자연어 처리
- 토큰화, 정제, 정규화, 정수 인코딩의 기본적인 자연어 전처리 과정을 이해한다
- 감성어휘 사전을 활용해 감성분석을 진행해보자
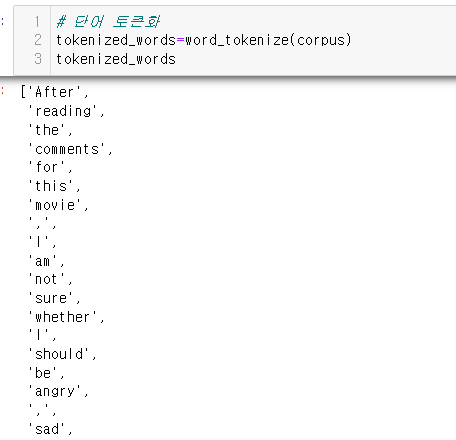
단어 토큰화(Word Tokenization)
- 토큰 : '의미있는 작은 단위'를 뜻함
- 코퍼스(corpus) : 분석에 활용하기 위한 자연어 데이터 / 말뭉치
- 토큰화 : 하나의 코퍼스를 여러개의 토큰으로 나누는 과정
영어 자연어 처리 패키지 설치 : NLTK
단어 토큰화

실습

정제(Cleaning)
- 코퍼스에는 아무 의미도 없거나 목적에 부합하지 않는 단어들도 포함
- 전처리 과정에서 제거하는 작업을 정제
- 등장빈도, 단어길이, 불용어 등을 기준으로 사용
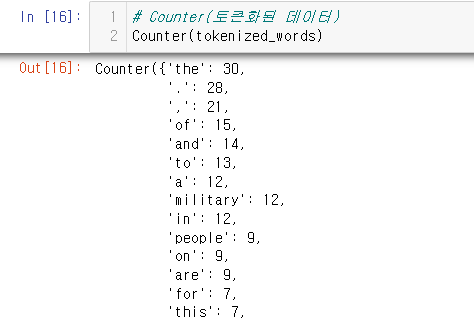
등장빈도가 적은 단어 정제
- 코퍼스에 등장하는 빈도가 너무 적은 단어는 분석에 도움이 되지 않음
- Counter() 함수 활용
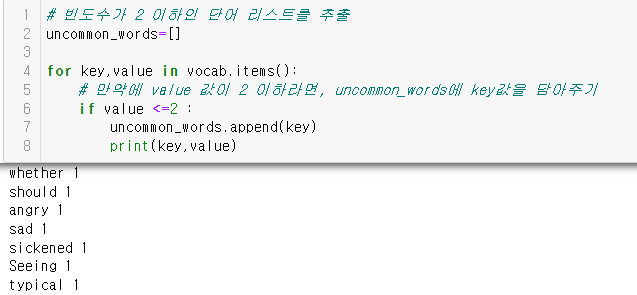
**빈도수가 2 이하인 단어 리스트를 추출
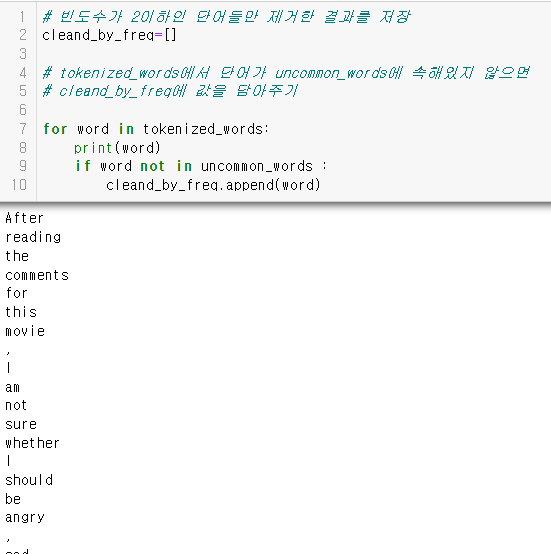
**빈도수가 2이하인 단어들만 제거한 결과를 저장
- if 변수 not in
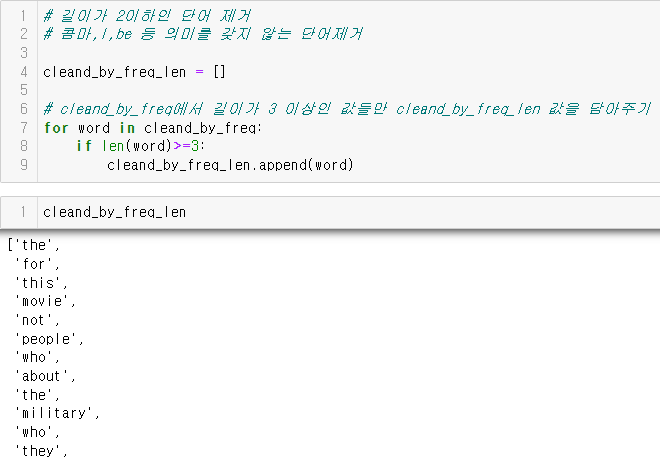
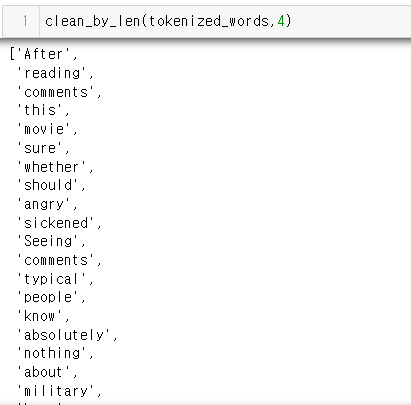
**길이가 2이하인 단어 제거
- len()
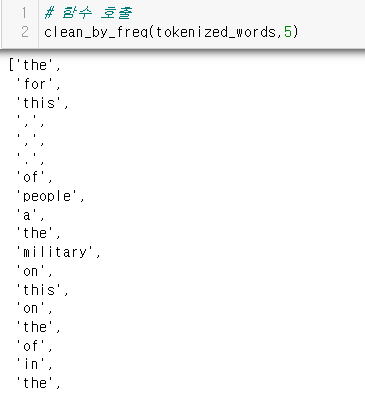
정제 함수 만들기
- 등장 빈도 기준 정제 함수

-
함수호출
-
단어 길이 기준 정제 함수

-
함수호출
불용어(Stopwords)
- 코퍼스에서 큰 의미가 없거나, 분석 목적에서 벗어나는 단어들
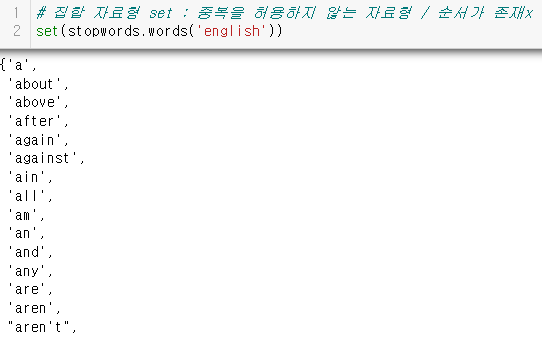
- 불용어를 모아 놓은 불용어 세트 준비
- 코퍼스의 각 단어/토큰들이 불용어 세트에 포함되는지 확인
- 불용어 세트에 있는 단어 토큰을 분석에서 제외
- 불용어를 모아 놓은 불용어 세트 준비

- 불용어를 모아 놓은 불용어 세트 준비
** 집합 자료형 set (인덱싱, 슬라이싱 불가)
- 코퍼스의 각 단어/토큰들이 불용어 세트에 포함되는지 확인
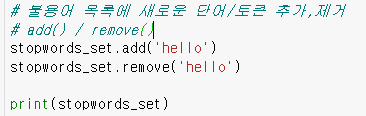
**불용어 목록에 새로운 단어/토큰 추가,제거
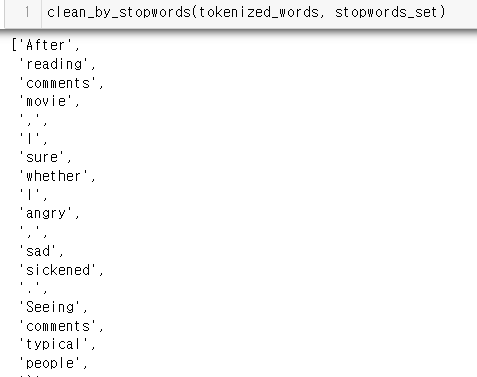
불용어 제거하기

불용어 처리 함수 정의하기

- 함수호출
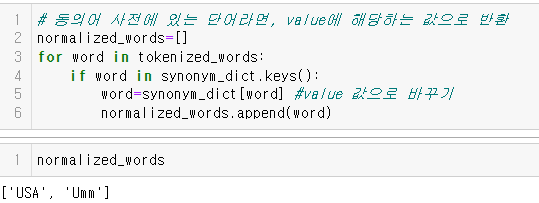
정규화(normalization)
- 의미가 같은 단어라면 하나의 형태로 통일
- 형태가 다르지만 같은 의미를 나타내는 단어들이 많을수록 분석이 어려워짐
- 남한,Korea,대한민국,한국->통일
정규화방법1 : 대소문자 통합

정규화방법2 : 규칙기반 정규화


감성분석이란
- 자연어에 담긴 어조가 긍정적인지, 부정적인지, 혹은 중립적인지를 확인하는 작업
- 제품개발, 서비스개선, 시장조사 등 다양한 용도로 활용가능
VADER
- 감성 분석을 위한 어휘사전이자 알고리즘
- 축약형과 기호 등을 고려해 감성지수를 추출할 수 있음
**VADER 감성분석
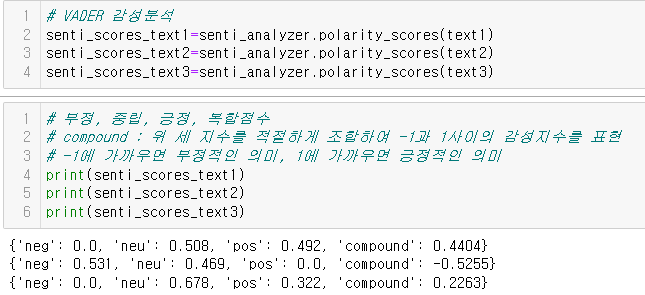

안녕하세요