
코드스쿼드 코코아과정 2주차 TIL - Part1
Mission 3. 해시맵 구현
Mission 상세내용보기
Brainstorming
Map APIs
-
JavaScript map APIs에는 set, has, get, delete, clear, size(property)...이 있다.
-
set() : Map 객체에서 주어진 키를 가진 요소를 추가하고, 키의 요소가 이미 있다면 대체
myMap.set(key, value);
key: Map에 추가하거나 변경할 요소의 키
value: Map에 추가하거나 변경할 요소의 값 -
has() : 주어진 키를 가진 요소가 Map에 존재하는지를 반환
myMap.has(key);
key: 존재 여부를 판별할 키값 -
get() : Map 객체에서 지정한 요소를 회수
myMap.get(key);
key: Map 객체에서 회수할 요소의 키 -
delete() : Map 객체에서 특정 요소를 제거
myMap.delete(key);
key: Map 객체에서 제거할 요소의 키 -
clear() : Map 객체의 모든 요소를 제거합니다.
myMap.clear(); -
size : Map 객체의 요소 갯수를 반환
myMap.size;❗️주의: 괄호없음
hash map 의 조건
- 동일한 키는 동일한 값을 생성해야 한다. ➡️ 중복데이터 방지
- 시간복잡도가 O(1)이다. ➡️ 배열 "읽기"로 데이터 가져오기
- 이진 검색(binary search) 사용 ➡️ "정렬된 배열"로 만들기
hash algorithm & collision
hash 알고리즘은 입력받은 key로 얼마나 잘 골고루 분배해서 저장하느냐의 문제.
Collision: hash algorithm의 한계점
- 'Collision(충돌)'은 하나의 배열방에 겹쳐서저장되어야 하는 경우를 뜻함.
- hash algorithm은 동일한 key값으로 서로 다른 hashcode를 만들어내기도 함.
왜? key값은 '문자열'이고 그 가짓수가 무한하지만, hashcode는 '정수'개만큼 밖에 제공을 못하기 때문. - 서로 다른 hashcode를 만들어내도 배열방이 한정되어 있어서 같은 인덱스를 갖게 될 수도 있음.
훌륭한 충돌 조정을 갖춘 hash table : 부하율 0.7
- hash 테이블은 중복값이 저장되지 않는다. 대신 겹쳐지기 때문에 새로운 값으로 대체.
- 이에 따른 장점: 읽기와 삽입 모두 O(1)로 가능.(⬅️➡️ 중첩 루프는 O(N^2)에 실행)
- hash 테이블의 "효율성"은
1) 얼마나 많은 데이터를 저장하는지,
2) 얼마나 많은 셀을 쓸 수 있는지,
3) 어떤 hash 함수를 사용하는지에 따라 정해짐. - 따라서, 많은 메모리를 낭비하지 않으면서 균형을 유지하며 충돌을 피하는 hash 테이블을 만들어야 함.
- 충돌 조절에 가장 이상적인 규칙은 데이터와 셀 간의 비율, 즉 부하율 0.7(원소 7개 / 셀 10개)
- 해시 테이블에 저장된 데이터가 7개면은 셀은 10개여야 하는 식.
- 코드의 성능을 최적화하고 효율성 O(1)의 룩업을 사용.
hash code 만들기
문자열의 각 글자에 해당하는 ASCII코드를 모두 합한 값.
ex. "sung"의 hash code 구하기
➡️ s(115) + u(117) + n(110) + g(103) = 445
➡️ "sung"의 hash code 는 445
hash code 를 index 로 환산하기
먼저 고정된 크기의 배열을 '미리 선언'한다.
hashcode를 배열의 size(length)로 나누고 나온 나머지값을 인덱스로 사용.
Index = hashcode % size
ex. 배열의 size가 3일때 445의 인덱스 구하기
➡️ 445("sung"의 hashcode) % 3 = 1
➡️ hash code 445 에 해당하는 데이터가 저장되는 위치는 1번 인덱스
위에서 설명한 것처럼 똑같은 hash code를 가진 key를이 여럿이라면 Collision이 일어나게 된다.
이런 경우를 대비해 환산한 인덱스의 위치에 바로 저장하지 않고, 해당 인덱스에 또 다른 이중배열[[{key:val}, {key:val}, {key:val},,,]]을 만들어 데이터를 추가한다.
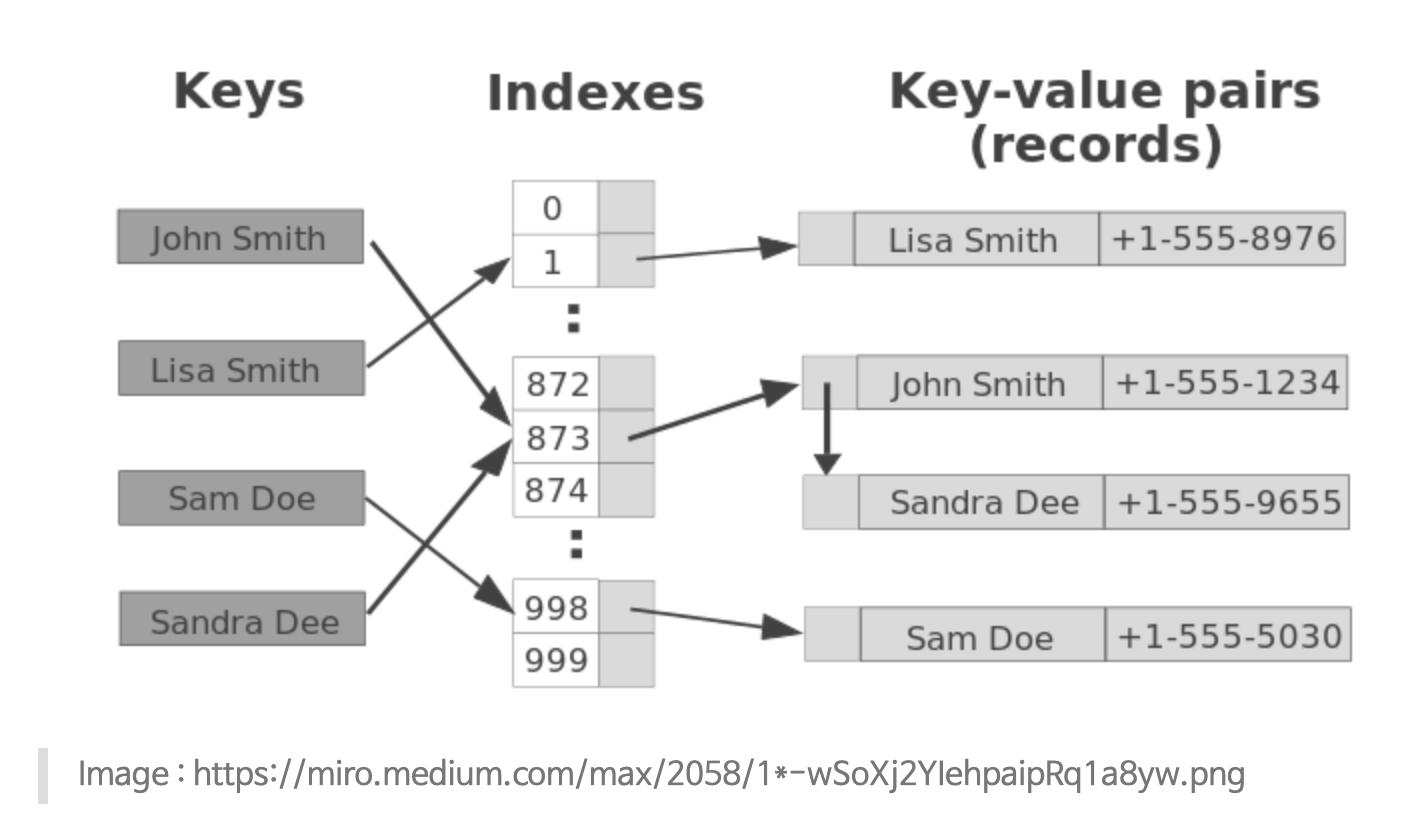
Search Process
"key" 검색 요청 ➡️ "key" 를 hash code 로 변환 ➡️ hash code 를 index 로 환산 ➡️ 해당 방의 list(내부 배열)을 돌면서 검색
My Code Review
Array.from()
Array.from() 메서드는 유사 배열 객체(array-like object)나 반복 가능한 객체(iterable object)를 얕게 복사해 새로운 Array 객체를 만듭니다.
[syntax]
Array.from(arrayLike[, mapFn[, thisArg]])arrayLike: 배열로 변환하고자 하는유사 배열 객체나 반복 가능한 객체
mapFn: 배열의 모든 요소에 대해 호출할 맵핑 함수
thisArg: mapFn 실행 시에 this로 사용할 값-MDN
이중배열로 이루어진 저장소를 만들기위해 처음 시도했었던 코드는 아래와 같다:
[변경 전]
let storageArr = [];
storageArr.length = 10;
storageArr.forEach( emptyEl => emptyEl = []); 📌📌📌
빈 배열에 길이만 10으로 지정해줄 경우, 위 브라우저 화면처럼 empty(빈)요소가 10개가 생긴다.
그래서 생각해낸 빈칸을 빈 배열로 치환해주기 위한 시도였지만 전혀 바뀌지를 않았다.

그래서 꿩 대신 닭이라는 생각으로 for문 사용해 대체했는데,
이후 코드리뷰를 받으면서 Array.from()메서드를 사용해보라는 조언을 얻었다.
[변경 후]
let storageArr = [];
storageArr.length = 10;
storageArr = Array.from(storageArr, el => []); 📌📌📌
그래서 Array.from(storageArr, el => []);로 정정해 다시 실행해보았더니
웬걸,,, 잘된다!!🤭😃👏

빈 요소로만 이루어진 배열은 일반 배열의 메서드를 사용할 수 없었던 것이다.
이 메서드는 완전한 배열이 아니더라도(정확히는 '유사배열객체'나 'iterable객체' 까지도) 배열의 메서드를 사용하고 싶을 때 쓸 수 있는 메서드이기 때문에 의도했던 것처럼 loop를 돌며 요소를 가져오게 된다.
Array.fill()
놀라운 건 앞서 적은 Array.from뿐만 아니라 Array.fill()메서드로도 이중배열을 만들 수가 있다!
Array.fill() 메서드는 배열의 시작 인덱스부터 끝 인덱스의 이전까지 정적인 값 하나로 채웁니다.
[syntax]
arr.fill(value[, start[, end]])
new Array(배열의 길이).fill(채울 요소)➡️ 새 배열 반환value: 배열을 채울 값
start: 시작 인덱스, 기본 값은 0
end: 끝 인덱스, 기본 값은this.length-MDN

new 키워드를 함께 사용하면서 배열 인스턴스를 생성하기 때문에 위 화면처럼 이중배열을 반환받을 수가 있다.
사실은 storageArr.length = 10;처럼 길이를 지정해서 빈 셀을 만들기보다는 new Array(10);쪽이 현업에서는 훨씬 많이 쓰인다고 한다.
+알아두기: new Array(10).fill(0).map((e, idx) => idx) 이렇게도 활용할 수 있음.
Peer Session
array.flat()
flat() 메서드는 모든 하위 배열 요소를 지정한 깊이까지 재귀적으로 이어붙인 새로운 배열을 생성합니다.
const arr4 = [1, 2, [3, 4, [5, 6, [7, 8, <[9, 10]]]]]; const arr = arr4.flat(Infinity); console.log(arr); // output: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]-MDN
중첩된 배열을 하나의 배열로 만들기에 유용하다.
array.some()
some() 메서드는 배열 안의 어떤 요소라도 주어진 판별 함수를 통과하는지 테스트합니다.
const array = [1, 2, 3, 4, 5]; const even = (element) => element % 2 === 0; console.log(array.some(even)); // output: true-MDN
array.sort()
sort() 메서드는 배열의 요소를 적절한 위치에 정렬한 후 그 배열을 반환합니다. 정렬은 stable sort가 아닐 수 있습니다. 기본 정렬 순서는 문자열의 유니코드 코드 포인트를 따릅니다.
const months = ['March', 'Jan', 'Feb', 'Dec']; months.sort(); console.log(months); // output: Array ["Dec", "Feb", "Jan", "March"] const array1 = [1, 30, 4, 21, 100000]; array1.sort(); console.log(array1); // output: Array [1, 100000, 21, 30, 4]-MDN
Impression
수업을 듣다보니 각 메서드를Class나 Prototype을 사용해서 상속하는 식으로 로직을 구현해야 한다는 것을 뒤늦게 알게 되었다.
이 부분을 늦게 알게 된 바람에 각 함수를 전부 전역스코프에서 정의해 주었는데, 현재상태에서 주요 부분들을 바꾸지 않는 선에서 prototype 내부의 메서드로 연결지을 수 있게 수정해 보아야겠다.
내부에서 메서드들끼리 재사용하는 로직은 this를 알맞게 사용할 필요가 있을 것 같다. 🤔
In addition to that...
-
"복잡도": 작업수행에 필요한 단계 혹은 자원이라고 볼 수 있다.
서버는 항상 request 받는 입장이라 복잡도가 중요.
O(1)은 "상수"복잡도.
탐색(iteration)을 할 필요가 없다. (그러나 이름이 똑같을 경우 탐색을 해야하기 때문에 O(N)이 될 수 있음) -
"무결성": 데이터가 누구에 의해서도 훼손되지 않음을 증명 (ex. 전자서명)
-
"브라우저 로컬 스토리지": 처리된 결과를 다시 재수행하지 않기 위해 로컬 스토리지에 저장하는 경우. 주머니의 개념.
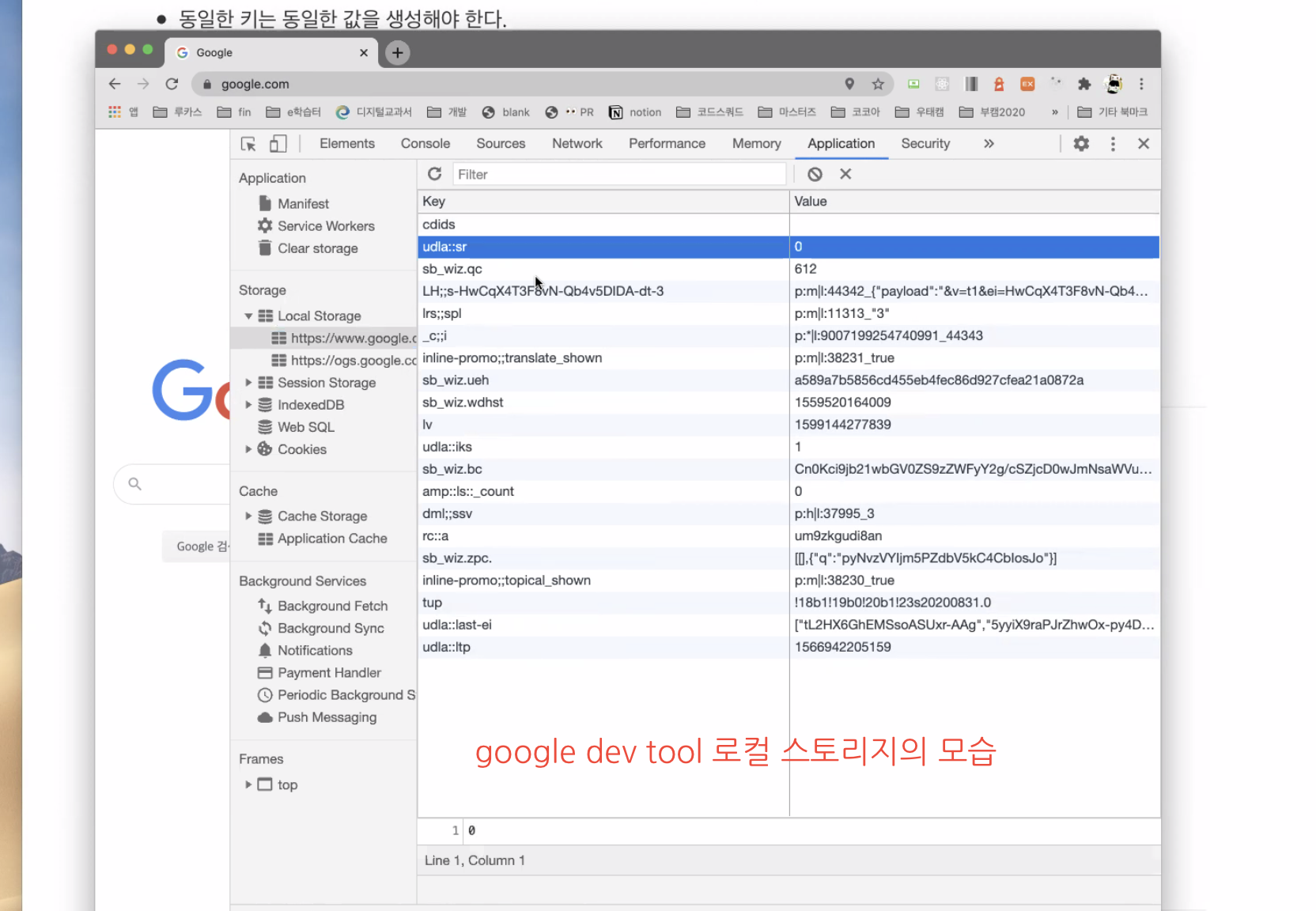
키와 밸류로 저장한다. 이 때도 해쉬를 사용해LocalStorage.get(“myKey”);식으로 불러올 수 있음. -
반복문 안에 반복문(이중 반복문)을 넣는 것은 시간복잡도가 n제곱이 된다.
-
충돌방지를 위한 Chaining에는 'Linked List'라는 것도 있다.
Linked List는 배열에 비해 추가 / 삭제가 용이한 점이있지만 특정 데이터를 찾기 위해서는 순차 탐색을 하므로 탐색 속도가 느린 단점이 있다. 그러나 '동적 할당'을 기반으로 한 리스트이기 때문에 크기를 미리 지정할 필요가 없다는 장점이 있다. -
알고리즘과 자료구조는 개발자에게 기초체력이라고 할 수 있다. 쉬운 책을 먼저 보고 쉬운 문제를 많이 풀어볼 것. 꾸준히 1년 정도 하면 개발자의 큰 밑거름이 된다.
-
JavaScript의 Object는 배열처럼 처리된다. Map vs. Object 퍼포먼스 차이 알아볼 것.
Map은 중복이 안들어가고, 메소드가 잘 만들어져 있다는 특징이 있음. 하지만 그 외에는 큰 차이가 없다고 볼 수 있다. -
정확한 개념의 명칭(ex. 선형탐색 등등..)을 아는 것보다는 아이디어를 구하는 것이 더 중요!
-
키 값이 중복이 될 때 Linked List로 chaining을 한다?
Linked list 로 next node를 가리키는 것이랑 for문을 돌리는 거랑 복잡도에서 어떤 차이가 있는지?
Linked list는 좀 더 제한된 범위 내에서 찾는다는 정도의 차이. -
해시 알고리즘은 여러가지이다. 결과를 똑같이 가져올 수 있다면 어떤 알고리즘이 더 빠르냐의 문제가 된다.
-
"객체지향 프로그래밍(OOP)":
객체지향 프로그래밍(OOP)은 함수들의 집합 혹은 단순한 컴퓨터의 명령어들의 목록 이라는 기존의 프로그래밍에 대한 전통적인 관점에 반하여, 관계성있는 객체들의 집합이라는 관점으로 접근하는 소프트웨어 디자인으로 볼 수 있다. 객체지향 프로그래밍에서, 각 객체는 메시지를 받을 수도 있고, 데이터를 처리할 수도 있으며, 또다른 객체에게 메시지를 전달할 수도 있다. 각 객체는 별도의 역할이나 책임을 갖는 작은 독립적인 기계로 볼 수 있는 것이다.
객체지향 프로그래밍은 보다 유연하고 유지보수성이 높은 프로그래밍을 하도록 의도되었고, 대규모 소프트웨어 공학에서 널리 알려져 있다. 객체지향 프로그래밍이 갖는 modularity에 기반한 강력한 힘에 의해, 객체지향적인 코드는 개발을 보다 단순하게 했고, 시간이 흐른 뒤에도 보다 쉽게 이해할 수 있도록 했으며, 복잡한 상황이나 절차들을 덜 모듈화된 프로그래밍 방법들보다 더 직접적으로 분석하고, 코딩하고, 이해할 수 있도록 만들었다.
-MDN
-
자바스크립트는 객체지향 프로그램이라고 부르지만 사실 객체 없이도 프로그래밍이 가능하다.
-
객체를 만드는 다양한 방법 중 마침표(
.)를 찍어서 객체 안에 객체를 또 만들어줄 수도 있다. Name Space라고 부른다.
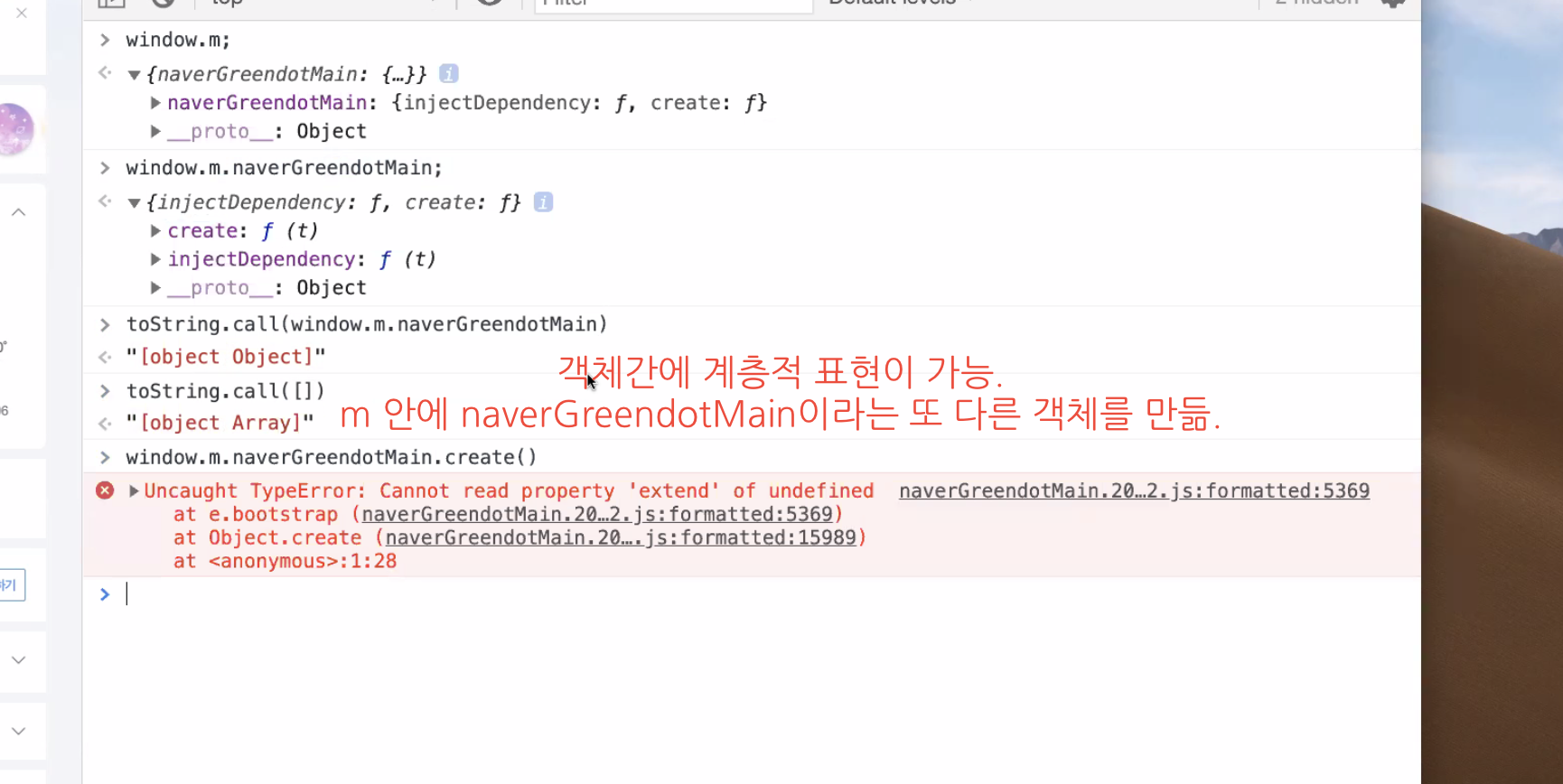
window(전역객체)에m이라는 객체가 존재하고, 그 안에 또naverGreendoMain이라는 객체가 존재한다.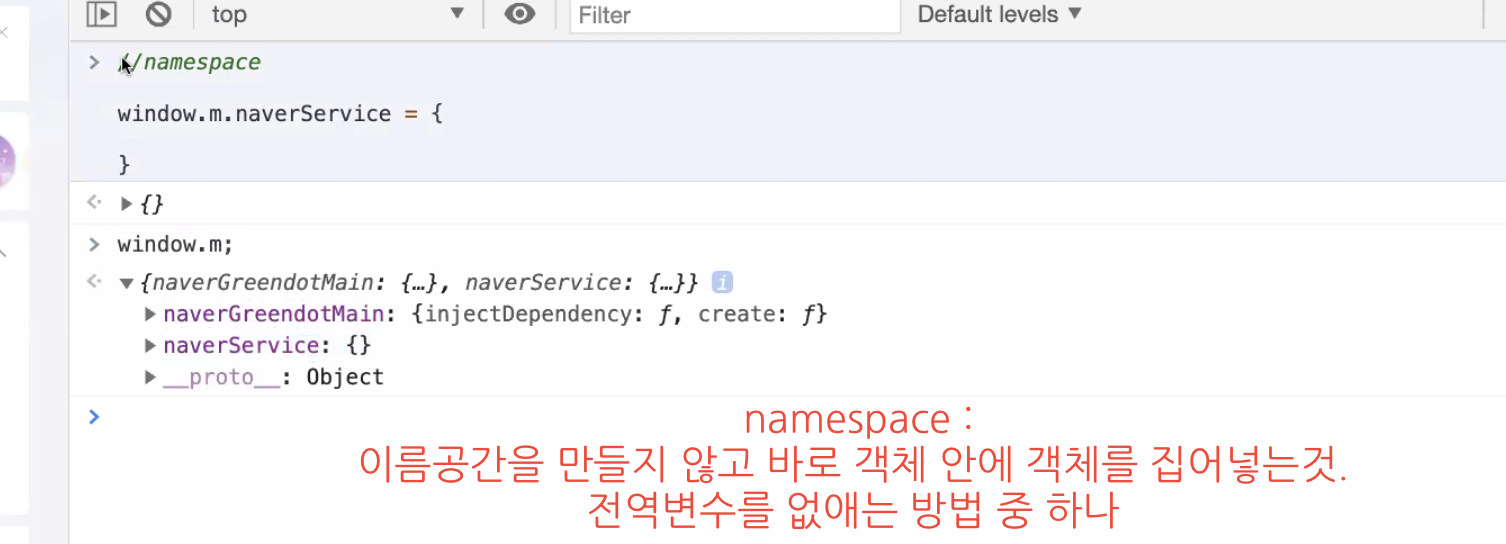
-
UI 객체는 의미보다 비슷한 기능을 하는 것들을 묶음.
-
하나의 클래스에 여러 개의 객체를 만듦.
예를 들어 검색창을 하나 만든다고 하면 '입력창', '최근 검색어' 등등 여러 가지가 들어가게 된다.Search = {
A 객체(최근 검색어),
B 객체(input box 관련),
C 객체(자동완성)
}그렇다면 A, b, c 객체는 서로 관련이 있을까?
모두 '검색'과 관련된 것!그리고 A 객체인 최근 검색어관련 객체 내부에는 또 ‘리스트 객체’가 있음.
리스트 객체 안에는 검색한 날짜, x 표 등등이 있음.
보통 FE에서는 리스트 객체라는 표현보다 ‘컴포넌트’라고 부름.
프로그램은 그만큼 작게 나눌 수 있음!!!
각자 해야할 역할(혹은 책임)이 정해져 있다!! -
객체의 크기가 큰 건 단점.
예를 들어 수정하려고 해도 기획자들이 더 큰 단위의 객체를 같이 수정해야하고 …
소프트웨어는 ‘변화’가 잦기 때문에 변화를 해도 영향이 적은 코드를 써야하는 것.
-
객체 간의 통신에서 ‘강한 결합’의 단점은 서로의 변화에 영향을 크게 받는 것.
얘를 바꾸면 쟤도 바꿔야 하고…..
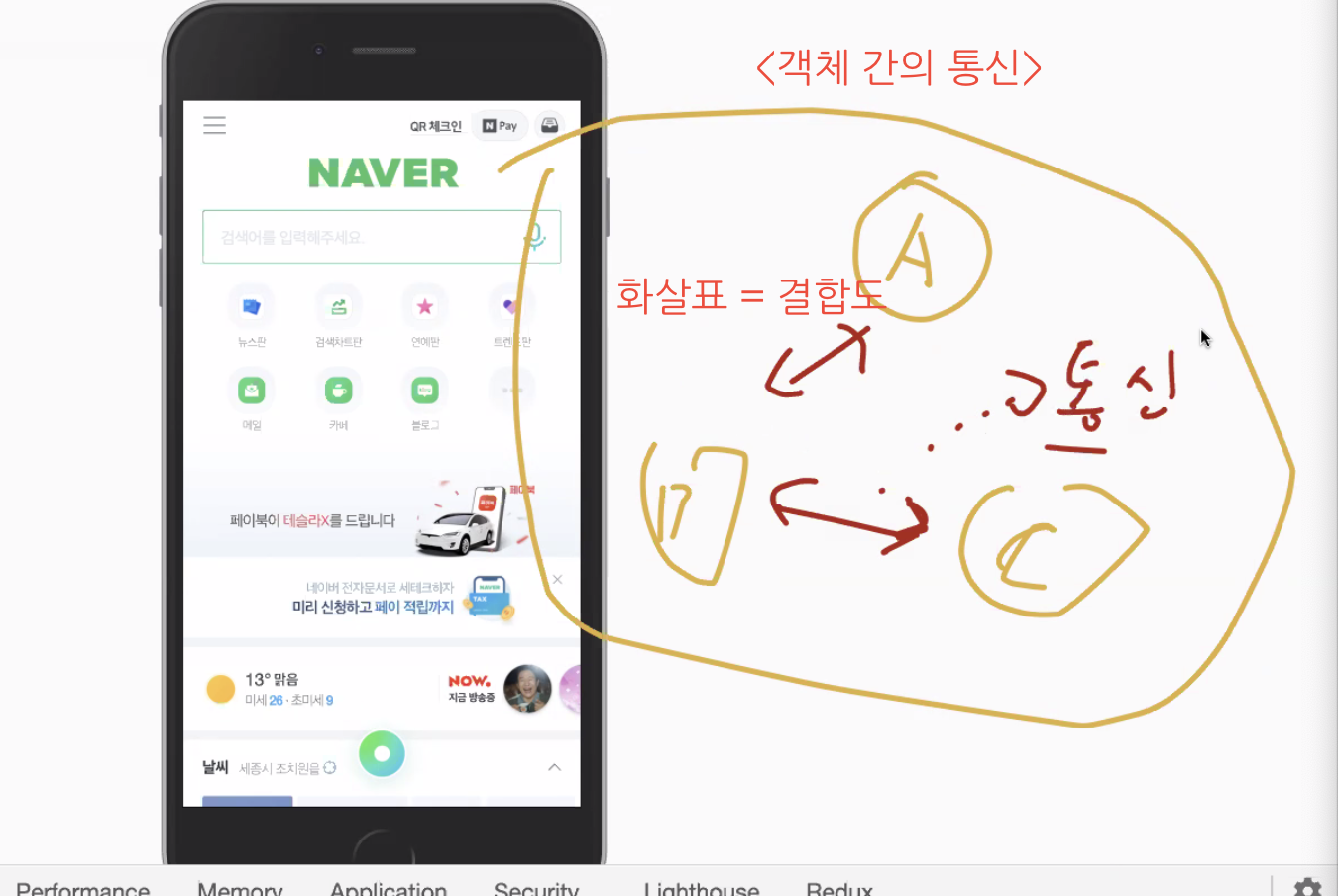
좋은 객체는 서로 간의 결합이 느슨~~ 해야 한다.
“어떻게 결합도를 낮추지? 어떻게 느슨한 관계를 만들지?”를 고민해야함.
설계를 어떻게 해야 결합도가 낮은 프로그래밍을 할 수 있을 지 고민이 될 때
#'디자인 패턴 책'으로 검색되는 책들은 이런 고민이 들 때 볼 수 있음. 그럴 때 크게 도움이 될 것. -
Private 객체 vs. Public 객체
이 둘을 구분해서 코드를 짜는 걸 “캡슐화”라고 함. -
"Common view": 상당히 비슷한 객체들에서 공통적인 부분들을 모은 것. 상속!! 재사용 패턴.
-
생성자 패턴으로 만드는 방법의 단점은 메서드들이 서로 다른 것.
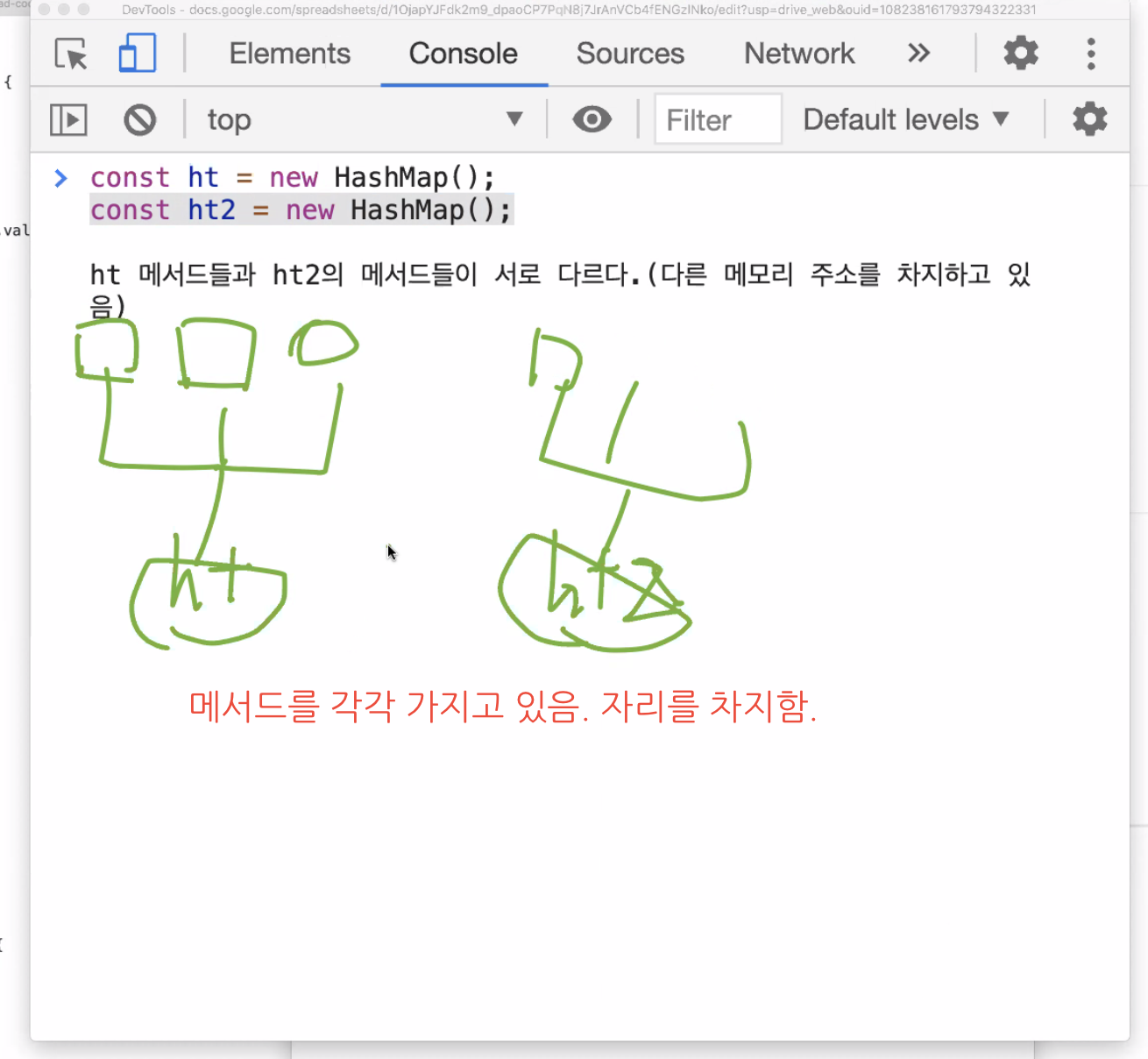
인스턴스가 생성될 때마다 새로운 메모리에 메서드들을 함께 상속받기 때문에 prototype보다 메모리를 더 많이 차지한다.
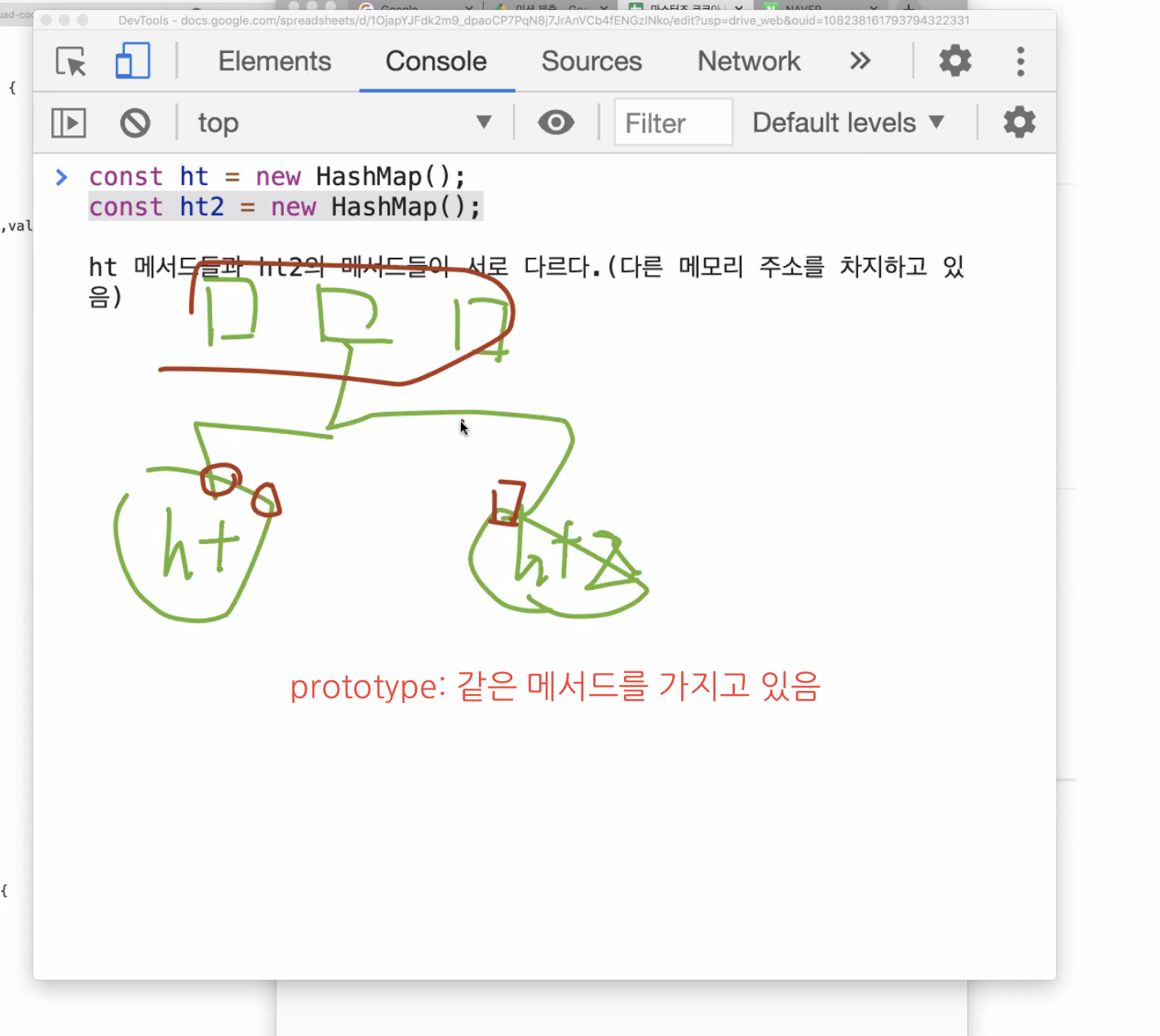
-
Class는 내부적으로 prototype을 쓴다. Class는 사실은 function.
-
Tip:
1) Class를 만들 때, constructor에는 달라지는 속성들을 parameter로 주기
2) 생성자 함수는 대문자로 써주기
To-do List 💪
- Linked List에 대해 알아보기 - #배열과 링크드리스트의 차이 , #바이너리 서치 (binary search) (생활코딩, Linked List vs. Array List, 자료구조 Linked List)
- #git commit log 의 알고리즘 알아보기
- #자료구조의 알고리즘 별 복잡도의 차이 알아보기
- #Map vs. Object 퍼포먼스 테스트 알아보기
- #파이썬, 자바 등 다른 언어로 해시맵 구현하는 방법 알아보기
Reference 📚
*본 포스팅은 아래 사이트들을 참고 및 인용하여 작성되었습니다.
학습단계로 잘못된 정보가 있을 수 있습니다. 잘못된 부분에 대해 알려주시면 곧바로 정정하도록 하겠습니다 😊
https://www.youtube.com/watch?v=Vi0hauJemxA
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/Array/from
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/Array/fill
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/Array/some
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/Array/sort
https://www.holaxprogramming.com/2014/02/12/java-list-interface/
https://opentutorials.org/module/1335/8821
https://boycoding.tistory.com/33
