SQL - 복습 4
네번째 복습!
오늘은 초급 단계 복습을 끝내고
내일부터 중급 수준 학습에 들어간다
SELECT deptno , SUM(sal) FROM emp GROUP BY deptno ORDER BY sum(sal) DESC
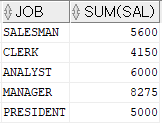
SUM : 지정한 컬럼의 합계를 출력하는 함수SELECT job , SUM(sal) FROM emp GROUP BY job HAVING SUM(sal) >= 4000
sum 과 같은 그룹함수를 사용해 조건을 주는 경우에는 WHERE이 아니라 HAVING 절을 사용해야 한다.
SELECT COUNT(empno) , COUNT(comm) , COUNT(*) FROM emp
COUNT : 선택한 컬럼의 값을 세는 함수로, null 값은 세지 않는다.

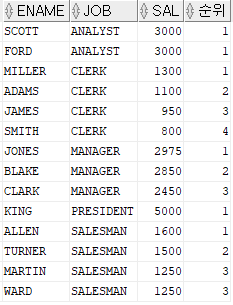
SELECT ename , job , sal , RANK() OVER (PARTITION BY job ORDER BY sal DESC) 순위 FROM emp
RANK() : 순위를 툴력하는 데이터 분석 함수. RANK() 뒤에 OVER 다음에 나오는 괄호 안에 출력하고 싶은 데이터를 정렬하는 SQL 문장을 넣으면 그 컬럼 값에 대한 데이터의 순위가 출력된다. 하나의 순위에 중복이 있으면, 다음 순위는 중복을 건너 뛴 숫자가 부여된다.
PARTITION BY : 결과값이 출력될 때, 그룹끼리 묶어서 출력할 수 있게 해준다. 위 예시의 경우, 직업별로 묶여서 출력되었다.
DENSE_RANK() : 하나의 순위에 중복이 있어도, 다음 순위는 바로 다음 숫자로 부여되는 함수.SELECT DENSE_RANK(2975) WITHIN GROUP (ORDER BY sal DESC) 순위 FROM emp
WITHIN GROUP : 어느 그룹 이내에서 해당 값의 순위가 어떻게 되는지 보고 싶을 때 사용.
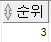
SELECT ename , job , sal , NTILE(4) OVER (ORDER BY sal DESC nulls LAST) 등급 FROM emp WHERE job IN ('ANALYST', 'MANAGER', 'CLERK')
NTILE : 정해준 숫자에 따라 등급을 부여하는 함수
NULL LAST : NULL값은 맨 아래 출력하고자 할 때. ORDER BY 절에서 사용된다.
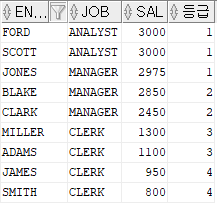
SELECT deptno , LISTAGG(ename, ', ') WITHIN GROUP (ORDER BY ename) as EMPLOYEE FROM emp GROUP BY deptno
LISTAGG : 데이터를 가로로 출력하는 함수. WITHIN GROUP은 별도로 설정하지 않아도 된다. 가로로 출력시 정렬 순서를 지정하고 싶다면 WITHIN GROUP과 ORDER BY를 사용해주면 된다 (예시와 같이)
- LISTAGG 함수를 이용할 때는 GROUP BY 절을 필수로 이용해줘야 한다.
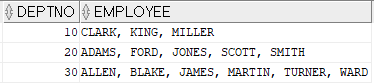
SELECT SUM(DECODE(deptno, 10, sal)) as "10" , SUM(DECODE(deptno, 20, sal)) as "20" , SUM(DECODE(deptno, 30, sal)) as "30" FROM emp
부서별 월급 합계를 구하는 쿼리이다. DECODE를 이용해 부서별 조건값을 주고, SUM값을 이용해 합계를 구했다.SELECT deptno , NVL(SUM(DECODE(job, 'ANAYLST', sal)), 0) as "ANALYST" , NVL(SUM(DECODE(job, 'CLERK', sal)), 0) as "CLERK" , NVL(SUM(DECODE(job, 'MANAGER', sal)), 0) as "MANAGER" , NVL(SUM(DECODE(job, 'SALESMAN', sal)), 0) as "SALESMAN" FROM emp GROUP BY deptno
부서번호 별로 각각 직업의 토탈월급의 분포를 보기 위함이다.
deptno를 추가했으므로, GROUP BY 절을 이용해준다.
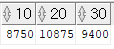
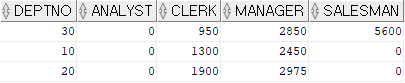
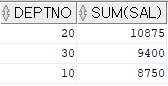
SELECT * FROM (SELECT deptno , sal FROM emp) PIVOT(SUM(sal) FOR deptno IN (10, 20, 30))
FROM 절에서 추출한 부서번호와 월급을 가지고 부서별 토탈 월급을 출력한다. 부서 번호는 10, 20, 30번에 대한 것을 출력한다.
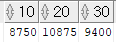
SELECT empno , ename , sal , SUM(sal) OVER (ORDER BY empno ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 누적치 FROM emp WHERE job IN ('ANALYST', 'MANAGER')
OVER : OVER 뒤에는 값을 누적할 윈도우를 지정할 수 있다.
ROWS
UNBOUNDED PRECEDING : 맨 첫번째 행
UNBOUNDED FOLLOWING : 맨 마지막 행
CURRENT ROW : 현재 행
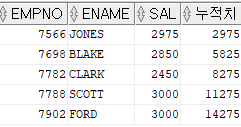
SELECT empno , ename , sal , RATIO_TO_REPORT(sal) OVER () AS 비율 FROM emp WHERE deptno = 20
위 쿼리의 RATIO ~~ 부분은
SAL/SUM(sal) OVER () as "비교 비율" 다음 쿼리로 대체해도 동일한 값이 출력된다.
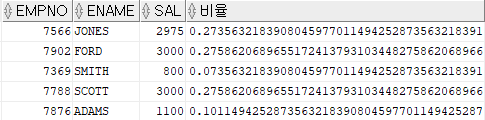
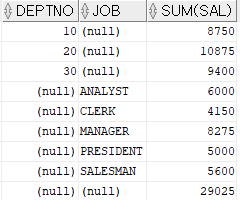
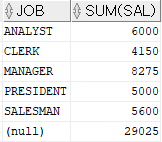
SELECT job , SUM(sal) FROM emp GROUP BY ROLLUP(job)
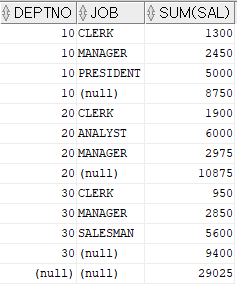
ROLLUP : 행의 마지막에 토탈 값을 출력하는 함수SELECT deptno , job , SUM(sal) FROM emp GROUP BY ROLLUP(deptno, job)
ROLLUP 함수에 여러개의 컬럼을 사용할 수 있다.
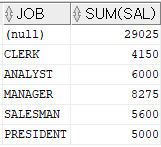
위 예시에서는 부서별 - 직업별 합계값, 부서별 합계값, 그리고 마지막 행에 전체의 합계가 나오고 있다.SELECT job , SUM(sal) FROM emp GROUP BY CUBE(job)
CUBE : ROLLUP 함수와 반대로, 합계값을 맨 첫행에 추출하는 함수이다.SELECT deptno , job , SUM(sal) FROM emp GROUP BY CUBE(deptno, job)
CUBE에도 여러 개의 컬럼을 입력할 수 있다. 다만, ROLLUP 함수에서는 (A, B) 컬럼을 기입하였을 경우, A&B / A / 전체합계 이런식으로 3개의 합계 값이 출력되었지만
CUBE 함수에서는 A&B / A / B / 전체합계 총 4개의 합계 값이 출력된다.
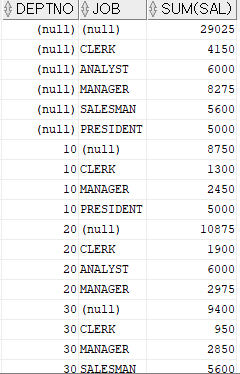
SELECT deptno , job , SUM(sal) FROM emp GROUP BY GROUPING SETS((deptno), (job), ()) ORDER BY deptno, job
GROUPING SETS : 괄호 안에 집계하고 싶은 컬럼명을 기술하면 기술한 대로 결과가 출력된다.