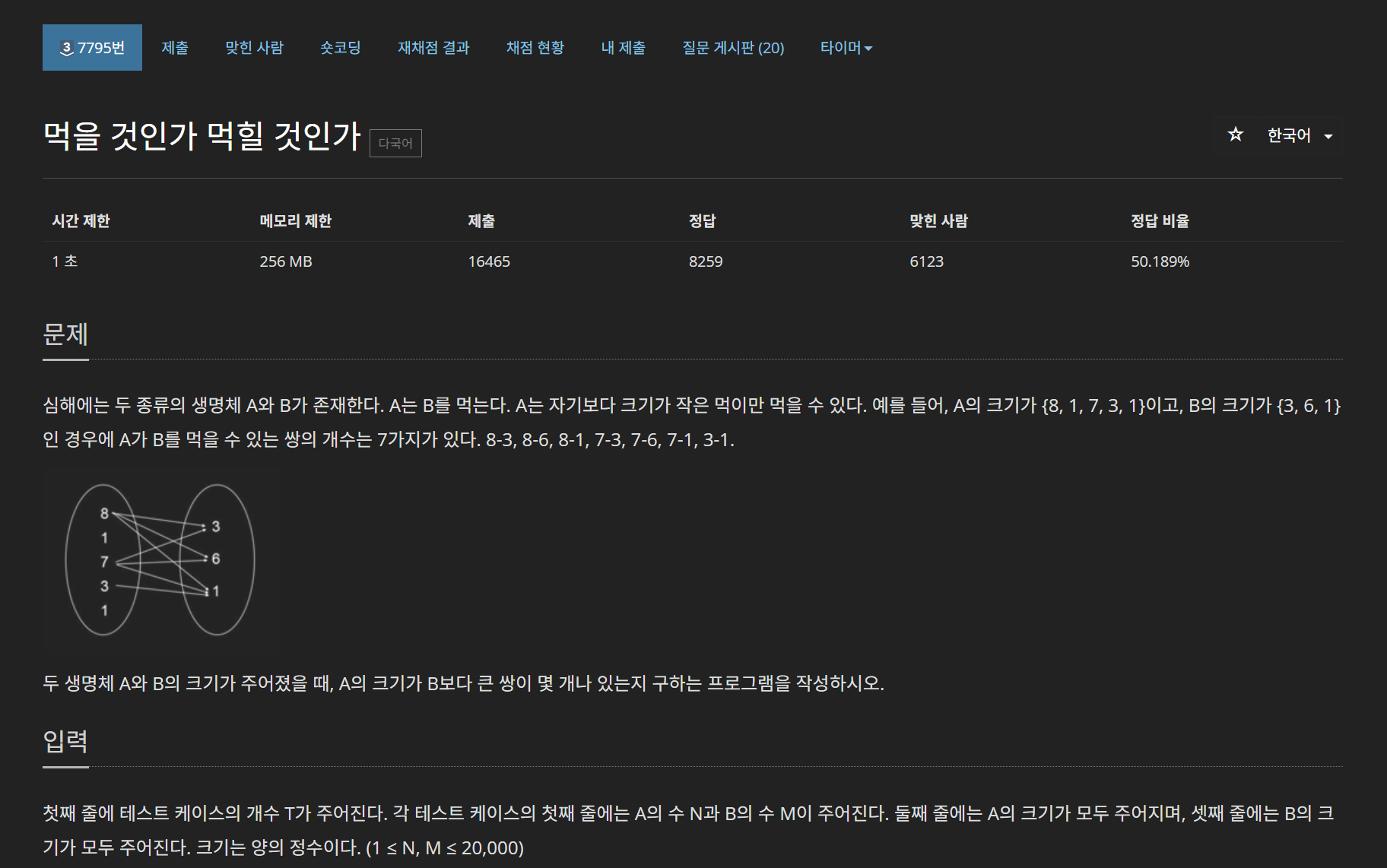
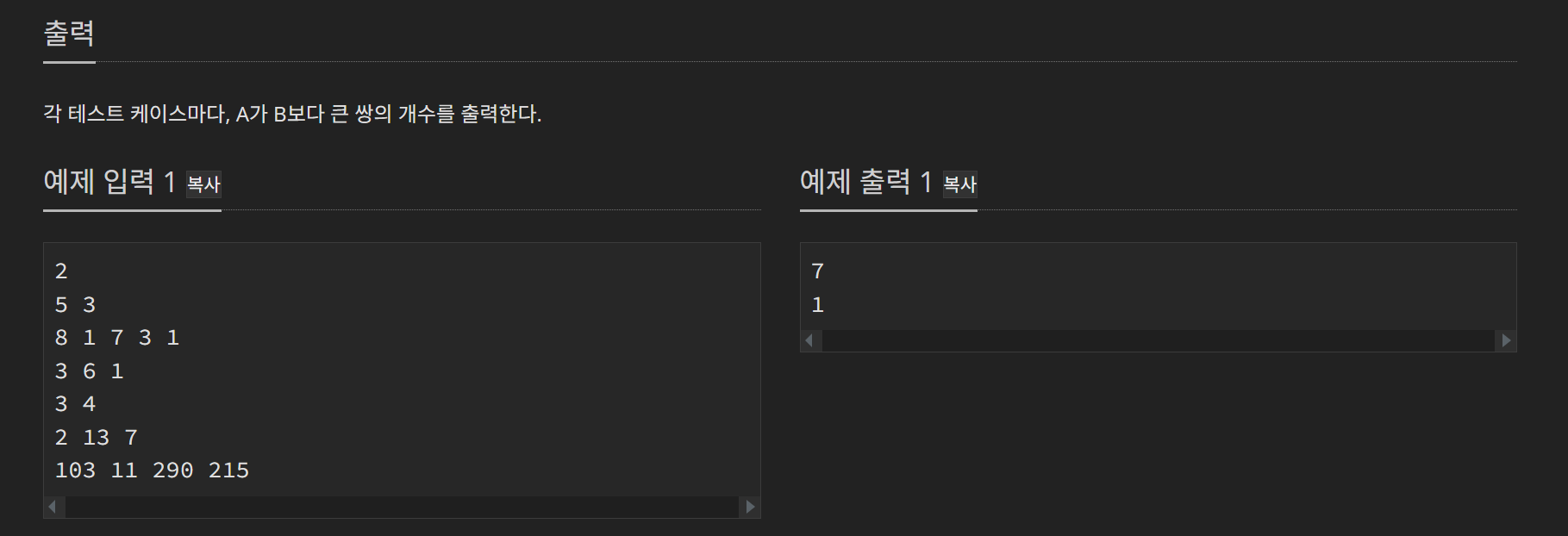
이 문제는 제일 처음 t 개의 테스트 케이스가 주어지고
그다음 집합 A , B의 크기가 주어진다.
그 다음 각각의 크기에 맞는 값들이 주어지고
해당 값들을 비교하여 B보다 A가 더 큰 경우의 수를 누적해서 출력한다.
이 과정을 t번 반복하는 문제이다.
보면 t에 대한 언급은 크게 없으니 시간 복잡도에 대해 큰 문제가 없을 것 같지만,
A,B의 크기인 N,M의 범위가 1 <= N,M<= 20,000 이므로
N,M이 각각 최대 값인 20,000 일 경우 단순 서로 쌍으로 곱하면
400,000,000으로 런타임 에러가 발생하게 된다.
따라서, N과 M을 O(N) 으로 구하는게 중요한 문제이다.
제일 처음 접근한 방식은, 집합 A의 인자들을 하나씩 B에 추가하고,
추가함과 동시에 해당 값보다 작은 값들을 구하는 느낌으로 고안했다.
이 과정에서 수업시간에 배웠던 stream과 람다를 활용해보자! 라는 느낌으로 구현했다.
package test12;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.StringTokenizer;
public class Ox12_Q5_1 {
// 백준 7795 S3 먹을 것인가 먹힐 것인가
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
StringTokenizer st;
int t = Integer.parseInt(br.readLine());
// 테스트 케이스 수 만큼 입력받음
for(int i = 0 ; i<t; i++) {
int cnt = 0;
st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
// 데이터 배열에 저장
int [] aArr = new int[n];
List<Integer> bArr = new ArrayList();
st = new StringTokenizer(br.readLine());
for(int j = 0; j<n; j++) {
aArr[j] = Integer.parseInt(st.nextToken());
}
st = new StringTokenizer(br.readLine());
for(int j = 0; j<m; j++) {
bArr.add(Integer.parseInt(st.nextToken()));
}
// bArr 정렬 후 인덱스 번호 체크
Collections.sort(bArr);
// A가 B보다 큰 쌍의 개수 체크
for(int j = 0; j<aArr.length; j++) {
int temp = aArr[j];
cnt += (int) bArr.stream().filter(x->x<temp).count();
}
sb.append(cnt).append("\n");
}// for fin
System.out.println(sb.toString().trim());
br.close();
}
}
보면 값을 각각 다 입력 받은 후, bArr을 정렬한 후
aArr의 요소를 추가하여 해당 요소보다 작은 count를 구하는 방식이다.
stream을 활용하였다.

망했다.
애초에 이 방식은 기대도 안하긴 했다. 그냥 스트림 연습하려고 썼다ㅎ
다음 방식은 bArr을 정렬하기 전에, aArr의 요소를 먼저 집어넣고
정렬한 다음 indexOf를 활용하는 방식이다.
package test12;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.StringTokenizer;
public class Ox12_Q5_2 {
// 백준 7795 S3 먹을 것인가 먹힐 것인가
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
StringTokenizer st;
int t = Integer.parseInt(br.readLine());
// 테스트 케이스 수 만큼 입력받음
for(int i = 0 ; i<t; i++) {
int cnt = 0;
st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
// 데이터 배열에 저장
int [] aArr = new int[n];
List<Integer> bArr = new ArrayList();
st = new StringTokenizer(br.readLine());
for(int j = 0; j<n; j++) {
aArr[j] = Integer.parseInt(st.nextToken());
}
st = new StringTokenizer(br.readLine());
for(int j = 0; j<m; j++) {
bArr.add(Integer.parseInt(st.nextToken()));
}
// A가 B보다 큰 쌍의 개수 체크
for(int j = 0; j<aArr.length; j++) {
int temp = aArr[j];
// bArr 복제
List<Integer> bArr2 = new ArrayList<>(bArr);
bArr2.add(temp);
// bArr2 정렬 후 인덱스 번호 체크
Collections.sort(bArr2);
cnt += bArr2.indexOf(temp);
}
sb.append(cnt).append("\n");
}// for fin
System.out.println(sb.toString().trim());
br.close();
}
}

?
이번엔 진짜 될 줄 알았는데 사실 실패하길래 약간 놀랬다.
실은 indexOf(n)의 시간 복잡도가 O(1)인줄 알았는데, 알고보니 O(n)이였다
ㅎㅎ그럼 틀려야지
사실 문제 특성상 데이터 입력 부분은 달라질 것이 없으니
무조건 정렬에서 갈리겠다고 생각했다. 이에 따라 고민 하던 중
예전에 이진탐색에 대해 했던 적이 있어서 관련 방식으로 고안해봤다.
package test12;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.StringTokenizer;
public class Ox12_Q5_3 {
// 백준 7795 S3 먹을 것인가 먹힐 것인가
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
StringTokenizer st;
int t = Integer.parseInt(br.readLine());
// 테스트 케이스 수 만큼 입력받음
for(int i = 0 ; i<t; i++) {
int cnt = 0;
st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
// 데이터 배열에 저장
int [] aArr = new int[n];
int [] bArr = new int[m];
st = new StringTokenizer(br.readLine());
for(int j = 0; j<n; j++) {
aArr[j] = Integer.parseInt(st.nextToken());
}
st = new StringTokenizer(br.readLine());
for(int j = 0; j<m; j++) {
bArr[j] = Integer.parseInt(st.nextToken());
}
Arrays.sort(bArr);
// A가 B보다 큰 쌍의 개수 체크
for(int j = 0; j<aArr.length; j++) {
int temp = aArr[j];
cnt += compareAB(temp,bArr);
}
sb.append(cnt).append("\n");
}// for fin
System.out.println(sb.toString().trim());
br.close();
}
// 이진 탐색으로 값 비교
public static int compareAB(int temp, int bArr[]) {
int left = 0;
int right = bArr.length;
// 왼쪽이 오른쪽보다 작은 경우 fin
while(left<right) {
int middle = (left+right)/2;
// 현재 값이 중앙 값보다 큰 경우
if(temp>bArr[middle]) {
left = middle + 1;
}
// 현재 값이 중앙 값보다 작은 경우
else {
right = middle;
}
}
return left;
}
}
현재의 비교할 요소와 배열 bArr을 인자로 받는다.
다음으로 비교할 요소 temp와 bArr의 중앙값을 계속해서 비교하는데,
만약 중앙값보다 현재 값이 크다면 left는 중앙+1,
작다면 right는 중앙값으로 체크하는 방식을 반복한다.
이 과정을 반복하여 while문 밖으로 나오게 되면
temp보다 작은 값의 개수를 return하게 된다.

굿
