1. 함수
1-1. 단일행 함수
NVL(null value) : default 값 지정
1-2. 복수행 함수
여러 개의 행에 하나의 값을 반환
- select 에서 단일행, 복수행을 동시에 조회할 수는 없음 -> group by 사용
- count , sum, avg, max, min : null을 세지 않음 -> 만약 계산이 필요하다면 null값을 처리해야 함
- group by : ~별
1-3. 복수행 문제 - emp, dept
-
급여가 1000이상인 사원들의 부서별 평균 급여의 반올림 값을 부서번호로 내림차순 정렬해서 출력하기
select deptno,round(avg(sal)) avg_sal from emp where sal>=1000 group by deptno order by avg_sal descwhere :필요없는 row 는 배제시킴
having : 필요없는 그룹을 배제시킴 -
급여가 2000이상인 사원들의 부서별 평균 급여의 반올림 값을 평균 급여의 반올림 값으로 오름차순 정렬해서 출력하기
select deptno,round(avg(sal)) avg_sal
from emp
where sal>=2000
group by deptno
order by avg_sal- 각 부서별 같은 업무(job)사람의 인원수를 구해서
-부서번호별, 업무(job),인원수를 부서번호에 대해서
-오름차순 정렬해서 출려하기
select deptno,job,count(*) result
from emp
group by deptno,job --부서별로 더 세분화 했기에 그룹이 많아질 수 밖에
order by deptno asc- 급여가 1000이상인 사원들의 부서별 평균 급여를 출려해보기
-단, 부서별 평균 급여가 2000 이상인 부서만 출력하기
select deptno,avg(sal)
from emp
where sal>=1000
group by deptno
having avg(sal)>=2000 --특정 그룹을 배제시킴1-3. 조인
- 모든 사원들의 이름과 부서번호,부서명을 출력하기
조건을 주지 않으면 가능한 모든 조합(경우)를 연결시킴(124)
select ename,emp.deptno,dept.deptno,dname
from emp,dept
where emp.deptno = dept.deptno --=>모든 경우에서 남길 행을 생각...- <조인조건 + 일반조건>
급여가 3000에서 5000 사이의 사원이름과 부서명을 출력해보기
select ename,dname
from emp,dept
where (emp.deptno=dept.deptno) and (sal between 3000 and 5000)- 부서명이 'ACCOUNTING' 인 사원의 이름, 입사일, 부서번호,부서명을 출력하기
select ename,hiredate,dept.deptno,dname
from emp,dept
where emp.deptno=dept.deptno and dname='ACCOUNTING';<ANSI 조인>
- 부서명이 'ACCOUNTING' 인 사원의 이름, 입사일, 부서번호,부서명을 출력하기
select ename,hiredate,emp.deptno,dname
from emp
inner join dept on emp.deptno =dept.deptno
where dname='ACCOUNTING';<테이블 별칭>
select ename,hiredate,d.deptno,dname
from emp e, dept d
where e.deptno = d.deptno and dname='ACCOUNTING'- 성과급이 null이 아닌 사원의 이름, 입사일, 부서명을 출력해 보시오
일반 join, ansi join 둘다 작성해 보세요
<일반조인>
select ename,hiredate,dname
from emp e, dept d
where (e.deptno= d.deptno) and (comm is not null);<anisi 조인>
select ename,hiredate,dname
from emp e
inner join dept d on e.deptno=d.deptno
where comm is not null;- 각 사원의 이름과 매니저의 이름을 출력해보세요(MGR 상사의 이름)
select e.ename,e1.ename
from emp e, emp e1
where e.mgr=e1.empno;select e.ename,e1.ename
form emp e
join emp e1 on e.mgr=e2.empno;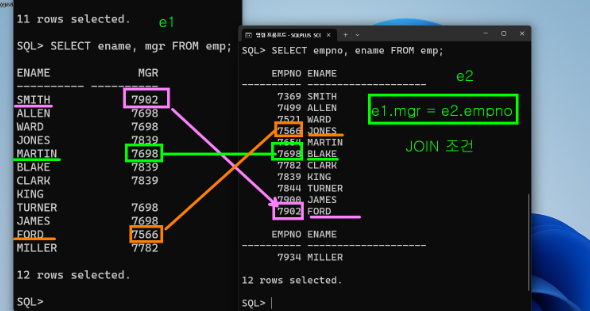
- 각 사원의 이름과 매니저의 이름을 하나의 문자열로 출력해 보세요
--ford 의 매니저는 jones
--james의 매니저는 blake
select (e1.ename|| '의 매니저는 '|| e.ename) info
from emp e
inner join emp e1 on e.empno =e1.mgr;- <left outer join: oracle의 +기호 사용하기>
select e.ename,e1.ename
from emp e, emp e1
where e.mgr =e1.empno(+);select e.ename,e1.ename
from emp e
left outer join emp e1 on e.mgr=e1.empno;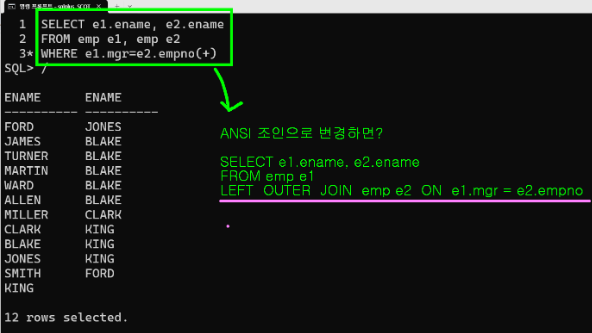
- <null인 값 X로 표시하기>
select e.ename,nvl(e1.ename,'X') ename
from emp e
left outer join emp e1 on e.mgr=e1.empno- 사원번호, 부서번호,부서명을 출력하세요.
--단, 사원이 근무하지 않는 부서명도 같이 출력해보세요(오른쪽이 튀어나오게 끔)
select empno, d.deptno, dname
from emp e
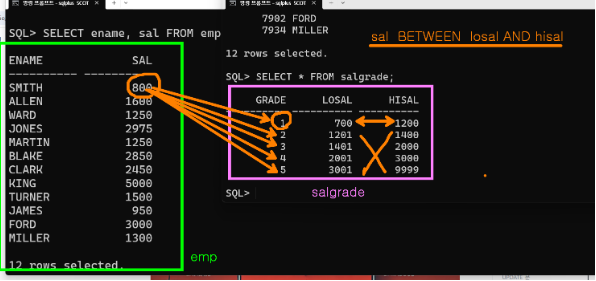
join dept d on e.deptno(+)=d.deptno;- 사원의 이름과 급여, 급여의 등급을 출력해 보세요.
select ename,sal,grade
from emp
inner join salgrade on sal between losal and hisal;- 사원의 이름, 부서명, 급여의 등급을 출력해 보세요.
select ename,dname,grade
from emp e,dept d,salgrade
where e.deptno=d.deptno
and sal between losal and hisal;select ename,dname,grade
from emp
join dept on emp.deptno=dept.deptno
join salgrade on sal between losal and hisal;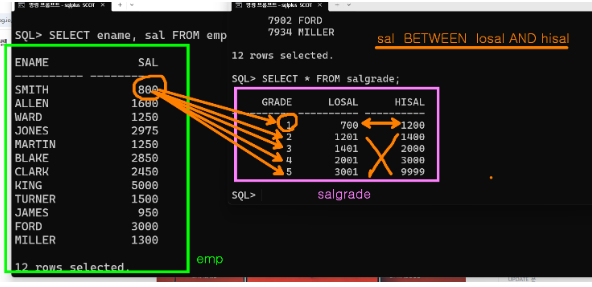
- smith가 근무하는 부서의 이름을 출력해 보세요.
select dname
from emp
join dept on emp.deptno=dept.deptno
where ename='SMITH';<서브쿼리>
select dname
from dept
where deptno = (select deptno from emp where ename='SMITH'); -- 단 row가 반드시 하나여야만 한다
- 'ALLEN'과 같은 부서에서 근무하는 사원의 이름과 부서번호를 출력하세요.
select ename,deptno
from emp
where deptno=(select deptno from emp where ename='ALLEN')- ALLEN과 동일한 직책(job)을 가진 사원의 사번과 이름, 직책을 출력해 보세요
select empno,ename,job
from emp
where job =(select job from emp where ename='ALLEN');- sales 부서에서 근무하는 모든 사원의 이름과 급여를 출력해 보세요
SELECT ename, sal
FROM emp
JOIN dept ON emp.deptno = dept.deptno
WHERE emp.deptno = (
SELECT dept.deptno
FROM dept
WHERE dname = 'SALES'
);select ename,sal
from emp
where deptno=(select deptno from dept where dname='SALES');교훈: SELECT에서 필요한 값이 특정 테이블에만 있다면, 굳이 JOIN을 사용하지 않아도 된다.
특히, 조건만 다른 테이블에서 가져올 수 있다면 서브쿼리를 사용하여 원하는 조건을 설정하고, 데이터를 직접 가져오는 것이 더 간단하고 효율적
1-4. 왜 테이블을 분리해서 관리하는가 ?
한 번에 모두 관리하면 데이터 관리의 효율성이 떨어짐
(변경, 메모리 과다 등...) ==>join이 나온 이유
2. 정호T 정리사항
(velog의 복수행 설명+코드 실행)
<질문>
부서명이 'ACCOUNTING' 인 사원의 이름, 입사일, 부서번호,부서명을 출력하기
select dname # 부서명만 대표할 수 있는 것만 조회할 수 있다!
from emp e,dept d
where e.deptno=d.deptno
group by dname
having dname='ACCOUNTING';
->group by를 묶는 기준에
dname으로 그룹을 묶었기에 select에는 dname과 dname을 대표하는 sum, sal,count와 같은 집계함수만 나올 수 있음!
<보완점>
-
함수를 바라보는 관점? 함수가 반환하는 값으로 대체
-
오라클에서 함수 안에 값 전달이 없으면 아예 괄호를 생략
-
식별자(테이블명, 칼럼명, 계정명, 시퀀스명...)은 대소문자를 가리지 않음
-
DB에서 데이터를 잘 뽑아야지 아니면 프로그래밍 언어에서 처리해야 함
-
where :필요없는 row 는 배제시킴
-
having : 필요없는 그룹을 배제시킴
