What is Spring Framework?
역사
스프링의 역사는 자바 EE 시절로 돌아간다. 사실 자바의 암흑기가 아닐까?
최대한 자바 EE를 사용하지 않고, 자바 EE를 사용할 때의 불편함을 해소하고자 만들어졌다.
자바 EE는 최대한 자유롭게 사용 할 목적으로 만들어졌지만 오히려 사용하기 어렵고 또 , 종속적인 개발을 하게 만들었다.
자바의 특징이 무엇인가? 자바는 종속을 최대한 줄이고자 만들어졌다. 근데 자바 EE 는 오히려 종속적이게 만들었다.
이때 , 자바의 암흑기가 도래했는데 여기서 나온 것이 Spring 이다. 길고 긴 자바의 암흑기 , 겨울을 거쳐 봄이 왔다는 뜻에서
Spring 이라는 이름이 붙었다.
Spring Framework
스프링 프레임워크는 자바 플랫폼을 위한 오픈소스 애플리케이션 프레임워크이다.
스프링은 다움 장점 4가지를 가지고 있다.
- POJO 기반의 프레임워크이다.
- 의존성 주입(DI)을 지원한다.
- AOP를 지원한다.
- 자바의 특징을 그대로 사용 할 수 있다. (종속성을 최대한 줄이고자 만들어졌다.)
먼저 상세한 특징을 살펴보기전에 왜 한국 기업들의 대다수는 스프링을 메인으로 사용 할 까?
간단하게 스프링은 기업용 언터프라이즈 시스템 이기 때문이다.
이는 대용량 데이터 처리 , 서버의 자원 효율 , 보안 , 안전성, 확장성 등을 충분히 고려한 설계이기 때문에 기업에서 사용하기에 적합하다.
POJO 기반의 프레임워크이다.
POJO 란 Plain Old Java Object 의 약자로 자바의 기본적인 객체를 의미한다.
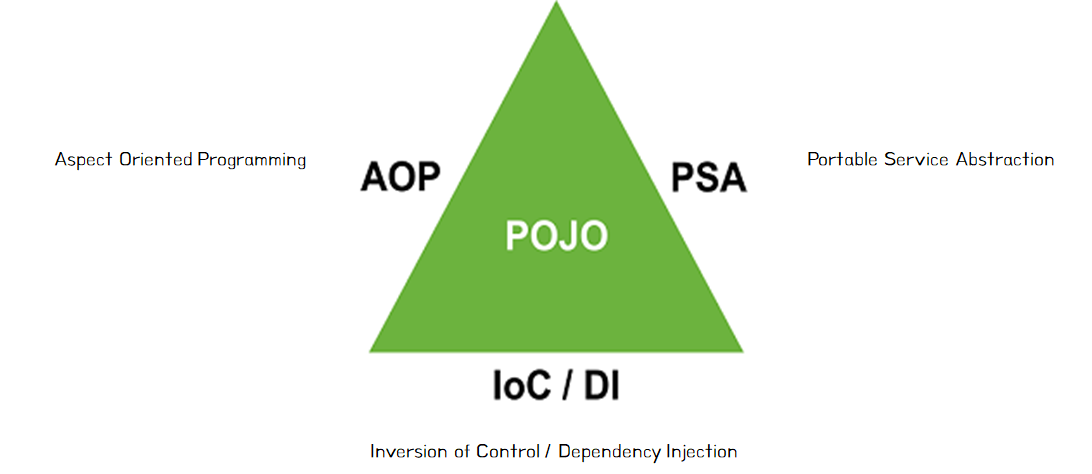
위는 사진은 스프링 삼각형을 이루는 그림이다. 이는 스프링을 이루는 핵심 개념을 한번에 나타내는 모습이다.
POJO를 Ioc/DI , AOP , PSA 라는 3가지 개념을 통해 설명 할 수 있다.
그래서 포조가 몬데!!
자바 외 다른 기술이나 규약에 종속적이지 않다는 것이다.
예를 들어보자
public class User {
private String name;
private int age;
private String email;
private String phone;
private String address;
private String password;
private String salt;
private String role;
private String status;
private String createdDate;
private String updatedDate;
public String getName() {
return name;
}
//...
}위 같은 경우는 자바의 기본 기능만 사용하여 만든 객체이다.
해당 객체는 특정 기술에 종속 되지 않는다. 위와 같은 객체를 POJO 라고 한다.
만약 위 객체가 외부 기술을 사용 하여 상속을 받았다고 해보자.
근데 갑자기 외부 기술이 내부 상속 메소드를 변경하게 되면 어떻게 될까?
위 객체는 외부 기술에 종속 되어 있기 때문에 외부 기술이 변경되면 해당 객체도 변경되어야 한다.
그러면 POJO는 왜 필요할까?
외부 기술에 종속되지 않는 객체를 만들어야 하는 이유는 다음과 같다.
- 외부 기술에 종속되지 않는 객체는 외부 기술이 변경되어도 해당 객체는 변경되지 않는다.
- 외부 기술에 종속되지 않는 객체는 외부 기술에 종속되지 않기 때문에 테스트가 쉽다.
- 외부 기술에 종속되지 않는 객체는 외부 기술에 종속되지 않기 때문에 재사용이 쉽다.
- 외부 기술에 종속되지 않는 객체는 외부 기술에 종속되지 않기 때문에 유지보수가 쉽다.
- 외부 기술에 종속되지 않는 객체는 외부 기술에 종속되지 않기 때문에 확장이 쉽다.
- 외부 기술에 종속되지 않는 객체는 외부 기술에 종속되지 않기 때문에 이식성이 좋다.
- 외부 기술에 종속되지 않는 객체는 외부 기술에 종속되지 않기 때문에 독립적이다.
IOC
IoC 는 Inversion of Control 의 약자로 제어의 역전이라고 한다.
제어의 역전이란 프로그램의 제어 흐름 구조가 뒤바뀌는 것을 의미한다.
간단하게 설명 하자면 , 프로그래머가 프로그램을 제어하는 것이 아니라 프로그램이 프로그래머를 제어한다.
즉, 프로그램이 프로그래머를 제어한다는 것은 프로그램이 프로그래머가 만든 객체를 생성하고 사용하는 것을 의미한다.
알고리즘을 풀 때 , 일반적인 프로그램의 경우는 main() 함수에서 객체를 생성하고 사용한다.
그러나 IoC 를 사용하면 프로그램이 객체를 생성하고 사용한다.
스프링에서는 컨테이너 라는 객체가 프로그램이 프로그래머가 만든 객체를 생성하고 사용한다.
그렇다면 스프링에서는 어떻게 객체를 생성하고 사용할까?
DI
DI 는 Dependency Injection 의 약자로 의존성 주입이라고 한다.
의존성 주입이란 객체가 사용하는 의존 객체를 직접 만들어 사용하는 것이 아니라 외부에서 주입 받는 것을 의미한다.
즉, 객체가 사용하는 의존 객체를 직접 만들어 사용하는 것이 아니라 외부에서 주입 받는 것을 의미한다.
스프링에서는 컨테이너 라는 객체가 프로그램이 프로그래머가 만든 객체를 생성하고 사용한다.
스프링에서는 세 가지 방법으로 의존성 주입을 할 수 있다.
- 생성자를 통한 의존성 주입
- setter 를 통한 의존성 주입
- 필드를 통한 의존성 주입
사실 2,3번은 권장하지 않는다. 앞으로 쓰게 될 거의 모든 경우에서 1번을 사용 할 것이다.
DI 예제
public class Car {
private Tire tire;
public Car(Tire tire) {
this.tire = tire;
}
public void run() {
tire.roll();
}
}
public class Tire {
public void roll() {
System.out.println("Tire roll");
}
}
public class Main {
public static void main(String[] args) {
Tire tire = new Tire();
Car car = new Car(tire);
car.run();
}
}위의 예제에서 Car 객체는 Tire 객체를 사용한다.
즉, Car 객체는 Tire 객체에 의존한다.
Car 객체가 Tire 객체를 사용하기 위해서는 Car 객체가 Tire 객체를 생성해야 한다.
하지만 Car 객체가 Tire 객체를 생성하는 것이 아니라 외부에서 Tire 객체를 주입 받는다.
즉, Car 객체는 Tire 객체에 의존하지만 Tire 객체를 직접 생성하지 않는다.
이렇게 Car 객체가 Tire 객체를 사용하기 위해 외부에서 Tire 객체를 주입 받는 것을 의존성 주입이라고 한다.
좀 더 , 나아가서 사실 의존성 주입을 받을 때 매개 변수를 직접적인 타입으로 받는 것이 아니라 인터페이스 타입으로 받는 것이 좋다.
public class Car {
private Tire tire;
public Car(Tire tire) {
this.tire = tire;
}
public void run() {
tire.roll();
}
}
public interface Tire {
public void roll();
}
public class KoreaTire implements Tire {
public void roll() {
System.out.println("KoreaTire roll");
}
}
public class Main {
public static void main(String[] args) {
Tire tire = new KoreaTire();
Car car = new Car(tire);
car.run();
}
}위의 예제에서 Car 객체는 Tire 인터페이스를 사용한다.
즉, Car 객체는 Tire 인터페이스에 의존한다.
앞 선 1번 예제에서 만약 타이어를 교체 해야 한다면 클래스를 수정해야 했고 받는 매개 변수를 수정 했기 때문에 Car 클래스를 수정해야 했다.
이는 자바의 다형성을 이용하지 않은 것이며 단일 책임 원칙을 위반한 것이다. (수정이나 확장 할 때 마다 자기만 바뀌어야함 그러나 Car 클래스는 타이어를 교체 할 때 마다 수정되어야 한다.)
의존성 주입을 할 때는 인터페이스를 사용하면 된다. 동작이 안되고 오류가 뜨는 것은 아니지만 인터페이스를 사용하지 않고 클래스를 사용하면 Car 클래스는 KoreaTire 클래스에 의존하게 된다.
AOP
AOP는 Aspect Oriented Programming의 약자로 관점 지향 프로그래밍이라고 한다.
스프링에서 어떤 것을 관심을 가지고 프로그래밍을 하는지 알아보자.
객체에서는 핵심 관심사항과 공통 관심사항으로 나눌 수 있다.
예를 들어서 핵심 관심사항은 비즈니스 로직이고 공통 관심사항은 로그이다.
공통 관심사항
보안 , 로그 , 트랜잭션 , 예외처리 , 성능 측정 등이 있다.
위는 거의 모든 프로그램에서 공통적으로 사용되는 것들이다. 따라서 공통 관심 사항이기 때문에
핵심 관심사항과 분리해서 관리해야 한다.
핵심 관심사항
비즈니스 로직이다.
간단하다. 커피를 구매하는 것 , 회원가입 , 게시글 작성 등이 있다.
AOP를 사용하는 이유
위에서 공통 관심사항과 핵심 관심사항을 분리해서 관리해야 한다고 했다.
그 이유는 유지보수를 위해서이다.
예를 들어서 데이터베이스에 저장할 객체를 만들었다고 가정하자.
첫 번째 예에서는 데이터베이스에 저장하는 로직을 핵심 관심사항에 넣었다.
두 번째 예에서는 데이터베이스에 저장하는 로직을 공통 관심사항에 넣었다.
// 첫 번째 예
public class Member {
private String name;
private String email;
private String password;
private String address;
private String phone;
private String birth;
}
public class MemberDao {
private Connection conn;
private void save(Member member) {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "1234");
// 데이터베이스에 저장하는 로직
}
}
// 두 번째 예
public class MemberDao {
private Connection conn;
private void save(Member member) {
// 데이터베이스에 저장하는 로직
}
}
public class ConnectionManager {
private Connection conn;
public Connection getConnection() {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "1234");
return conn;
}
}첫 번째 예시는 데이터베이스 관련 로직을 핵심 관심사항에 넣었다.
두 번째 예시는 데이터베이스 관련 로직을 공통 관심사항에 넣었다. (ConnectionManager)
두 가지 차이점을 보자.
- 첫 번째 예시에서는 데이터베이스 변경사항이 발생하면 MemberDao 클래스를 수정해야 한다. 그런데 데이터베이스 DAO 가 여러 개 있을 경우 모든 DAO 클래스를 수정해야 한다.
- 두 번째 예시에서는 데이터베이스 변경사항이 발생하면 ConnectionManager 클래스를 수정해야 한다. 관련 DAO 클래스는 수정할 필요가 없다.
두 번째 예시가 더 유지보수하기 좋다.
PSA
PSA 는 Portable Service Abstraction 의 약자이다.
PSA 는 서비스 추상화를 의미한다.
추상화란 구체적인 것을 일반화하는 것을 의미한다. 본질적인 것을 뽑아내는 것이다.
예를 들어서 사람이라는 추상화는 남자, 여자, 아이 등으로 구체화된다.
또 피카소의 그림이든 , 빈센트 반 고흐의 그림이든 그림이라는 추상화로 구체화된다.
그렇다면 PSA를 적용해보자.
public class MemberDao {
private Connection conn;
private void save(Member member) {
// 데이터베이스에 저장하는 로직
}
}
public class ConnectionManager {
private Connection conn;
public Connection getConnection() {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "1234");
return conn;
}
}위 코드에서 데이터베이스에 저장하는 로직을 PSA로 추상화해보자.
public class MemberDao {
private Connection conn;
private void save(Member member) {
// 데이터베이스에 저장하는 로직
}
}
public interface ConnectionManager {
public Connection getConnection();
}
public class MysqlConnectionManager implements ConnectionManager {
private Connection conn;
public Connection getConnection() {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "1234");
return conn;
}
}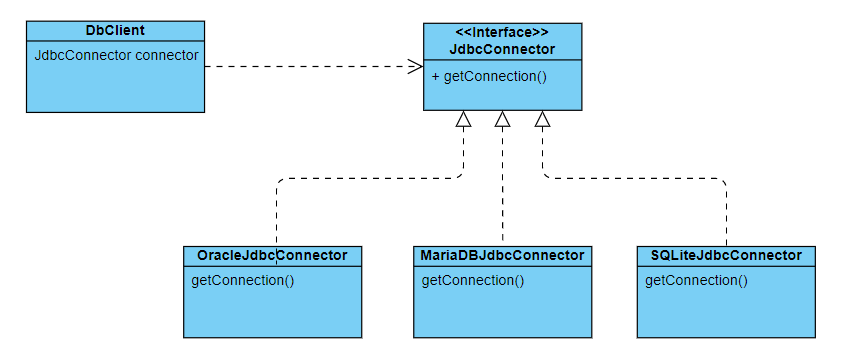
위와 같이 데이터베이스에 저장하는 로직을 PSA로 추상화했다.
자바 관련 프레임워크던 라이브러리던 , 자바를 깊게 배우던 나오는 건 결국에 인터페이스를 잘 활용하는 것이다.
위에서는 데이터베이스 연결 로직을 인터페이스로 추상화했다.
그런데 이렇게 추상화를 하면 어떤 장점이 있을까?
- 데이터베이스 변경사항이 발생하면 ConnectionManager 인터페이스를 수정하면 된다. MemberDao 클래스는 수정할 필요가 없다.
- 데이터베이스 변경사항이 발생하면 MysqlConnectionManager 클래스를 수정하면 된다. MemberDao 클래스는 수정할 필요가 없다.
- 데이터베이스 변경사항이 발생하면 MysqlConnectionManager 클래스를 수정하면 된다. ConnectionManager 인터페이스는 수정할 필요가 없다.
- 데이터베이스를 변경 해야 할 경우에는 ConnectionManager 인터페이스를 구현한 클래스를 만들고 나서 DI 를 통해 주입해주면 된다.
이처럼 변경 사항을 수정 하는 게 쉬워진다. 사실 수정 보다 확장에 열려 있다고 보면 된다.
데이터베이스 변경 시 변경 한 로직은 DI 하는 부분 뿐이고 관련 구현체를 만들었을 뿐이다.
물론 DB 가 바뀌면서 sql 문이 바뀌는 경우도 있겠지만, 이런 경우는 DAO 에서 처리해주면 되기도 하며
ORM 을 사용하면 이런 경우도 해결 할 수 있다.
