아래의 글은 Databricks의 "The Big Book of MLOps"를 정리한 것입니다.
link : https://www.databricks.com/wp-content/uploads/2022/09/The-Big-Book-of-MLOps-v6-082322.pdf
Introduction
- ModelOps + DataOps + DevOps
- 시간은 빠르게 흐르고, AI 모델과 Framework는 빠르게 낡아간다.
- 그리고 이것을 변경하는 것은 인적, 시간적으로 큰 Cost가 요구된다.
- 이러한 부분을 훨씬 효율적으로 관리하며 변경할 수 있는 System ⇒ MLOps!
MLOps is a set of processes and automation to manage models, data and code to meet the two goals of stable performance and long-term efficiency in ML systems. MLOps = ModelOps + DataOps + DevOps.
Guding principles
- Two Goal : stable performance and long-term efficiency
business goals in mind를 항상 기억하라
- ML의 가장 큰 목적은 data-driven decision / product 을 가능케 하는 것
- MLOps의 가장 큰 목적은 data-driven app. remain stable & continue to have positive impace on biz.
- MLOps 개발의 긍정적 effect를 고려하라 : new biz. use-case? team’s productity? reduce Ops. cost or risk?
Data-centric approach to ML을 가져라
- Data Quality에 집중하라
- Do Everything in One Platform : 파편화 X
modular fashion으로 MLOps를 구현하라
- testing
- future code refactoring
Process에 따른 Automation을 수행하라
- Automation is good! : lower risk of human error & improving productivity
- 어떤 일은 꼭 사람이 봐야 함
- 완전 자동화보다는 필요하다면, 사람이 해야 할 일을 잘 나누는 것이 좋음
MLOps Fundamentals
Semantics of dev / staging / prod
- ML Workflow : code + models + data
- code
- Git based management
- branch의 각 역할은 System에서 정하기 나름
- models
- model과 code의 update 시기가 가끔 따로 놀 때 (asynchrononusly)할 때가 있다.
- model update시 감싸고 있는 system code가 구지 바뀔 필요는 없음 : 그 역도 성립
- loose coupling of code & model ⇒ good for flexibility
- model과 code의 update 시기가 가끔 따로 놀 때 (asynchrononusly)할 때가 있다.
- data
- dev / stg / prod 환경별 data 접근을 다르게 설정 (only RW in prod for Data Quality)
- controlled by table access controls or cloud storage permissions
- dev / stg / prod 환경별 data 접근을 다르게 설정 (only RW in prod for Data Quality)
- code
- develop (dev) ⇒ test (staging) ⇒ deploy (prod)
- code is live product : small human error in dev ⇒ could be big risk in prod
Execution Environments
- Containerized (보통)
- Delta Lake
ML Deployment Patterns
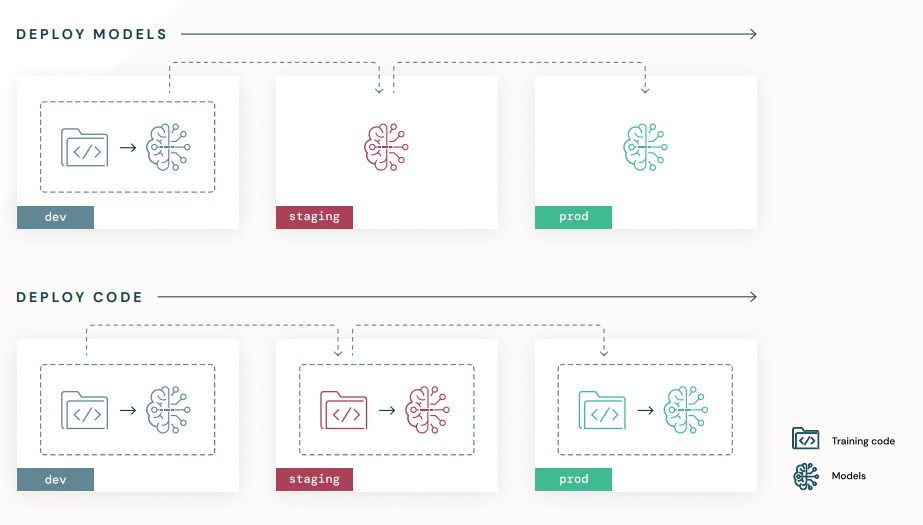
- Deploy models
- dev 학습 후 ‘model’을 staging / prod에 배포
- training cost is expensive
- 그러나 dev환경에서 prod data 접근이 불가능한 경우도 존재
- Automated Model Retraining X
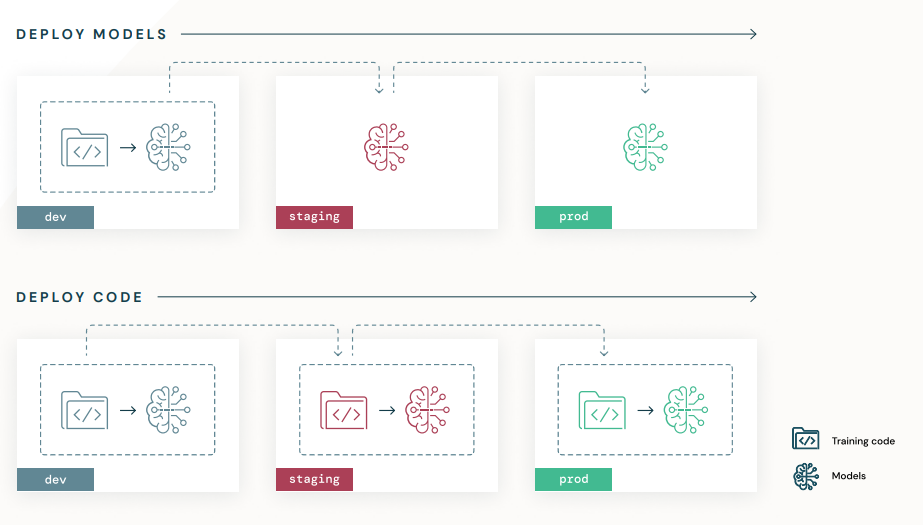
- Deploy code
- dev의 ‘code’를 staginig / prod에 배포
- 각 환경에서 동일 code로 model 학습
- 여러번의 검증으로 보다 확실한 성능 확인이 가능
- DS에게 code template 교육 자체가 learning curve가 너무 큼 : Workflow가 좋음
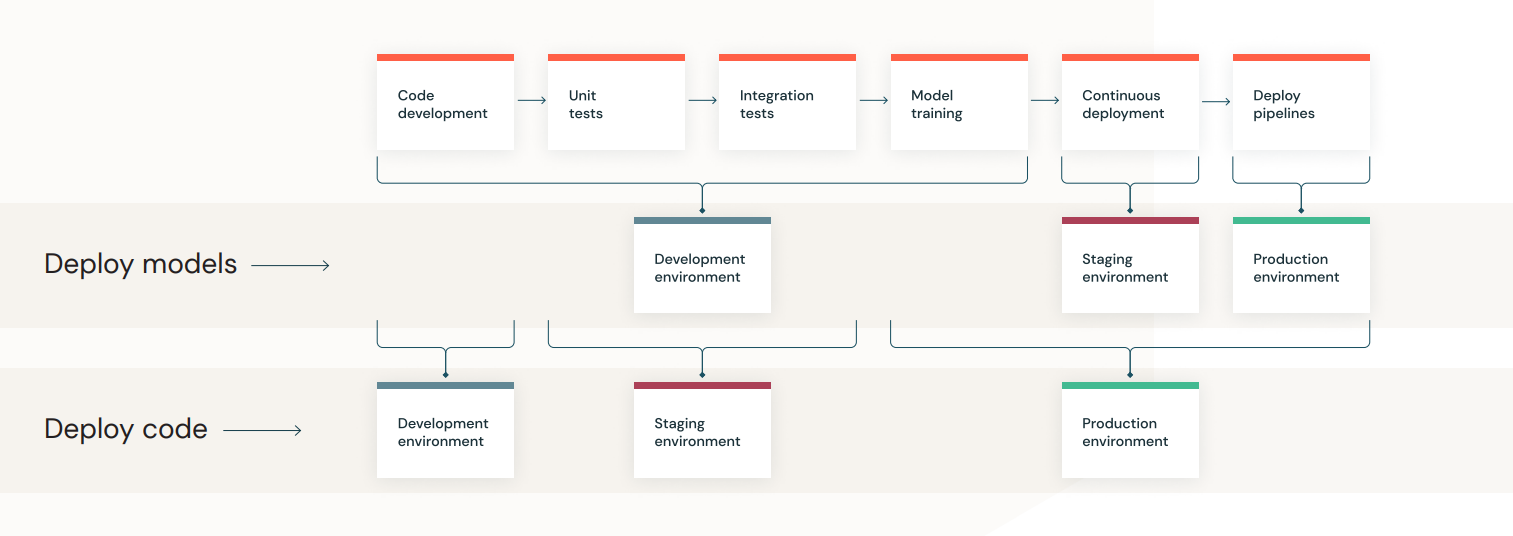
- HyVIS는 ‘Deploy Code’ Pattern
MLOps Architecture & Process
Data Lakehouse
- Data Lake + Data Warehouse : High Performance with low-cost
MLflow
- end-to-end ML lifecycle
- Components
- Tracking
- Models
- Model Registry
Databricks and MLflow Autologging
- no code solution
- automatic experiment tracking for ML training sessions
Feature Store
- centralized repository of features
MLflow Model Serving
- REST endpoint using Model Registry
Databricks SQL
- SQL with dashboard
Databricks Workflows and Jobs
Reference Architecture
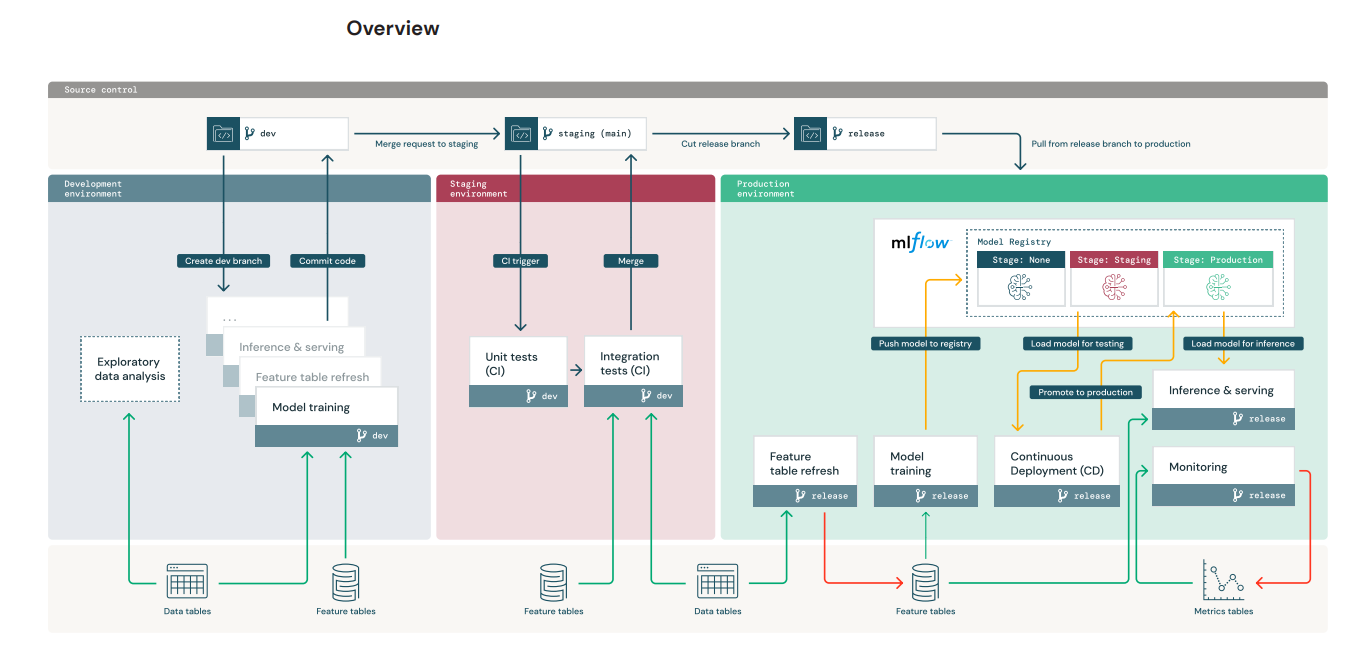

- Dev : Pipelines and models are prototyped
- DS는 prod data를 dev 환경에서 EDA 후 Feature 생성 및 Model Trainig
- 학습된 Model 및 pipeline code는 MLflow Registry 저장
- 작성 완료된 code는 dev로 commit
- Staging : Unit test & CI Test
- dev branch가 staging으로 pull (merge) request 되면 triggered
- ML Engineer의 CI Pipeline Test
- Feature Store Test
- Model Training Test : small dataset / low iters
- Model Deployment Test : REST APIs
- Inference Test
- Model Monitoring Test
- Test 성공시 Production 단계로 이동
- Prod : Based on that code, model training and Push MLflow Registry ⇒ CD
- MLflow 적극 활용
- ML Engineer’s role : Pipeline / Monitoring
- DS는 prod에서 접근 권한이 없음 : visualization / log : Monitoring 중요 ⇒ 문제 확인 ⇒ 대응
- Model Training
- Training & Tuning ⇒ MLflow tracking server
- Evaluation
- Register & Request Transition ⇒ MLflow Model Registry
- model registry가 3-stage로 구성 (None / Staging / Production)
- CD (Continuous Deployment)
- 배포 규정 준수 check
- Compare Stg. vs Prod (Model 성능 비교)
- Set stage ⇒ Prod
- Online Serving
- Make Endpoint using MLflow Model Registry
- Inference
- Stage=Prod Model로 배포
- Monitoring
- Data Ingestion
- Check Acc. and Data Drift (shift)
- Publish Metrics
- Trigger Model Training : Lower metrics ⇒ Trigger
- Retaining
- 자동 유지 시스템
- Schedule : modeling
- Trigger : after alert, retraining
- 자동 유지 시스템

MLOps, ML Engineer. 데이터에서 시스템으로, 시스템에서 가치로.