📖랜덤 포레스트 (Random Forest) 분류모형
랜덤 포레스트는 분류, 회귀분석 등에 사용되는 앙상블 학습방법의 일종으로, 훈련 과정에서 구성한
다수의 결정 트리로 부터 분류 또는 평균 예측치(회귀 분석)를 출력함으로써 동작한다.
- Decision Tree에 비해 높은 정확성, 불완전성을 제거.
- 간편하고 빠른 학습 및 테스트 알고리즘
- 변수 소거 없이 수천 개의 입력 변수들을 다루는 것이 가능
- 임의화를 통한 좋은 일반화 성능
- 다중 클래스 알고리즘 특성
- 앙상블 기법의 일종으로 Bagging을 사용
간단하게 말해보자면 Decision Tree Classifier (결정나무) 분류 모델을 여러개 사용하여 정확성 높고 완전한 모델을 만들 수 있다는 것 같다.
여기서 Decision Tree Classifier (결정나무) 모델의 내용을 알아야하는데
결정나무출처
이곳을 참조하면 좋을 것 같다.
이렇게 여러개의 모델을 조화롭게 학습시켜서 더 정확한 결과를 예측할 수 있게 모델을 만드는 것을 앙상블이라고 하나보다.
📝앙상블(Ensemble)
여러 개의 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법입니다. 앙상블 학습의 핵심은 여러 개의 약 분류기 (Weak Classifier)를 결합하여 강 분류기(Strong Classifier)를 만드는 것입니다. 그리하여 모델의 정확성이 향상됩니다.
앙상블 학습법에는 2가지가 있는데
- 배깅(bagging)
- 부스팅(boosting)
여기서 배깅기법을 활용한 모델이 바로 랜덤포레스트 이다.
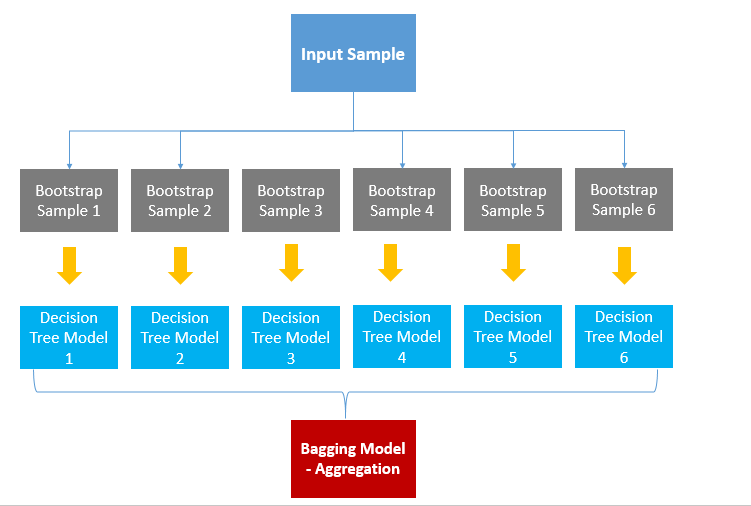
사진출처
위의 이미지는 배깅을 설명하는 이미지이며, 보면서 설명하자면 각자 샘플을 학습한 DecisionTree 모델들이 6개 있는데 각 모델들 마다 예측값이 다 다를 수 있겠죠?
만약 4개의 모델들은 'A'라고 예측했고 나머지 2개의 모델은 'B' 라고 예측했다면
투표로 인해 A가 최종결과가 되는 것입니다.
📖RandomForestClassifier()
sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)- RandomForestClassifier의 파라미터
n_estimators : 모델에서 사용할 트리 갯수(학습시 생성할 트리 갯수)
criterion : 분할 품질을 측정하는 기능 (default : gini)
max_depth : 트리의 최대 깊이
min_samples_split : 내부 노드를 분할하는데 필요한 최소 샘플 수 (default : 2)
min_samples_leaf : 리프 노드에 있어야 할 최소 샘플 수 (default : 1)
min_weight_fraction_leaf : min_sample_leaf와 같지만 가중치가 부여된 샘플 수에서의 비율
max_features : 각 노드에서 분할에 사용할 특징의 최대 수
max_leaf_nodes : 리프 노드의 최대수
min_impurity_decrease : 최소 불순도
min_impurity_split : 나무 성장을 멈추기 위한 임계치
bootstrap : 부트스트랩(중복허용 샘플링) 사용 여부
oob_score : 일반화 정확도를 줄이기 위해 밖의 샘플 사용 여부
n_jobs :적합성과 예측성을 위해 병렬로 실행할 작업 수
random_state : 난수 seed 설정
verbose : 실행 과정 출력 여부
warm_start : 이전 호출의 솔루션을 재사용하여 합계에 더 많은 견적가를 추가
class_weight : 클래스 가중치
