
Lexical Analysis
- a=b+c를 a, =, b, +, c로 분석. token의 에러 검사
- 다음 토큰이 필요할때 파서가 호출하는 함수임
- Three approaches for building a lexical analyzer
- 1번: 소프트웨어 툴 이용
- 2번: state diagram그리고 diagram을 기반으로 lexical 분석
- 3번: state diagram그리고 diagram을 간략하게 한 것을 기반으로 lexical 분석
- 입력 스트링을 읽어서 토큰 형태로 분리하여 반환
Syntax Analysis = parser
- 해당 입력의 AST를 생성하여 반환, syntax error(문법) 검사
- lexical 분석기에서 token 넘겨주면 parser는 token을 받아서 abstract syntax tree그려서 semantics에게 넘겨줌
- AST: 추상 구문 트리, 입력 스트링의 구문 구조를 추상적으로 보여주는 트리
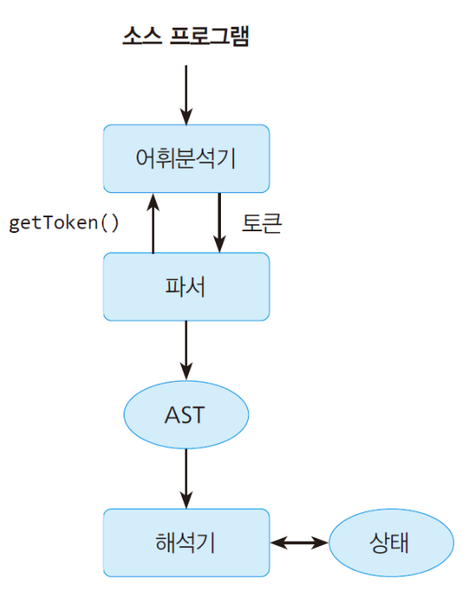 - 인터프리터는 각 문장의 AST를 순회하면서 문장의 의미에 따라 해석하여 수행
- 인터프리터는 각 문장의 AST를 순회하면서 문장의 의미에 따라 해석하여 수행
둘을 분리하면 좋은 점
- simplicity
- efficiency
- portability
Categories of parsers
- top-down: root부터 leaf node까지 parse tree 생성
- 대표적인 top-down parser: RD parser, LL parser
- left most derivation
- bottom-up: leaf부터 root까지
- LR parser
- reverse of rightmost derivation
Top-down parser
-
BNF, EBNF → 사용되는 non-terminal 갯수는 EBNF가 더 작음
-
RHS : right hand side
-
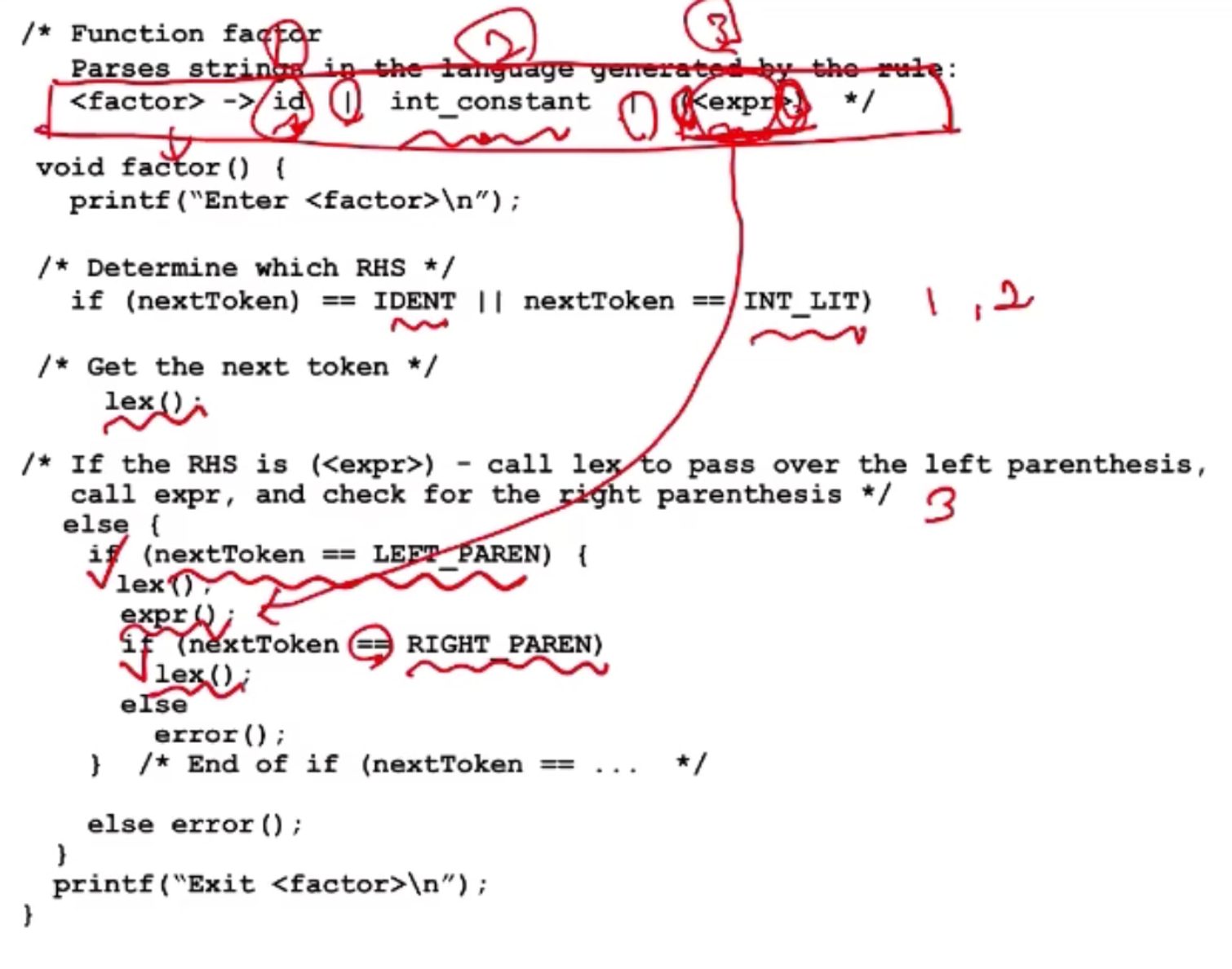
RD parser를 구현할때는 이라는 non-terminal을 처리해주는 Expression procedure을 만들고 non terminal에 대응되는 함수 호출

- term() 함수는 이라는 Non-terminal의 오른쪽 right-hand side를 처리하도록 구현하면 됨

-
1, 2, 3에 대해 처리
- 1, 2번은 terminal symbol lex()로 처리, 3번은 왼쪽 괄호에 해당하는 토큰 처리 후 에 대응되는 함수 호출 후 오른쪽 괄호 토큰 처리
-
어떤 non-terminal이 BNF에 정의되어있는데 right hand side에 하나의 항만 있다면 구현이 간단하지만, 만약 두개 이상의 Right hand side가 존재한다면 (위의 처럼 or 표시로 이루어져 있다면..) input을 살펴보고 (들어오는 token input을 살펴보고) 오른쪽에 or로 선택할 수 있는 right hand side 들을 처리할 수 있어야함
⇒ Match되는게 있으면 처리하고 (match되는 right hand side 없으면 = token이 잘못 들어온 것이라면) syntax error에 대한 처리
expr - term - factor 으로 정의됨
term은 factor/factor 로 정의
factor는 (expr)로 정의
expr은 term + term으로 정의
term은 factor로, factor는 리터럴으로 정의
-
일반적인 LL parser
- left to right로 source code 읽으면서 leftmost derivation하는 과정을 통해 parse tree를 top에서 down까지 생성
- 일반적 top down parser는 코드로 procedure를 논터미널 하나마다 만들어서 매칭해나감으로써 parse tree를 만들어나가는 RD parser (shift and reduce)가 있고, 일반적인 LL parser가 있음.
- 일반적인 LL parser는 parsing table과, input buffer와, stack을 가지고 구현 ⇒ Parsing table 만드는 것이 중요
- parsing table은 software tool이 만들어줌. 정의된 문법을 입력으로 주면 parsing table로 만들어줌
- match-and-extend 방식의 parsing table을 기반으로 하는 것이 LL parser
- RD parser와 LL parser 유사
-
LL parser가 가지고 있는 2가지 단점 (=RD parser, LL이나 RD나 같다고 보겠다고 하심) → LL parser가 가지고있는 BNF를 가지고 parse tree를 만들 수 없는 = syntax 분석을 할 수 없는 경우
-
BNF상에서 left recursion 발생 → LL parser는 무한 루프에 빠짐
- A → Aa | B
- direct든, indirect든 (하나 걸쳐서 나오든…)
- A → B | C
- B → A (indirect recursion)
- LL parser로는 구현이 안됨. (=RD parser로도 안됨)
⇒ BNF or EBNF 자체를 바꿔야 함, 혹은 LR parser로 구현하면 됨

ㄴ A를 없애서 rule을 다시 만들어냄으로써 극복 가능
-
pairwise disjointness test를 통과해야 함
- 앞에 있는 token 읽었는데 선택할 수 있는 것이 하나 이상일때 → 뭘 선택해야할지 결정할 수 없기 때문에 LL, RD parser로 표현 불가
- A라고 하는 non terminal이 알파i가 될수도, 알파j가 될 수도 있지만 그 2개이상의 가장 앞에 오는 terminal이 같으면 안됨

- indirect 까지 생각하면 A → a_, b__, c____ 가능하지만 맨 왼쪽의 terminal은 다르기때문에 LL parser로 구현 가능 : test 성공!
- A → aB | BAb , B → aB | b 같은 경우에는 B가 aB로 가면 같아짐.. B때문에 aB로 따라들어가니까 derivation과정이 다른데도 맨 왼쪽의 terminal 같은 경우 생김 : 실패!
- 동일한 identifier 생기는 경우 → 재정의해서 variable을 identifier에 nonterminal 를 추가, 가 입실론 또는 expression인 것으로 정의하면 이 bnf에서는 left factor 동일한 경우 안생김 : pairwise disjointness test 통과, LL parser를 통해 구현 가능

- 동일한 identifier 생기는 경우 → 재정의해서 variable을 identifier에 nonterminal 를 추가, 가 입실론 또는 expression인 것으로 정의하면 이 bnf에서는 left factor 동일한 경우 안생김 : pairwise disjointness test 통과, LL parser를 통해 구현 가능
-
-
여기까지가 top-down parser에 대한 설명이었음
Bottom-up parser
- LR parser의 동작
-
input이 들어왔을때 bottom up parser로 어떻게 parse tree를 만들 것인가?
-
software tool에 BNF 입력하면 이런 LL parser or LR parser의 parsing table을 제공해줌 → parsing table은 제공된다.
-
초기상태는 0으로 시작
(S0, a1...an$)
-
stack은 이렇게 주어짐 → 대문자 S는 상태 (State), 뒤는 입력 스트링, 입력 스트링의 끝은 $ 기호로 표시
-
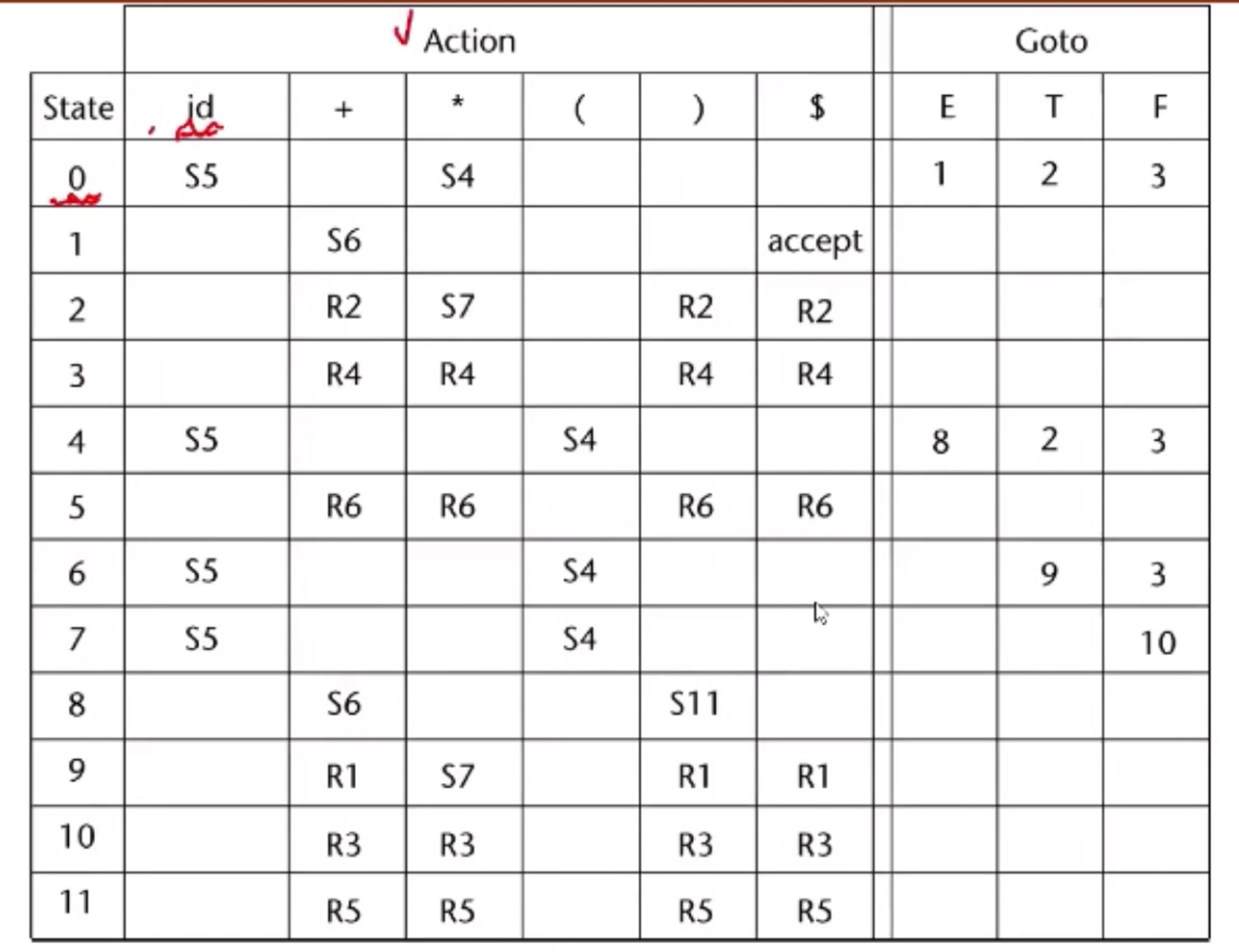
Stack은 상태0token상태1token…으로구성됨
0E1+6T9*7F10숫자하나 = 상태 번호, 토큰 순으로 엇갈려가면서 쌓인다.
0은 초기 start 상태 번호임
입력에 따라 parsing table을 보고 동작 결정
-
동작 기술: action table → S로 시작하거나 (shift) R로 시작하거나 (reduce) accept거나 공란 (4가지 경우)
-
shift: 상태를 뒤에있는 상태번호로 이동하라는 의미 (뒤에있는 숫자 상태로 stack의 상태를 바꿔라)
-
reduce: BNF rule번호에 의해 해당 BNF rule번호로 reduce하라는 뜻
-
accept: 끝났다는 의미. syntax 성공 (parse tree를 bottom up으로 LR parsing으로 생성하는데 성공)
-
공란: error가 발생, syntax error 출력
-
-
reduce는 해당 BNF의 Rule을 따른다

- leftmost derivation (top-down parser만들때) : 왼쪽을 오른쪽으로 바꾼다. 왼쪽 nonterminal을 오른쪽 production rule에 해당하는 걸로 바꿈 → match and expand (오른쪽으로 가는 것은 expand) ↔ reduce
- 6번 production rule로 reduce: 오른쪽 side를 왼쪽으로 reduce하라는 뜻.
- reduce 후에는 꼭 GOTO 해야 함 (LR parser의 규칙)
-
-
-
Bottom-up parser
-
right most derivation을 한다고 가정했을 때, right most derivation의 역순으로 오면서 sentential form을 이동해감
-
→ parse tree를 아래에서부터 위로 오면서 변경한다.
-
handle: 역순으로 올 수 있는 terminal과 non-terminal의 조합 , simple phrase에 해당 -
phrase: 1번 이상의 derivation을 거쳐 A만 β로 바뀌었다면 β는 phrase -
**simple phrase**: 1번만 derivation을 거쳤는데 A만 β로 바뀌었다면 β는 simple phrase (한번만 역으로 가면 A로 바뀐다.)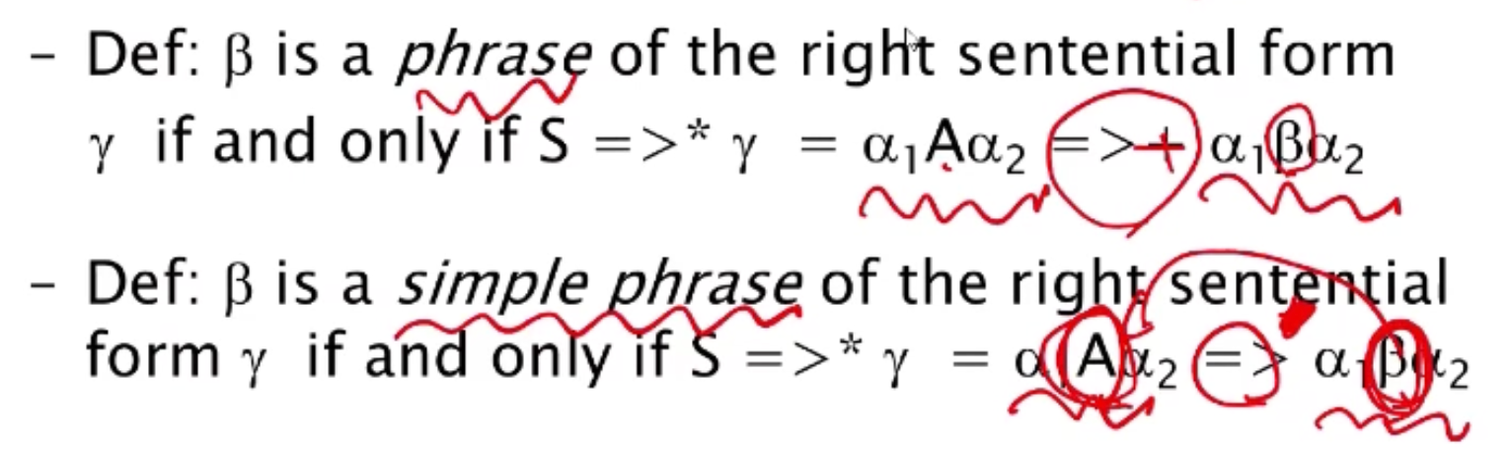
-
right most의 역순으로 오려면 가장 왼쪽에 있는 simple phrase(가장 왼쪽의 handle)을 계속 production rule의 역으로 대치해나가면 된다.
⇒ 근데 실질적으로 bottom-up parser가 동작할때는 parse tree가 없다. 실제 parsing 동작은
parsing table에 의해 일어난다. -
Shift-Reduce Algorithm
- shift: stack의 상태 바꾸면서 input에서 하나의 terminal 꺼냄
- reduce: production rule의 역순으로 동작, goto를 통해 상태를 새로운 것으로 바꿈
-
LR parser(bottom-up)의 advantage
-
left recursion이 나오는 경우도 해결 가능
-
pairwise disjointness test를 실패하는 문법에 대해서도 동작 가능
→ LR parser가 더 다양한 프로그래밍 랭귀지 문법 수용 가능, syntax error도 더 빠르게 검출 가능
-
parser의 동작원리: stack, input buffer 필요
-
-
