[김기현의 자연어 처리 딥러닝 캠프] 7장. 시퀀스 모델링 -RNN, LSTM, GRU (2022/02/02, 2022/03/15)
Natural Language DEEP Learning 🤍
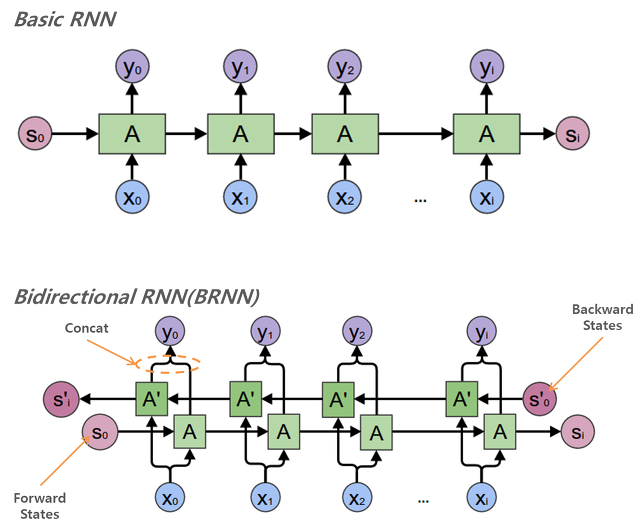
김기현의 자연어 처리 딥러닝 캠프 파이토치 편- [7장. 시퀀스 모델링] 복습 + 추가 조사
자연어 문장의 특징
- 단어들의 순차적 조합
- 문장은 단어의 순서 정보(시간 개념)가 포함된 시퀀셜 데이터
- Ex) 문장 내 단어들은 앞뒤 위치에 따라 서로 영향을 주고 받는다.
Sequential 데이터 특징
- 1️⃣ 가변 길이의 데이터
- 2️⃣ time-step별로 데이터 출현에 영향을 주고 받음
시퀀셜 모델링 (Sequential Modeling)
- 시간 개념/순서 정보를 사용하여 입력을 학습하는 기법
- 기존의 완전연결 신경망(Fully Connected Neural Network, FNN)에서 발전된 트렌드
- 방법론 종류 : 은닉 마르코프 모델, 조건부 랜덤 필드(CRFs) 등 / 신경망 기반(RNN 등)
1. 순환 신경망(Recurrent Neural Network, RNN)
-
1️⃣ 입력(X_t)와 2️⃣ 직전의 은닉 상태(Hidden State, h_t-1)를 참조하여 ➡️ 현재 상태인 H_t를 결정하는 작업을 여러 time-step에 걸쳐 수행하는 구조.
RNN(❓년)
- 1986년 데이비드 루멜하르트의 연구에 기반을 둠 + 유르겐 슈미트후버 등이 스위스 인공지능 연구소 IDSIA, USI, SUPSI 연구그룹에서 자체 개발
- 주요 개념 :전통적인 뉴럴 네트워크는 모든 입력값은 서로 독립적이라는 것을 기본 가정으로 하기 때문입니다. 따라서 영화의 각 장면마다 어떤 유형의 일이 일어날지 분류하는 작업을 전혀 처리할수 없었습니다. 하지만 RNN의 등장으로 이러한 문제가 해결되었는데, RNN은 네트워크 안에 루프(feedbaack loop, recurrent loop)를 만들어 정보가 지속되도록 하였습니다.
RNN은 시퀀스의 모든 요소에 대해 동일한 작업을 수행하고 출력값이 이전 결과에 의존하기 때문에 'recurrent'라고 부릅니다. RNN은 또 "기억(memory)"를 가지고 있다고 하는데요, 이 기억은 "지금까지 어떻게 계산되어왔는지"에 대한 정보를 가지고 있습니다.
-
정리가 잘 된 글 : https://hyen4110.tistory.com/24 [Hyen4110]
-
단계
Feed Forward(순전파)
BPTT(역전파)- BPTT ?
: Back-Propagation Through Time, 시간 축에 대해서 수행되는 역전파 방법이라는 의미.
- BPTT ?
-
특징
- time-step별로 뒤(t)에서부터 앞으로 미분을 통해 모델에 사용된
parameter의 기울기(Gradient) 값이 구해지고, 이전 time-step(t-1)parameter세타의 기울기에 더해짐. - 💡 따라서, t가 0에 가까워질수록 기울기가 점점 더해져서
parameter세타의 기울기는 점점 커진다..!
- 파라미터는 같은 층 내에 시간(time-step)에 대해서는 공유된다..! (즉, 같다.)
- 하지만, 다른 신경망 layer 층 간에는 공유되지 않는다
- 💡 따라서, 각 층마다 다른
parameter가 존재 - 💡 맨 위층의
Hidden State는 각 time-step의 RNN 전체 출력값이 넘어감
- time-step별로 뒤(t)에서부터 앞으로 미분을 통해 모델에 사용된
- 단점
기울기 소실(Gradient Vanishing)문제- 긴 시퀀스를 훈련하기에 어렵다.
BPTT로 인해 역전파 수행시, 마치 time-step만큼의 계층이 있는 것과 같은 속성을 띔. ➡️ 깊은 네트워크 구조로부터기울기 소실문제 발생 (이는 과거다층 퍼셉트론(MLP)에서도 동일하게 발생했던 문제다..!)- 활성화 함수(Activation Function)으로
tanh 함수를 사용하는 것과 연관됨.
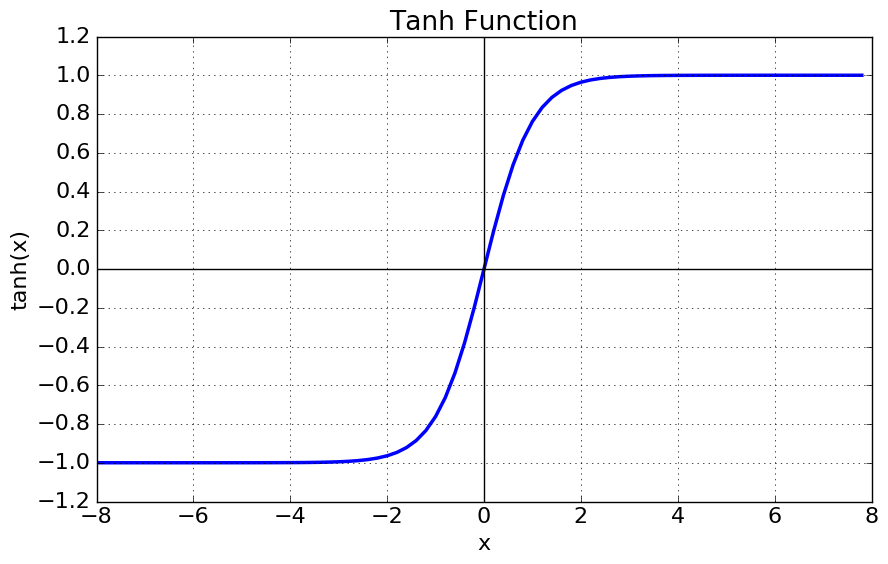
-tanh 함수에서는 양 끝(-1 또는 1)로 갈수록 기울기에0에 가까워 진다.
- 보완
-
활성화 함수(Activation Function)로
ReLU 함수사용
-
Redisual Connection의 등장ResNet(2015년)
- 논문명 :Deep Residual Learning for Image Recognition- arXiv
(https://arxiv.org/pdf/1512.03385.pdf)
- 주요 개념 : 함수를 새로 만드는 방법 대신에 residual function, 잔차 함수를 학습에 사용하는 것으로 layer를 재구성한다 ..?
-
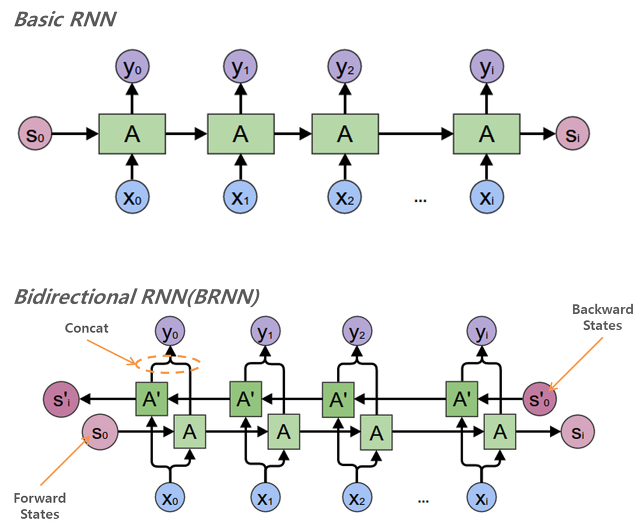
양방향 RNN
-
기존 정방향에 역방향이 추가된 구조.
-
각 layer마다 두 방향의 time-step별
Hidden State값이 이어붙여져서 다음 layer의 각 방향별 입력으로 사용됨. -
💡 정방향의
parameter와 역방향의parameter는 공유되지 않는다..!
-
💡 이전 time-step의 출력 값이 다음 time-step의 입력에 영향을 끼치지 않는 경우(즉,
자기회귀(AR, Auto-Regressive) 모델이 아닌 경우)에만 양방향 RNN을 사용할 수 있다..!
2. 장단기 메모리(Long Short-Term Memory, LSTM)
-
기존의 RNN은 가변 길이의 시퀀스를 입력 받아, 가변 길이의 시퀀스를 출력해줄 수 있는 모델이었으나, time-step이 길어질수록
기울기 소실문제로 인해, 앞의 데이터를 기억하지 못하는 단점이 보여짐 -
보완 방법론으로,
LSTM등장 -
1️⃣ 입력(X_t)와 2️⃣ 직전의 은닉 상태(Hidden State, h_t-1) /➕ 3️⃣ Cell State 변수, 4️⃣ Gate
-
정리가 잘 된 글 : https://wegonnamakeit.tistory.com/7
LSTM(1997년)
- 논문명 :LONG SHORT-TERM MEMORY- arXiv
(http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.676.4320&rep=rep1&type=pdf)
- 주요 개념 : RNN 처럼 직전 정보만 참고하는 것이 아니라, 그 전 정보를 고려해야 하는 경우(longer-term) 존재. 하지만 시퀀스가 있는 문장에서 문장 간의 간격(gap, 입력 위치의 차이)이 커질 수록, RNN은 두 두 정보의 맥락을 파악하기 어려워짐 ➡️ 이러한장기 의존성(Long-Term Dependency) 문제를 해결하고, 한참 전의 데이터도 함께 고려하여 출력을 만들어보자..!
- 장점
셀 스테이트와게이트를 활용해 기억하거나, 잊어버리거나, 출력하고자 하는 데이터의 양을 효과적으로 제어할 수 있음 (0~1 사이 값을 갖는sigmoid 함수와 관련)
- 단점
- 하지만,
parameter가 많아져 훈련 속도가 오래걸림 (수식이 복잡하고, 훈련도 무겁다..!) - 어느정도의 시간 축에 대해서는 해결을 했지만, 여전히 매우 긴 길이의 데이터에 대해서는 효과적으로 기억하지 못한다..! (특히,
다층 LSTM구조에서..😭 (💡 4개층 까지는 커버 가능하고 그 이상은Redisual Connection개념 활용해야 함))
- 하지만,
변형 구조의 LSTM
변형 LSTM(2017년)
- 논문명 :LSTM: A Search Space Odyssey- arXiv
(https://arxiv.org/pdf/1503.04069.pdf?fbclid=IwAR377Jhphz_xGSSThcqGUlAx8OJc_gU6Zwq8dABHOdS4WNOPRXA5LcHOjUg)
- 주요 개념 : 여러가지 LSTM 구조에 대한 실험..!자주 사용되는 변형 중 하나는, 게이트 값들이 이전 hidden state인 st−1에만 의존하지 않고 이전 내부 메모리인 ct−1에도 의존하도록 peephole 연결을 만드는 것입니다. (게이트 값을 계산하는 수식에 추가적으로 항 하나를 더해줌으로써). 이외에도 더 많은 변형이 존재하는데, LSTM: A Search Space Odyssey에서 여러가지 LSTM 구조의 장단점에 대해 실험적으로 폭넓게 평가되어 있습니다.
양방향 LSTM
-
정리가 잘 된 글 : [밑바닥부터 시작하는 딥러닝2 :: Ch 08 어텐션 (2) 양방향 LSTM] https://wegonnamakeit.tistory.com/25
양방향 LSTM(2018년)
- 논문명 :양방향 LSTM을 활용한 전력수요 데이터 예측 기법 연구- 한국소프트웨어감정평가학회 논문지
(http://www.i3.or.kr/html/paper/2018-1/(5)2018-1.pdf)
- 주요 개념: LSTM의 기본 성능에 ➕Attention매커니즘 개념이 함께 도입됨..! ✨ (Bi-LSTM의 Hidden State 간의 Self-Align..!)RNN이나 LSTM은 입력 순서를 시간 순대로 입력하기 때문에 결과물이 직전 패턴을 기반으로 수렴하는 경향을 보인다는 한계가 있다. 이 단점을 해결하는 목적으로 양방향 순한신경망(Bi-RNN)이 제안되었다. Bi-RNN은 기존의 순방향에 역방향을 추가하여, 은닉층에 추가하여 성능을 향상시켰다.
그러나 데이터 길이가 길고 층이 깊으면, 과거의 정보가 손실되는 단점이 있다. 이를 극복하기 위해 제안된 알고리즘이 양방향 LSTM이다. (Ko et al., 2018)
- 대회에서 모델 적용한 글: https://www.slideshare.net/JangWonPark8/nlp-challenge (✨ 데이콘 대회에서 참고해보기..!)
3. 게이트 순환 유닛(Gated Recurrent Unit, GRU)
-
LSTM의 간소화 모델GRU(2014년)
- 논문명 :Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation- arXiv
(https://arxiv.org/pdf/1406.1078.pdf)
- 주요 개념 : (1) LSTM의 forget gate와 input gate를 통합하여 하나의 'update gate'를 만든다. (2) Cell State와 Hidden State를 통합한다. ➡️ GRU는 LSTM에 비하여 파라미터수가 적기 때문에 연산 비용이 적게 들고, 구조도 더 간단하지만, 성능에서도 LSTM과 비슷한 결과를 낸다.
-
장점
- LSTM 대비 게이트의 숫자 줄어듦 & 파라미터 줄어듦
- 간단하면서도 LSTM과 성능이 비슷
-
단점
- LSTM과 GRU는 학습률, Hidden size 등 하이퍼파라미터가 다르므로, 파라미터 셋팅을 다시 찾아내야 함.
-
정리 및 LSTM과 비교가 잘 된 글 : https://hyen4110.tistory.com/26 [Hyen4110]
GRU, LSTM, RNN 실험결과 비교
GRU/LSTM/RNN 실험(2014년)
- 논문명 :Empirical evaluation of gated recurrent neural networks on sequence modeling.- arXiv
(https://arxiv.org/pdf/1412.3555.pdf?ref=hackernoon.com)
- 주요 개념 : 많은 문제들에서 두 모델 모두 좋은 성능을 보여주고 있고, 레이어 사이즈같은 파라미터 튜닝을 잘 하는 것이 모델을 고르는 것보다 더 중요. GRU는 파라미터 수가 적어서 (U와 W가 더 작다) 학습 시간이 더 짧게 걸리고 보다 적은 데이터로도 학습이 가능할 수 있겠지만, 반대로 말하면 충분한 수의 데이터가 있을 경우에는 LSTM의 우수한 모델링 파워가 더 좋은 결과를 보여줄 수도 있다.
➕ 그래디언트 클리핑
