언어 판단 척도
- Readability → 언어를 모르는 사람이 쉽게 읽을 수 있는가. python
- overall simplicity
- orthogonality (연결되는 특성이 같은가): 서로 다른 것들끼리의 상관성이 존재하지 않으며 같은 것들 끼리의 예외성이 없는 것
- data type이 너무 많지 않을 것 (data type많으면 writability 좋아짐)
- syntax consideration: 이름을 봤을때 유추하기 쉬운가
- Writability → 언어를 아는 사람이 쓰기 쉬운가. c++, java는 많은 기능이 지원됨
- simplicity and orthogonality (readability, writability와 정비례): 적은 숫자의 구성요소와 이들을 묶는 단순한 규칙.
- support of abstraction (readability는 떨어짐)
- expressivity: 얼마나 많은 표현을 할 수 있나
- Reliability → 안정성. java
- type checking: 타입 에러를 체크하는 것(컴파일 타임에 체크하는 것이 이상적), writability는 떨어짐
- exception handling: readability는 떨어짐 → runtime에러를 잡아서 정정해주는 것
- aliasing: 같은 메모리를 여러개가 가리키는 것(포인터) → writability 높아짐
- readability and writability: 안정성을 너무 높이다보면 이 둘이 저해될 수 있음
- Cost
- 프로그래머가 언어를 배우는데 걸리는 시간
- 프로그램을 작성하는데 드는 비용
- 프로그램을 컴파일 하는데 걸리는 비용
- 언어를 실행 시스템(implementation system)의 비용 ex) compiler, interpreter, JVM
- 안정성 ex)안정성이 낮으면 높은 비용이 들게 됨
- 유지보수에 드는 비용
- Others
- portability → 이식성, 다른 환경에서 잘 동작하는가
- generality → 일반성, 언어의 표현이 일반적으로 많이 쓰이는 표현과 일치하는지
- well-definedness → 잘 정의가 되어 있는지 - 언어의 공식적인 정의가 완전하고 정확한
- 데이터/프로그램은 메모리에
- instructions과 데이터는 메모리에서 CPU로 pipe됨
- assignment statement가 파이프됨
Von Neuman 모델
- 메모리에 프로그램 (명령어/데이터 저장)
- 메모리에 저장된 명령어 순차적 실행
- 명령어: 메모리에 저장된 값을 조작, 연산
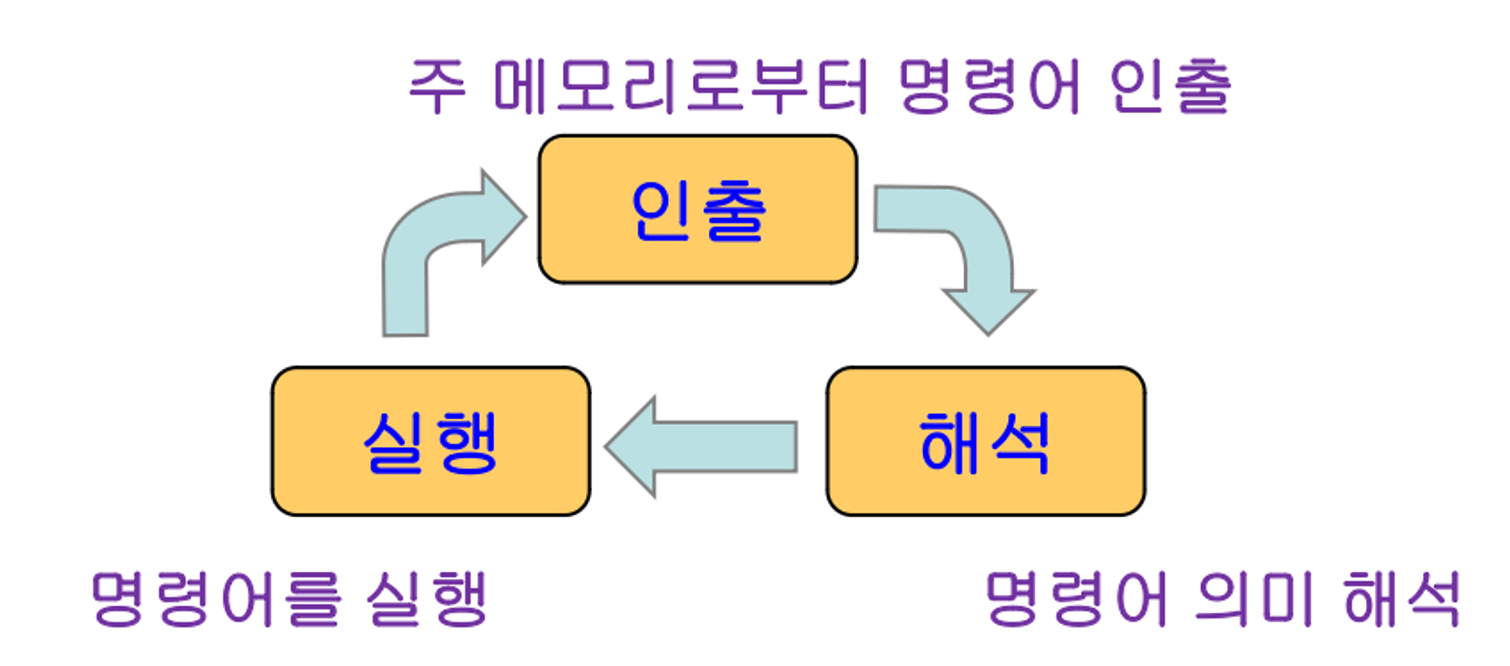
⇒ CPU는 메모리에 저장된 프로그램의 명령어를 하나씩 가져와서 해석하고 실행
Language Categories
- Imperative: 명령형 언어, 폰노이만 아키텍처에서 기계어로 번역되어 하드웨어에서 실행되는 언어
- 사람이랑 비슷(하나씩 하나씩 가져와서 실행), 하드웨어가 이렇게 생김 → main이 됨
- 주기능: 변수, 할당, 반복문
- 객체지향 프로그래밍을 지원하는 언어들을 포함
- 스크립팅 언어, 비주얼 언어 포함
- c, c++, java, python 모두 포함
- Functional
- 매개변수로 입력받아 처리한 후, 반환값을 출력하는 함수로 구성
- 변수 및 대입문이 없다
- recursion에 의한 반복, 루프같은 반복문 x
- 매개변수로 입력받아 처리한 후, 반환값을 출력하는 함수로 구성
- Logic
- 로직으로 이뤄진 언어, p→q형식 기반으로 선언적으로 프로그래밍
- 루프, 선택문 x
- 로직으로 이뤄진 언어, p→q형식 기반으로 선언적으로 프로그래밍
Language Design Trade-offs
- Reliability vs cost of execution → reliability 올리다보면 실행 시간 길어짐
- Readability vs Writability → 많은 연산자가 있으면 읽기가 힘들다
- Writability(flexibility) vs reliability → c에서 포인터때문에 reliability 떨어짐
Implementation method(구현 방법)
⇒ 같은 일인데 동적/정적의 차이
- Compilation → c, c++
- compile: static하게 내가 원할때, binary file(실행파일)이 나옴→기계가 실행할 수 있는 코드가 됨. 빠름
- Pure interpretation → python
- binary file을 미리 만드는 게 아니라 런타임에 한줄한줄 바꿔서 만드는 것. 느림
- Hybrid implementation → java
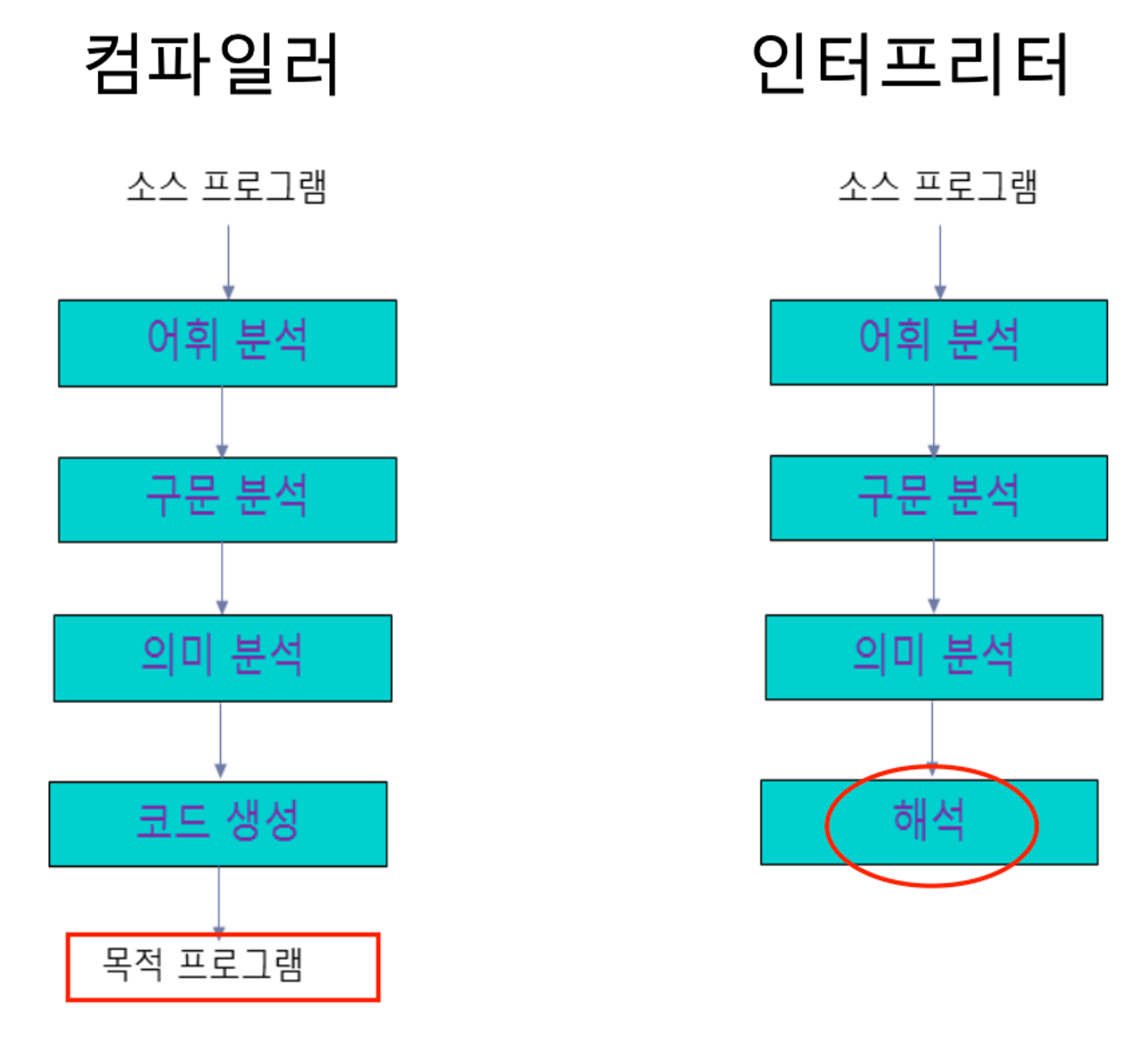
Compilitaion
- lexical analysis → 어휘 뽑아냄, 의미가 있는 것을 뽑아옴, 최소단위 lexeme을 token으로 나눔
- syntax analysis
- semantics analysis
- code generation
- load module (=실행가능한 binary file), linking(내가 짠 코드와 시스템 코드를 묶음)
ab=ce+fg; // ab, =, ce, +, fg, ;
k=ef+abc; // k, =, ef, +, abc, ;- lexical analysis: lexeme 12개, id, eq operator, operator, seperator의 token으로 구분 (token은 4개) → 나누기만 할 뿐 에러 안남.
- syntax analysis: (parsing과 유사=lexical analysis+syntax analysis) 문장마다 parse tree를 생성, 여기서 잘못된 문장 Error발생
- semantics analysis: 의미 분석, 최적화 거침
- code generation: 기계어 코드로 변환, machine코드 생성됨
⇒ 미리 이 과정을 해두는 것이 컴파일
Pure interpretation
- no translation
- 소스코드가 바로 실행되기에 실행이 쉽고, 런타임에러는 바로 볼 수 있다
- 실행이 느림
- 공간이 더 필요함
Preprocessor (컴파일에서 제외)
→ lexical 분석 전 이 작업을 끝내고 들어감
c에서는 매크로(#include, #define같은)
Hybrid implementation
- 자바에서 사용
- translation을 통해 도중에 고급언어를 중급언어로 코드 생성 하여 interpretation이 쉽도록 해서 interpretation도 수행한다.
- pure interpretation보다는 빠름
프로그래밍 언어 정의
→ syntax와 semantics를 정하는 과정
- 어휘구조 (lexical structure)
- 구문법 (syntax): 동작, 의미와 상관없이 허용되는 문장인지 아닌지만 판단
- 의미론 (semantics): 문법과는 상관 없음, 의미에 맞는지/안맞는지
프로그래밍 언어 구현
💡 입력프로그램 → Syntax → Semantics → Interpret/Compile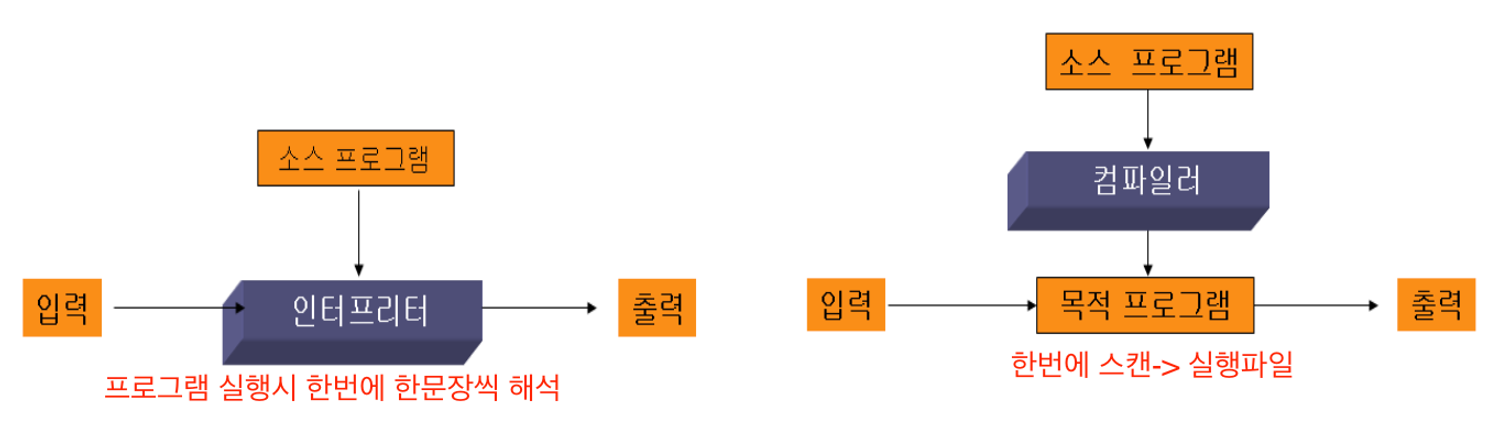
컴파일러 vs 인터프리터