl -X GET http://localhost:8083/connectors/my-mysql-connector/status등록한 connector의 상황을 확인할 수 있습니다.
🔍테스트
직접 kafka-topic.sh를 통해서 메시지를 날려도 되지만 위 도커 컴포즈를 통해 띄운 kafka-ui를 통해 메시지를 보내보겠습니다.
만약 데이터베이스에 테이블을 만들지 않았다면 먼저 만들어주셔야합니다.
테이블 생성
create schema TEST_CONNECT;
use TEST_CONNECT;
create table Member (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(40),
age BIGINT # <- long관련 에러가 나서 그냥 bigint로 해주었습니다...
);
select * from Member;produce
- Produce 스크린샷
- 기존 상태
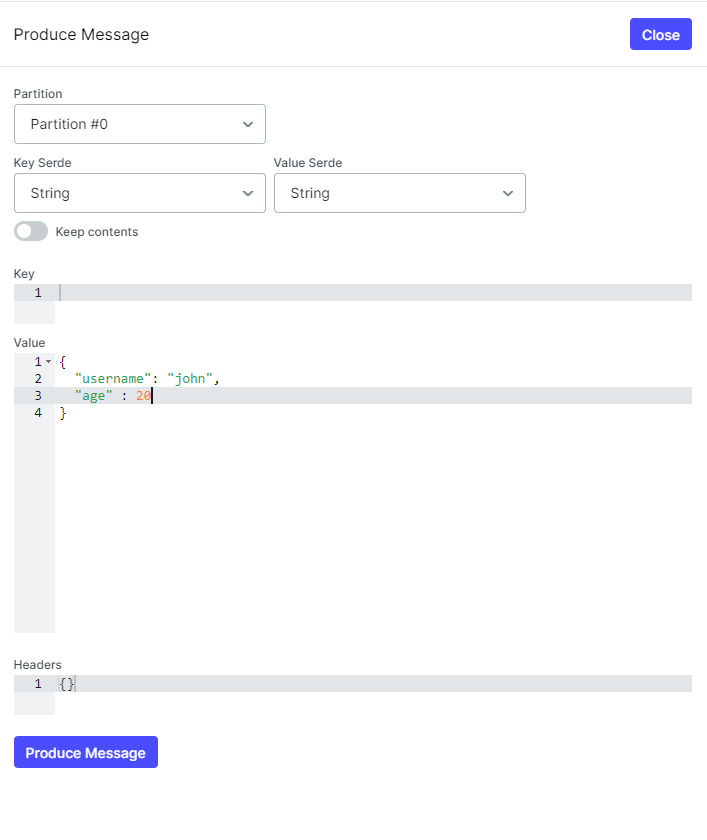
- produce
- topic에 메시지가 발행됨
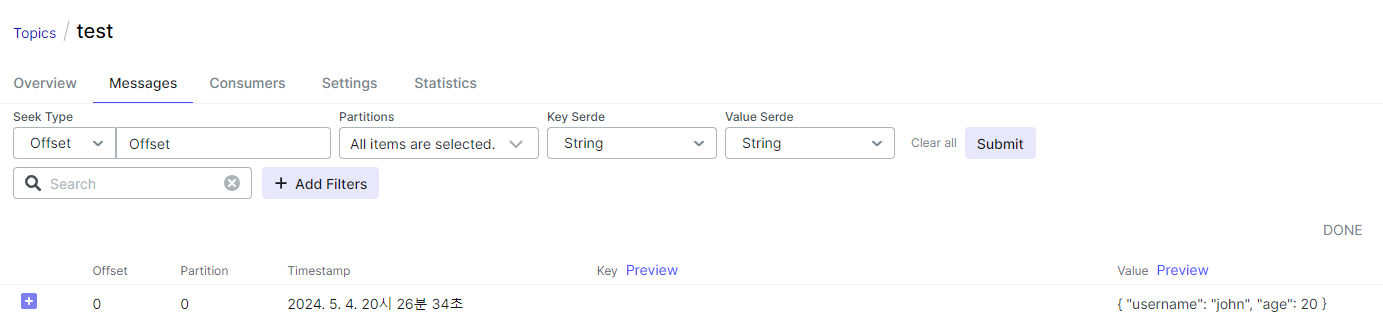
Kafka Producer가 JSON 형식의 데이터를 생성하여 Kafka topic으로 전송하는 모습입니다. 아래의 데이터를 test topic으로 발행하였습니다.
{
"username": "john",
"age": 20
}- MySQL 데이터베이스 확인
select * from Member; 실행시
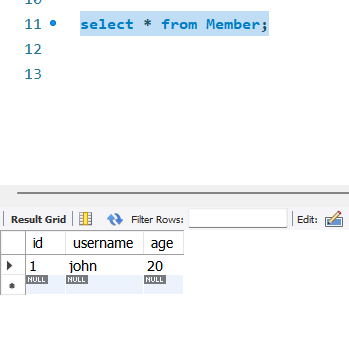
- Kafka를 통해 전송된 데이터가 성공적으로 MySQL 데이터베이스의 Member 테이블에 삽입된 것을 확인할 수 있습니다.
👽마무리
Kafka Connect는 데이터 플랫폼의 핵심 요소 중 하나로, 기존의 Consume API를 활용하는 방법에 비해 데이터 소스 및 대상 간의 연결을 쉽게 설정하고 관리할 수 있는 장점이 있습니다. 이를 통해 실시간 데이터 스트리밍 및 ETL(Extract, Transform, Load) 작업을 효율적으로 수행할 수 있습니다.
Kafka Connect는 많은 유형의 커넥터를 제공하며, 이를 통해 다양한 데이터 소스 및 대상 간의 연결을 지원합니다. 예를 들어, S3 커넥터를 사용하면 Kafka에서 S3로 데이터를 쉽게 전송할 수 있으며, MySQL 커넥터를 사용하면 Kafka 데이터를 MySQL 데이터베이스에 쉽게 적재할 수 있습니다. 또한 MongoDB, Elasticsearch, HDFS 등 다양한 커넥터가 제공되므로 필요에 따라 선택하여 사용할 수 있습니다.
이러한 다양한 커넥터를 통해 Kafka Connect는 데이터 파이프라인을 쉽게 구축할 수 있으며 커스텀 커넥터를 개발하여 특정 요구 사항에 맞게 확장할 수도 있습니다.
참고자료
Confluent Documentation
[Kafka KRU] 2023 스터디 후기 및 커스텀 카프카 커넥터 만들기 - DEVOCEAN
kafka db connector 연동 (feat. mysql) - 코딩하는주노
만약 문제가 발생하다면 버전을 확인해보시면 될 것 같습니다.
