
졸업 작품 크롬 익스텐션 개발 중 HTML 파일을 text 형식으로 바꿔서 백엔드로 보내줘야 하는 기능이 있다.
HTML 파일을 text로 바꾸게 하는 건 어렵지 않았지만, 바꾸고 나서 내용의 문제가 있었다.
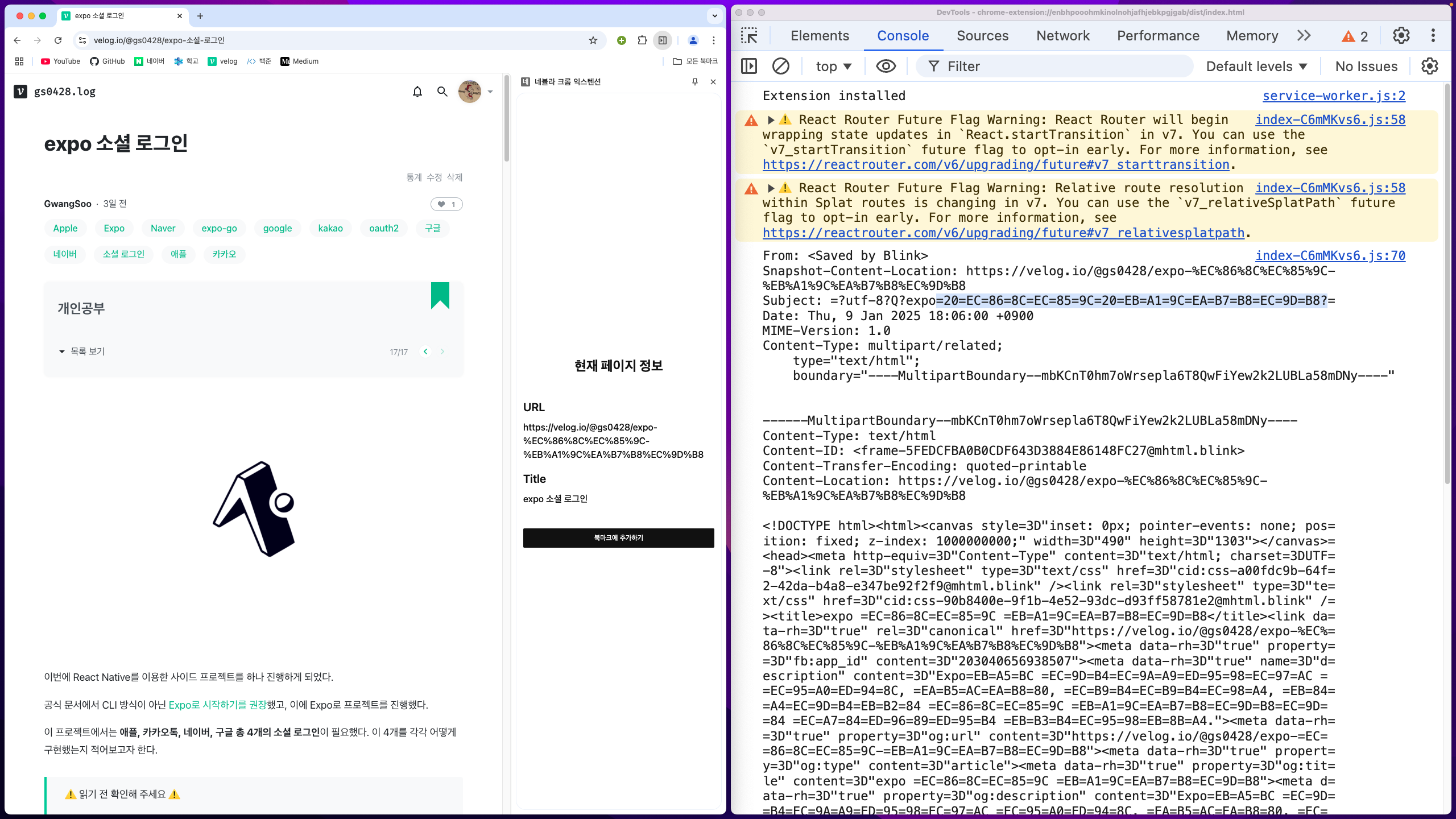
선택한 부분처럼 한글 부분이 제대로 디코딩이 안 되는 것이었다. 이유를 찾다 보니 quoted-printable 인코딩 방식 때문이었다.
quoted-printable
quoted-printable 인코딩 방식은 인코딩한 메시지를 디코딩 하지 않더라도 ASCII 문자는 그대로 볼 수 있도록 하는 방식이다. 즉, 영문과 숫자 등의 ASCII 7bit 문자는 그대로 두고 한글 등 8bit 문자만 인코딩한다.
크롬 익스텐션 API 기능 중 하나인 chrome.pageCapture.saveAsMHTML를 사용해서 HTML을 추출하고 있는데, 이는 MHTML 형식으로 데이터가 나오게 된다.
🤔 MHTML이란?
HTML에서는 사진과 같은 자원들을 참조하는 방식이지만, MHTML은 파일 내부에 인코딩 된 형태로 포함하고 있어 별도의 참조할 파일이 필요하지 않다.
-
HTML
<img src="image.jpg" /> -
MHTML
<img src="data:image/jpeg;base64,..." />
이때 MHTML의 인코딩 결과가 quoted-printable 일 수도 있다고 한다.
실제로 처음 첨부한 사진을 보면 중간 부분에 Content-Transfer-Encoding: quoted-printable이라는 내용을 볼 수 있다.
그래서 어떻게 해결했는데?
quoted-printable, libmime 같은 라이브러리들을 사용해서 변환을 시도했지만 좀처럼 되지 않았다. 그러다가 lettercoder라는 라이브러리를 발견했다.
기존에 사용했던 라이브러리들은 quoted-printable로 인코딩된 문자열을 넣으면 디코딩 된 문자열을 반환해 주는 방식이었다.
하지만 lettercoder 라이브러리는 문자열 반환이 아닌, Uint8Array 형식으로 반환을 해주었다. 이를 TextDecoder를 통해 utf-8 형식으로 디코딩 하니 한글도 정상적으로 출력되는 것을 확인할 수 있었다.
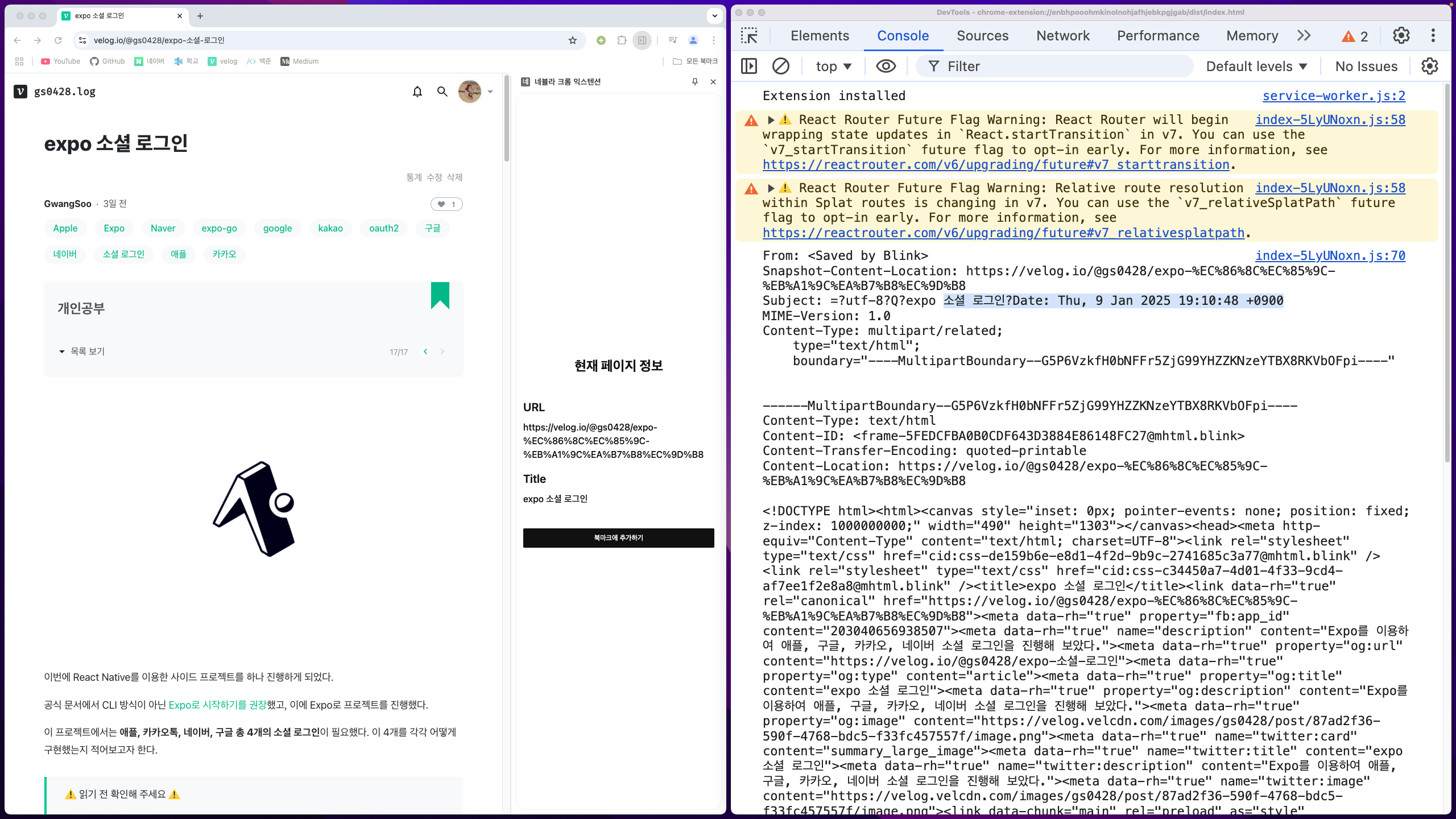
전체 코드는 아래와 같다.
import { decodeQuotedPrintable } from "lettercoder";
export const getHtmlText = async () => {
chrome.tabs.query({ active: true, currentWindow: true }, (tabs) => {
chrome.pageCapture.saveAsMHTML({ tabId: tabs[0].id as number }, async (data) => {
const quotedPrintableData = await data!.text();
const decodedData = decodeQuotedPrintable(quotedPrintableData);
const textDecoder = new TextDecoder("utf-8");
const htmlContent = textDecoder.decode(decodedData);
return htmlContent;
});
});
};마무리하며
npm 검색결과 상위에 있는 것들이 모두 문제 해결의 정답이 될 수 없다는 것을 알게 되었다.
