Lock-Based Protocol
lock은 data에 대한 concurrent한 access를 control하기 위한 mechanism
Data item은 두 가지 lock을 가질 수 있음
1. exclusive(X) lock: read/write 둘 다 가능 lock-X instruction으로 요청
2. shared(S) lock: read만 가능 lock-S로 요청
Lock request는 concurrency control manager에 의해 수행됨
Transaction은 request가 받아들여져야 계속해서 진행 가능
Lock-compatibility matrix
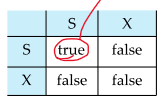
shared lock만 한번에 다수의 transaction들이 가질 수 있음
Deadlock
Deadlock 발생조건
- Mutual exclusion: 자원 공유 불가능
- Hold and Wait: 자원을 점유하면서 다른 자원 대기
- No preemption: 점유하고 있는 자원을 빼았아올 수 없음
- Circular wait: 서로의 것을 순환적으로 대기
대부분의 locking protocol에서 deadlock은 존재
Starvation(무한 대기)또한 발생 가능
Two-Phase Locking Protocol
conflict serializable 보장
Phase 1: Growing Phase
- lock 획득 가능
- lock release 불가능
Phase 2: Shrinking Phase
- lock release 가능
- lock 획득 불가능
2PL이 conflict-serializable을 보장하기는 하지만, conflict-serializable이려면 반드시 2PL이 필요한 것은 아님
recoverability보장을 위한 2PL의 확장
Strict 2PL: transaction은 commit/abort되기 전에는 모든 exclusive lock을 들고 있어야 함
Rigorous 2PL: transaction은 commit/abort되기 전에는 모든 lock을 들고 있어야 함
- commit 순서로 serialize 가능
- recoverability, no cascading roll back 보장
대부분 Rigorous 2PL을 사용 -> 기본적으로 2PL이라하면 이거임
2PL은 deadlock이 없음을 보장하지 않음
Lock Conversion
Growing Phase
- grant lock-S
- grant lock-X
- convert lock-S to lock-X (upgrade)
Shrinking phase
- release lock-S
- release lock-X
- convert lock-X to lock-S (downgrade)
여전히 serializability 보장
Implementation of Locking
lock manager는 별개의 process로 구현
transaction은 lock, unlock request를 message로 전송
lock manager는 lock grant message를 전송함으로서 lock request에 응답
lock manager는 lock table로 lock 관리
Lock Table
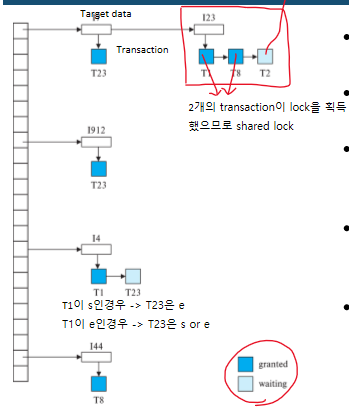
각 데이터에 접근하는 transaction들에 대한 lock상태를 표시
새 request는 data의 transaction queue에 끝에 삽입됨
transaction이 abort되면 해당 queue의 모든 transaction이 삭제됨
Graph-based Protocol
2PL의 대안
data item set에 partial ordering을 붙여 locking 순서를 지정
- di->dj이면 di, dj에 접근하는 transaction은 반드시 해당 순서로 data에 접근해야함
- 이러한 data item set을 directed acyclic graph로 나타낸 것을 database graph라고 함
Tree Protocol
exclusive lock만 허용
첫번째 lock은 아무 data item이나 가능
data Q의 lock을 얻으려면 database graph상의 Q의 모든 부모의 lock을 가지고 있어야 됨
unlock은 언제든지 가능
unlock한 data에 대한 lock을 바로 다시 잡을 수 없음
Tree protocol은 conflict serializability와 deadlock free를 보장
tree protocol은 2PL보다 unlock timing이 빠름
- 저 짧은 waiting time, concurrency 증가
- deadlock-free이므로 rollback도 안 일어남
결점
- recoverability, cascade free 보장 안함
- transaction이 접근할 필요가 없는 data의 lock을 얻어야 함(접근하는 data의 모든 부모의 lock을 얻어야 하므로)
2PL로 schedule이 불가능한 schedule이 tree에서는 가능, 그 역도 성립
Deadlock Prevention
Deadlock에 빠지지 않는 것을 보장
다음과 같은 전략이 있음
- 실행하기 전에 사용하는 모든 data에 대한 lock 요청
- graph-based protocol
wait-die scheme - non-preemptive
- 오래된 transaction은 더 최신의 transaction이 data item을 release할 때 까지 기다림
- 최신 transaction은 오래된 transaction의 release를 기다리지 않음 -> 즉시 roll back함
- transaction은 lock을 얻기 전, 몇 번 죽게 됨
wound-wait scheme - preemptive
- 오래된 transaction은 최신 transaction을 강제 roll back 시킴 (기다려주지 않음)
- 최신 transaction은 오래된 transaction의 release를 기다림
- wait-die보다 roll back이 적음
Timeout-based scheme
- transaction은 lock을 특정 시간 만큼만 기다림, time out되면 roll back
- deadlock은 timeout으로 해결
- 구현이 간단
- deadlock이 아닌데도 roll back이 발생할 수 있음
- 적당한 time interval을 설정하는게 어려움
- starvation또한 발생 가능
Deadlock Detection
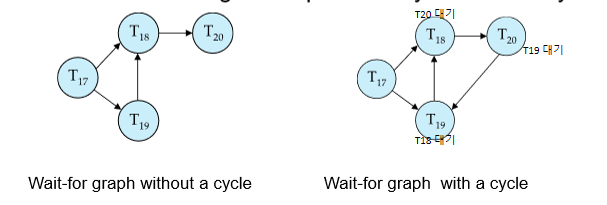
Wait-for graph
vertex: transaction
edge from Ti->Tj: Ti가 Tj가 들고있는 lock을 대기
wait-for graph에 cycle이 있으면 deadlock이 발생
Deadlock Recovery
몇몇 transaction을 roll back 시킴
얼만큼 roll back 시킬지
- total roll back: transaction을 abort시키고 재시작
- partial roll back: circuler하게 wait하는 부분만 roll back
Starvation 해결-가장 오래된 transaction은 roll back되지 않도록 함
Multiple Granularity
lock을 잡는 범위와 concurrency는 반비례
Fine granularity(lower in tree): high concurrency, high locking overhead
Coarse granularity(higher in tree): lower locking overhead, low concurrency
Granularity Hierarchy
tree의 top level에서부터 DB-area-file-record
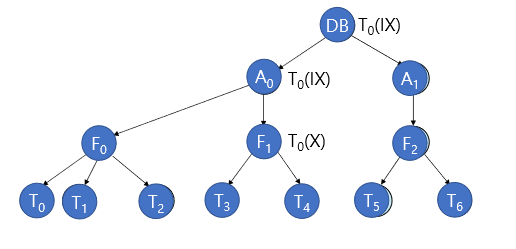
Intention Lock Modes
S, X lock 말고도 granularity를 반영한 lock mode들이 있음
- intention-shared(IS): lower level tree가 shared lock이 있음
- intention-exclusive(IX): lower level tree에 exclusive lock이 있음(shared도 같이 있어도 됨)
- shared and intention-exclusive(SIX): 해당 node에 shared lock이 걸려 있고 하위 노드에 exclusive lock이 존재함(S + IX인 상태)
Compatibility Matrix with Intention Lock Modes
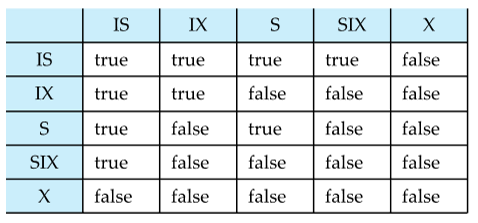
Multiple Granularity Locking Scheme
Ti가 node Q에 lock을 얻으려면 다음과 같은 규칙을 따름
1. lock compatibility matrix 확인
2. root가 가장 먼저 look 되어야 함
3. 그 전에 Ti가 Q의 부모노드의 IX 또는 IS lock을 얻었어야 S나 IS 가능
4. 그 전에 Ti가 Q의 부모노드의 SIX, IX lock을 얻었어야 IX, SIX, X 가능
5. Ti는 이전에 unlock되지 않은 node만 lock 가능(2PL)
6. Ti는 이전에 Q의 child들에게 lock을 걸지 않았을 때만 Q unlock 가능
lock 걸기는 root -> leaf 순으로
unlock은 leaf -> root 순으로
Insert/Delete Operations and Predicate reads
insert/delete operation의 규칙
- item을 delete하기 전 exclusive lock을 얻어야 함
- transaction이 새 tuple을 insert하면 자동적으로 해당 tuple의 X-lock을 얻음
read/write는 delete와 conflict
inserted tuple은 해당 transaction이 commit되기 전까지 다른 transaction에서 접근 할 수 없음
Phantom Phenomenon
phantom phenomenon의 예시
T1이 relation에 대한 predicate read(scan)을 함
select count(*)
from instructor
where dept_name = 'Physics'그리고 T2는 tuple을 insert함 T1이 active된 동안에 (predicate read 이후)
insert into instructor values('1111', 'Feynman', 'Physics', 94000)tuple level에서의 lock만 사용하면, non-serializable함
Handling Phantom
data level의 conflict
- relation에 대한 predicate read or scanning은 relation이 포함한 tuple들에 대한 read
- insert/delete/update tuple은 같은 infomation을 update
- conflict는 탐지되어야 함(locking protocol등을 통해)
해결
- relation과 관련된 data item은 relation이 어떤 tuple을 포함하는지 표시
- insert/delete/update할 때, relation 전체에 lock
