
😎 오늘은 간단히 kogpt2 모델을 BentoML로 서빙해보도록 하겠습니다!
😅 지난번 글은 BentoML v1.0-pre 버전이었지만, Transformers 관련 API가 BentoML 0.11.1(stable)에 존재하는 이유로, 오늘 환경은 BentoML==0.11.1 입니다!
(transformers==4.18.0 / torch==1.11.0)
kogpt2?
🤗 'NLP의 민주화' 라는 컨셉으로 유명한 huggingface의 Transformer 기반으로 작성된 "한국어 생성 모델"입니다.
huggingface? Transformer?
😉 Self-Attention 메커니즘을 사용한 Transformer 등장으로 강력한 성능 향상을 이뤄낸 이후, 해당 메커니즘을 차용한 다양한 NLP 도메인 D/L 알고리즘들이 대거 등장하였습니다.
😄 가장 대표적인 것들이 GPT(생성), BERT(Pre-train) 등이 있습니다.
😋 그러한 다양한 알고리즘들을 간단히 API로 사용할 수 있도록 구현해 놓은 아주 고마운 패키지이죠 :)
😌 최근은 더욱 발전해서 docker hub처럼 weight hub까지 구축하여 자유롭게 Data Scientist들이 작성한 모델들을 배포까지 API단에서 가능하게하는 플랫폼 역할까지 수행하고 있습니다.
kogpt2!
😁 결국, 문장을 넣으면 해당 문장 기반으로 말을 이어서 작성하는 "한국어" NLP 생성 모델입니다!
# 예시
from transformers import PreTrainedTokenizerFast
tokenizer = PreTrainedTokenizerFast.from_pretrained("skt/kogpt2-base-v2",
bos_token='</s>', eos_token='</s>', unk_token='<unk>',
pad_token='<pad>', mask_token='<mask>')
# print(tokenizer.tokenize("안녕하세요. 한국어 GPT-2 입니다.😤:)l^o"))
import torch
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2')
text = '달 밝은 밤'
input_ids = tokenizer.encode(text, return_tensors='pt')
gen_ids = model.generate(input_ids,
max_length=256,
repetition_penalty=4.0,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
use_cache=True)
generated = tokenizer.decode(gen_ids[0])
print(generated)
>>> 달 밝은 밤하늘을 볼 수 있는 곳.</d> 지난해 12월 31일 오후 2시 서울 종로구 세종문화회관 대극장에서 열린 ‘2018 대한민국연극제’ 개막식에는 배우들과 관객들이 대거 참석했다.
이날 개막한 연극제는 올해로 10회째를 맞는 국내 최대 규모의 공연예술축제다.
올해는 코로나19로 인해 온라인으로 진행됐다. ...BentoML!
https://docs.bentoml.org/en/0.13-lts/quickstart.html#example-hello-world
https://docs.bentoml.org/en/0.13-lts/frameworks.html#transformers
https://sooftware.io/bentoml/
Script
😆 2개 script로 구성된 파일입니다.
😋 main.py에서는 transformers 관련 함수를 로드하고, 해당 변수를 service에 "pack"합니다.
😎 그리고 BentoML의 point인 Service는 bento_service.py에서 구현한 것을 import하여 사용합니다.
# main.py
import torch
from transformers import GPT2LMHeadModel
from transformers import PreTrainedTokenizerFast
from bento_service import TransformerService
model_name = 'kogpt2'
model = GPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2')
tokenizer = PreTrainedTokenizerFast.from_pretrained("skt/kogpt2-base-v2",
bos_token='</s>', eos_token='</s>', unk_token='<unk>',
pad_token='<pad>', mask_token='<mask>')
service = TransformerService()
artifact = {'model' : model, 'tokenizer' : tokenizer}
service.pack("kogpt2Model", artifact)
saved_path = service.save()😏 BentoService class를 상속받아 TransformerService는 작성됩니다.
✨ 그리고, decorator는 해당 포맷으로 사용한다고 이해하면 사용에는 문제 없을것으로 보입니다.
✔ @env는 inference 위한 package / version을 정의합니다.
✔ @artifacts는 BentoML에서 미리 작성된 Artifact중 어떤 것을 사용할지 명시하며, Artifact의 이름을 선언합니다.
✔ @api는 input의 format을 미리 결정하며, 모델이 serve되었을 때 api로 바로 사용할 수 있게 하는 decorator입니다.
😜 그리고, predict의 로직을 작성해주면 됩니다.
✔ main.py에서 넘겨준 artifact를 사용하기 위해, @artifacts decorator에서 설정한 "kogpt2Model"을 사용하여 model과 tokenizer를 사용하는 것을 확인할 수 있습니다.
# bento_service.py
from bentoml import env, artifacts, api, BentoService
from bentoml.adapters import JsonInput
from bentoml.frameworks.transformers import TransformersModelArtifact
@env(pip_packages=["transformers==4.18.0", "torch==1.11.0"])
@artifacts([TransformersModelArtifact("kogpt2Model")])
class TransformerService(BentoService):
@api(input=JsonInput(), batch=False)
def predict(self, parsed_json):
src_text = parsed_json.get("text")
model = self.artifacts.kogpt2Model.get("model")
tokenizer = self.artifacts.kogpt2Model.get("tokenizer")
input_ids = tokenizer.encode(src_text, return_tensors="pt")
gen_ids = model.generate(input_ids,
max_length=256,
repetition_penalty=4.0,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
use_cache=True)
output = tokenizer.decode(gen_ids[0])
return outputModel Serve!
😀 먼저, service.save() 로직이 작성되어 있는 main.py를 실행해줍니다!
# bash
python main.py😜 정상적으로 수행되면, 아래와 같은 메시지와 함께 Service가 저장되었음을 알 수 있습니다.
✨ 실제로, 해당 디렉토리를 확인하면 requirements.txt / Dockerfile 등 배포를 위한 파일들이 자동으로 생성되었음을 확인할 수 있습니다.
[2022-04-19 23:49:29,091] INFO - BentoService bundle 'TransformerService:20220419234923_5080D7' saved to: /home/kang/bentoml/repository/TransformerService/20220419234923_5080D7😆 그리고, 해당 Service를 local에서 run 하면 Server가 뜨게 됩니다!
# bash
bentoml serve TransformerService:latest
>>> 2022-04-19 23:51:14,614] INFO - Getting latest version TransformerService:20220419234923_5080D7
[2022-04-19 23:51:14,622] INFO - Starting BentoML API proxy in development mode..
[2022-04-19 23:51:14,623] INFO - Starting BentoML API server in development mode..
[2022-04-19 23:51:14,743] INFO - Your system nofile limit is 4096, which means each instance of microbatch service is able to hold this number of connections at same time. You can increase the number of file descriptors for the server process, or launch more microbatch instances to accept more concurrent connection.
======== Running on http://0.0.0.0:5000 ========
(Press CTRL+C to quit)
* Serving Flask app 'TransformerService' (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:54471 (Press CTRL+C to quit)😉 http://127.0.0.1:54471 로 들어가게 되면, Swagger에서 간편하게 값을 확인해 볼 수 있습니다 :)
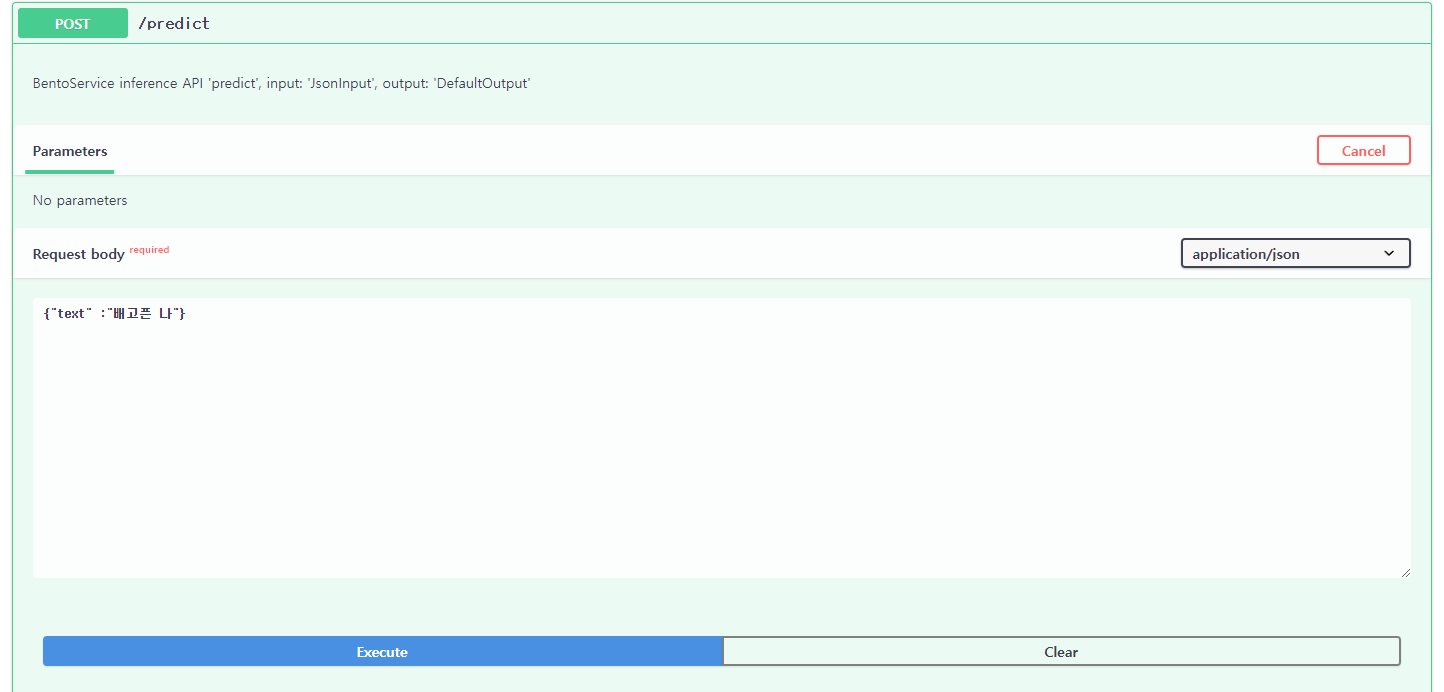
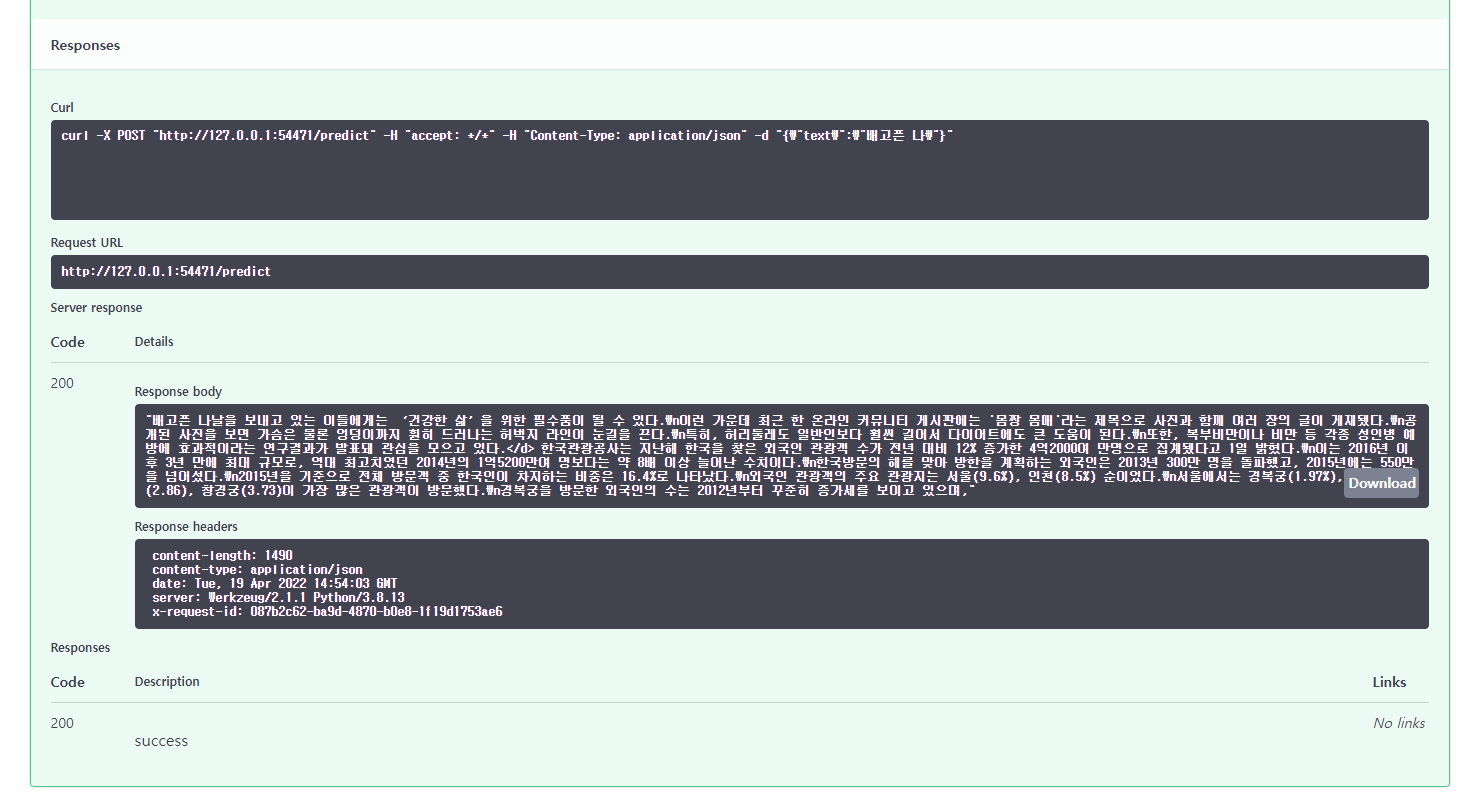
✨ 물론, python requests package나 curl를 활용하여 5000번 port로 요청하여도 됩니다 :)
import requests
res = requests.post("http://127.0.0.1:5000/predict", json={"text": "가끔 이상한 말도 해요"})
print(res.text)글을 정리하며
😃 kogpt2를 사용한 결과들을 보니, 말 자체는 되지만 결국 약간 문맥에 맞지 않는 단어들을 연속해서 뱉는 부분이 있음을 확인하였습니다 ;<
🤗 kogpt2를 제 입맛에 맞게 재밌는 모델을 만들어서 다음 글에서는 serving 해보도록 하겠습니다 :)
💕 그리고, https://sooftware.io/bentoml/ 의 글을 공부하며 많은 도움을 얻었습니다. 감사합니다! 👍
😉 그럼 오늘도 읽어주셔서 감사합니다!

Hello
Thank you for this. I am having hard time understanding BentoML artifacts for various frameworks.
In my case, my colleague was using below model from Transformers library's Pipeline module to get the emotions score for the imput text:
classifier = pipeline("text-classification",model='bhadresh-savani/distilbert-base-uncased-emotion', return_all_scores=True)
Now, I need to create a rest API for this. I using bentoml. I am just not able to understand how to use pipeline instance in the Artifacts wrapper.
I tried below approach:
Writing bentoml code
import re
import bentoml
from transformers import DistilBertTokenizer
from transformers import DistilBertModel
from transformers import DistilBertForSequenceClassification
from bentoml.adapters import JsonInput
from bentoml.frameworks.transformers import TransformersModelArtifact
@bentoml.env(pip_packages = ["transformers==4.18.0", "torch==1.11.0"])
@bentoml.artifacts([TransformersModelArtifact('distilbert')])
class DistillBertService(bentoml.BentoService):
ds = DistillBertService()
MODEL_NAME = 'distilbert-base-cased'
model = DistilBertModel.from_pretrained(MODEL_NAME)
tokenizer = DistilBertTokenizer.from_pretrained(MODEL_NAME)
artifact = {"model": model, "tokenizer": tokenizer}
ds.pack("distilbert", artifact)
saved_path = ds.save()
When I hit request, I get below error:
File "/home/dd00740409/bentoml/repository/DistillBertService/20220421051733_82868D/DistillBertService/distill_bert_service_with_preprocessing.py", line 41, in predict
output = model.generate(input_ids, max_length=50)
File "/home/dd00740409/.conda/envs/distill-bert/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, kwargs)
File "/home/dd00740409/.conda/envs/distill-bert/lib/python3.7/site-packages/transformers/generation_utils.py", line 1263, in generate
model_kwargs,
File "/home/dd00740409/.conda/envs/distill-bert/lib/python3.7/site-packages/transformers/generation_utils.py", line 1649, in greedy_search
next_token_logits = outputs.logits[:, -1, :]
AttributeError: 'BaseModelOutput' object has no attribute 'logits'
Can u guide a bit?
Thanks