gromit_dev.log
로그인
gromit_dev.log
로그인
[기술 소개] Vision Transformer(ViT) - Transformer를 이미지에 적용한 연구
gromit
·
2022년 2월 9일
팔로우
0
MLP Head
Patch Embedding
Position Embedding
Transformer Encoder
ViT
transformer
멀티 헤드 어텐션
Natural Language DEEP Learning 🤍
목록 보기
5/13
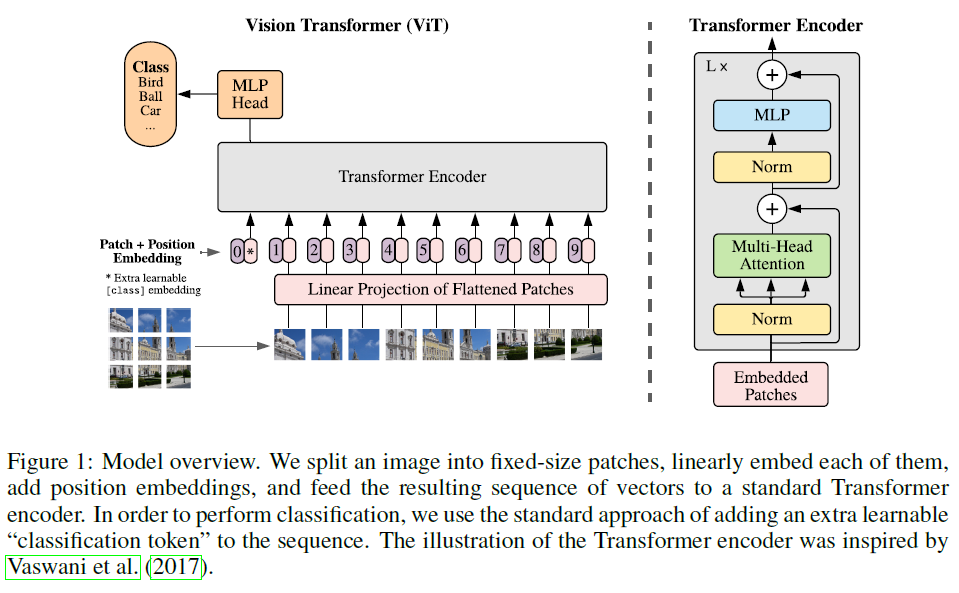
Vision Transformer(ViT) 모델
논문 리뷰 번역글 :
https://velog.io/@changdaeoh/Vision-Transformer-Review
PyTorch 구현 글 :
https://hongl.tistory.com/235
einops
라이브러리 (피어세션 공유)
https://einops.rocks/api/rearrange/
http://einops.rocks/pytorch-examples.html
gromit
AI, Big Data, Industrial Engineering
팔로우
이전 포스트
[NLP 트렌드 공부] 신경망 기계번역 (seq2seq, Attention, Teacher Forcing) (작성중)
다음 포스트
[NLI 대회] 사용 모델 & 접근 방향에 대한 고민
0개의 댓글
댓글 작성