스파르타 코딩 2주차 WIL
자료구조
자료구조는 크게 메모리 공간 기반의 연속 방식과 포인터 기반의 연결 방식으로 나뉜다.
- 메모리 공간 기반의 연속 방식(continuous)을 대표하는 자료형 - 배열
- 포인터 기반의 연결 방식(Link)의 기본이 되는 자료형 - 연결 리스트
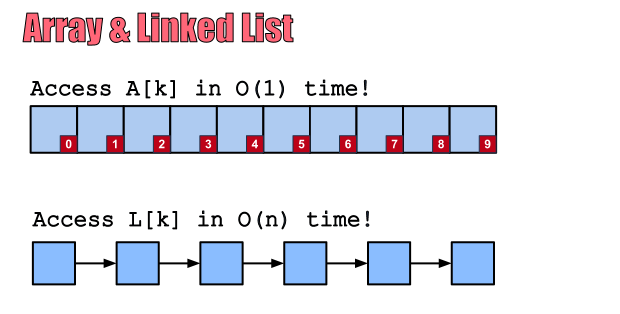
_메모리 측면에서 본 배열와 연결 리스트_
위 그림에서 보이듯이 배열은 생성시 정해진 메모리를 할당하기 때문에,
데이터 추가 시 모든 공간이 다 차버렸다면, 새로운 메모리 공간을 할당 받아야한다.
연결 리스트는 메모리를 정해놓고 사용하는 것이 아닌,
데이터를 추가할 때 마다 메모리를 할당받아 포인터로 연결하는 식이기에
메모리 사용이 유동적이다.배열(List) []
index로 지정된 데이터를 구분하고, index는 0~n으로 끊기지 않는 자연수를 갖는다.
모든 데이터를 탐색하는 작업은 O(n)인 시간복잡도가 납득이 간다.
하지만, 간단해 보이는 기능인데도 index를 사용하는 배열의 구조상,
모든 데이터를 업데이트 해야하는 작업들이 있다.
주의해서 사용해야하는 배열의 기능들 (시간 복잡도⬆)
List.pop(0) - O(n)
- 배열의 첫번째 요소를 삭제하고 반환한다.
- index 0이 사라지므로, index 1을 0으로, 2를 1로... 모든 n개의 요소를 앞으로 당긴다.
같은 이유로 List.insert(0,값), del List[0], List.remove(값)과 같은 기능들은 모두 O(n)
부담없게 사용해도 되는 배열의 기능들
특정 원소 탐색List[i], 리스트 삭제(List = [] or List.clear() 하거나,
리스트의 마지막을 조작하는 List.append(값),List.pop(-1)``len(List)와 같은 기능들은
O(1)이다.
.pop(0)이 필요한 경우에는 deque를 사용하자
리스트를 딕셔너리로 바꿔 작업하는 방법도 있다.배열의 sort(정렬)은 O(nlogn)의 시간복잡도를 가진다
ps. 시간 복잡도의 log는 상용로그가 아닌 밑 (base)가 2인 로그함수이다
연결 리스트 (Linked List)
배열과 함께 가장 기본이 되는 대표적인 선형 자료구조 중 하나
데이터가 값과 포인터로 이루어져 있어, 포인터로 다른 데이터를 가리킨다.
동적으로 새로운 노드를 삽입하거나 삭제하기가 간편하다.
하지만, 구조상 특정 요소를 탐색하는것이 시간복잡도가 높다.
파이썬으로 알고리즘을 구현할 때 연결 리스트를 따로 구현해서 사용하지는 않는다.
대신 배열을 사용한다.
스택 (Stack)
후입선출, FILO(First In Last Out)의 자료구조
컴퓨터의 되돌리기 기능(Ctrl + z)이나 웹 브라우저의 뒤로 가기를 생각하면 된다.
역순 문자열 만들기와 괄호 검사와 같은 문제를 해결하기 좋다.
키보드로 글자를 치면서 백 스페이스만을 이용해서 글자들을 지운다면,
지워지는 글자들의 순서는 후입선출일 것이다.
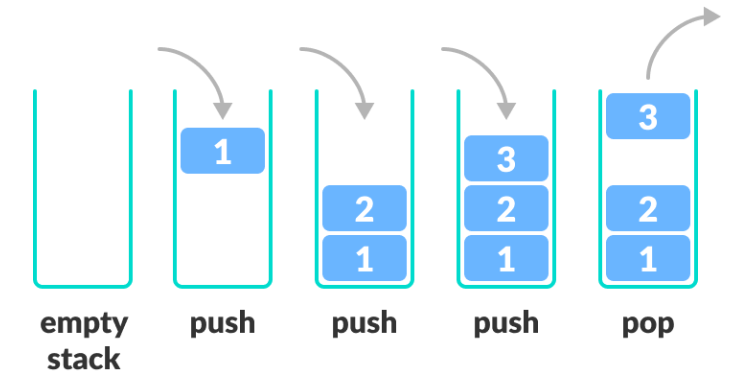
정해진 한 곳(top)을 통해서 데이터의 삽입과 삭제가 이루어진다.큐 (Queue)
선입선출, FIFO(First In First Out)의 자료구조
놀이동산에서 줄을 서서 기다리는 것을 생각하면 된다.
주로 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있는 상황에 이용한다.
프린터의 인쇄 대기열, 프로세스 관리와 같은 문제를 해결하기 좋다.

한 쪽 (front)에서는 데이터를 삽입만 하고, 다른 쪽 (rear)에선 데이터를 삭제만 하는 구조이다.해시 테이블 (Hash Table)
Key.Value System의 자료구조
키를 값에 매핑할 수 있는 구조이다. (파이썬에선 딕셔너리가 해당 된다)
해시 테이블의 핵심은 해시 함수이다.
해시 함수는 임의 크기 데이터를 고정 크기 값으로 매핑하는데 사용하는 함수를 말한다.
해시 함수로 해시 테이블을 인덱싱하는 것을 해싱(Hashing)이라 하며,
해싱은 정보를 빠르게 저장하고 검색하기 위해 사용하는 중요한 기법 중 하나다.
my) 쉽게 생각하면, index가 key인 배열이다.
하지만, index가 데이터적 효용이 거의 없는 위치값이라면
key는 데이터적 효용이 굉장히 많아서 해시 테이블을 쓰는 이유의 전부가 된다
알고리즘
그래프
연결되어 있는 정점과 정점간의 관계를 표현할 수 있는 자료구조
비선형 자료구조로써 (여태까지 배운) 선형구조와 다르게 표현에 초점이 맞춰져 있음
(선형구조는 자료를 저장하고 꺼내는 것에 초점이 맞춰져 있다)
유방향 그래프 와 무방향 그래프가 있다.
표현 방법은 두 가지 가 있다.
1. 인접 행렬 (2차원 배열로 그래프의 연결 관계 표현)
2. 인접 리스트 (링크드 리스트로 그래프의 연결 관계를 표현)
- 노드(Node)
- 연결 관계를 가진 각 데이터를 의미, 정점(Vertex)라고도 함
- 간선(Edge)
- 노드 간의 관계를 표시한 선
- 인접노드(Adjacent Node)
- 간선으로 직접 연결된 노드(또는 정점)
DFS
DFS [ Depth First Search ] - 깊이 우선 탐색
갈 수 있는 만큼 계속해서 탐색하다가 갈 수 없게 되면 다른 방향으로 다시 탐색하는 구조
구현 방법은 두 가지가 있다.
1. 스택 자료구조를 이용
2. 재귀함수 이용
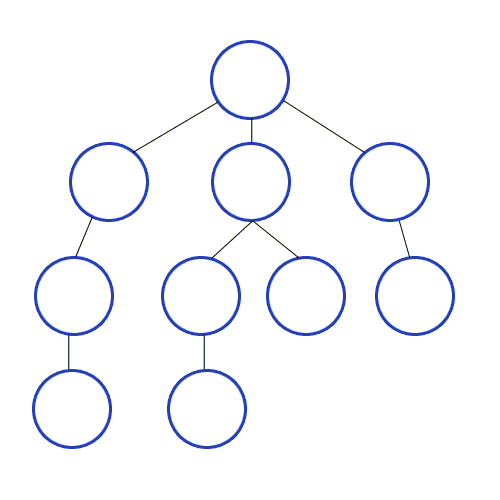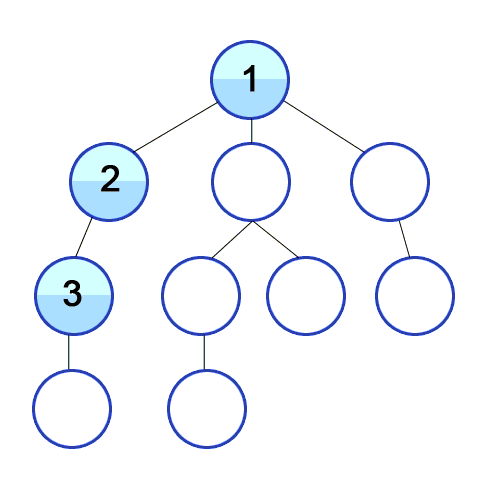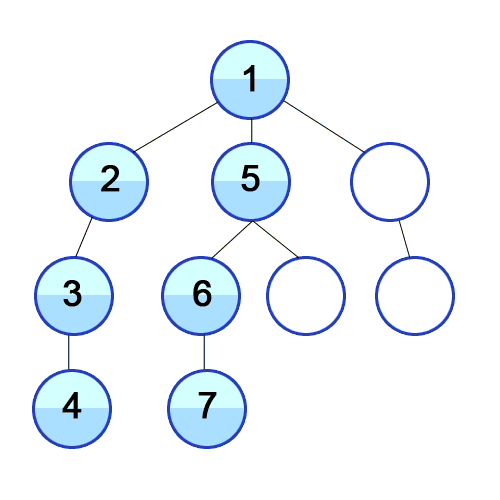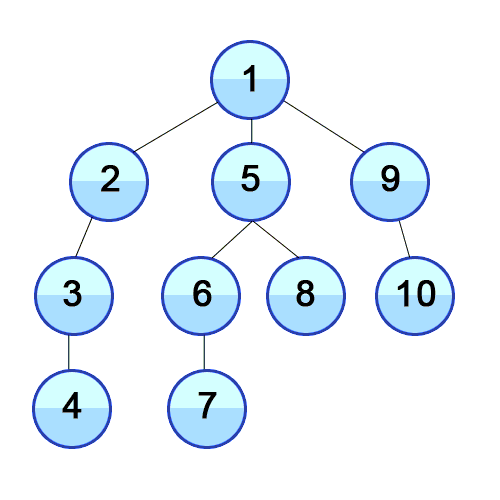
- 노드를 방문하고 깊이 우선으로 인접한 노드를 방문한다
- 또 그 노드를 방문해서 깊이 우선으로 인접한 노드를 방문한다
- 위 과정을 반복한다.
BFS
BFS [ Breath First Search ] - 너비 우선 탐색
구현 방법
큐 자료구조를 이용
BFS와 DFS의 차이
DFS 는 탐색하는 원소를 최대한 깊게 따라가야 합니다.
이를 구현하기 위해 인접한 노드 중 방문하지 않은 모든 노드들을 저장해두고,
가장 마지막에 넣은 노드를 꺼내서 탐색하면 됩니다. → 그래서 스택을 이용해서 DFS 구현
BFS 는 현재 인접한 노드 먼저 방문해야 합니다.
이걸 다시 말하면 인접한 노드 중 방문하지 않은 모든 노드들을 저장해두고,
가장 처음에 넣은 노드를 꺼내서 탐색하면 됩니다. → 큐를 이용해서 BFS 구현
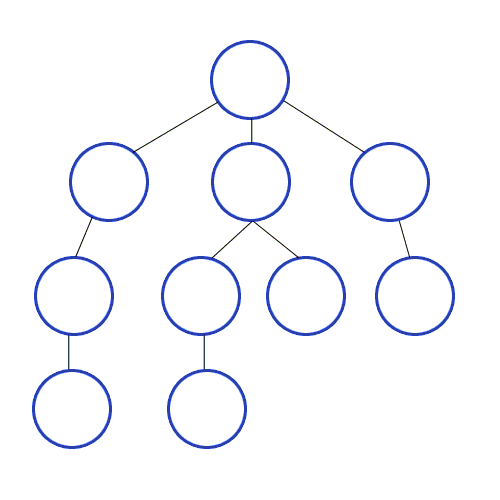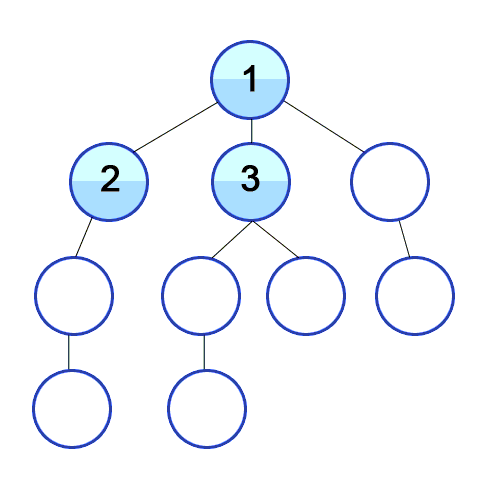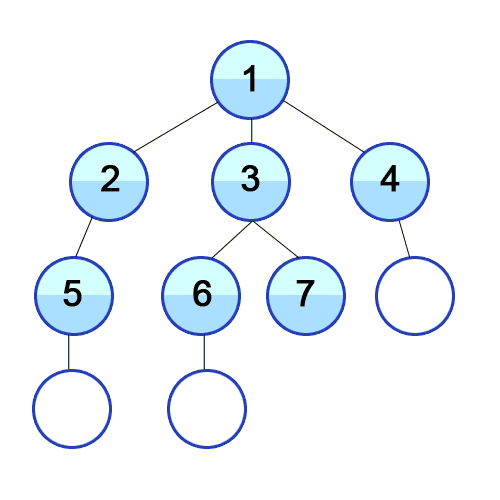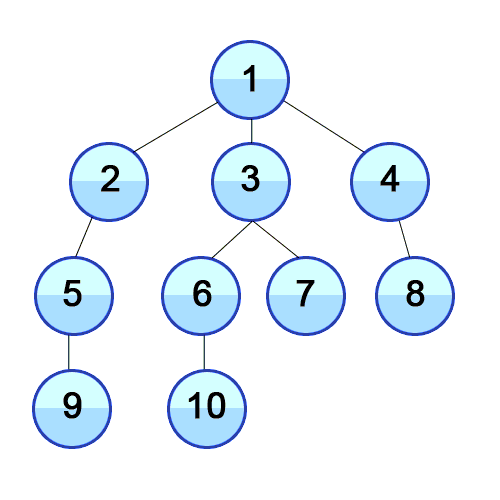
- 루트 노드를 큐에 넣습니다.
- 현재 큐의 노드를 빼서 visited 에 추가한다.
- 현재 방문한 노드와 인접한 노드 중 방문하지 않은 노드를 큐에 추가한다.
- 2부터 반복한다.
- 큐가 비면 탐색을 종료한다.
