Introduction to Relational Model
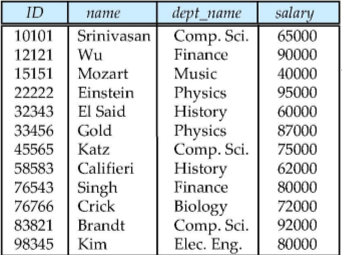
이렇게 Data를 정리해놓은 표를 relation이라고 함
각 colum을 attribute라고 하고
각 row를 tuple이라고 한다
attribute가 이라면 relation R은 으로 나타낼 수 있다
Database
DB는 여러개의 relation들로 구성됨
하나의 relation으로 모든 attribute를 때려 넣는것은 좋지 않음
why? <- 반복되는 정보나, null value가 필요해짐
Key
relation R에 포함된 attribute 혹은 attrubute의 집합 <- Key K라 하자
K를 가지고 R의 특정 tuple을 찾을 수 있으면 K를 R의 라고 함
superkey 중에서 가장 작은 key를 라고 함
relation의 candidate key중 하나를 선택해 로 정한다.
다른 relation에도 있는 key를 라고 한다.
Relational Operator
selection of tuples
특정 조건에 부합하는 tuple만이 결과로 나옴
예시) 하면 A와 B가 같고, D가 5 초과인 tuple만 결과로 반환됨
등의 비교연산자 사용 가능
Projection of attributes
relation에서 해당 attribute만 반환
예시)하면 r의 A, C attribute만 반환
Union of two relations
말 그대로 합집합 함
예시) (주의: 합치는 두 relation은 attribute가 일치해야 함)
Set difference of two relatios
이것도 말 그대로 차집합 함
예시) (이것도 두 relation의 attribute가 일치해야 함)
만약 s에 있는 tuple이 r에는 없다? -> 걍 무시됨
Set intersection of two relations
이것도 말 그대로 교집합 함
예시) (이것도 attribute 일치해야 함)
Cartesian product ( x )
두 relation의 tuple들을 조합할수 있는 모든 경우로 합쳐 반환
예시) r x s
r = ( A, B, C ) s = ( D, E )면, 결과 t = ( A, B, C, D, E ) 는 r, s의 tuple들의 모든 조합이 됨.
r의 tuple이 3개, s의 tuple이 4개였다면 t는 12개의 tuple을 가짐
Natural join
두 relation사이에 공통되는 attribute들의 값이 같은 tuple만을 가지고 cartesian product
예시)
r = ( A, B, C, D ) s = ( B, D, E ) 이면 B, D가 일치하는 tuple들로 catresian product 한 결과가 반환됨
Rename operation
말그대로 이름 바꿔 return
예시) 하면 relation E를 x로 rename
예시2) 하면 E를 x로, E의 각 attribute를 A1, A2, ..., An으로 rename
