그룹의 특징 잡기
SELECT COUNT(*) AS total_count
, COUNT(DISTINCT user_id) AS user_count
, COUNT(DISTINCT product_id) AS product_count
, SUM(score) AS sum
, AVG(score) AS avg
, MAX(score) AS max
, MIN(score) AS min
FROM review
이미 한번씩 공부했던 쿼리이다
SELECT user_id
, COUNT(*) AS total_count
, COUNT(DISTINCT product_id) AS product_count
, SUM(score) AS sum
, AVG(score) AS avg
, MAX(score) AS max
, MIN(score) AS min
FROM review
GROUP BY user_id
GROUP BY 구문을 사용한 쿼리에서는, GROUP BY 구문에 지정한 컬럼 또는 집약 함수만 SELECT 구문의 컬럼으로 지정할 수 있다. GROUP BY 구문에 지정한 컬럼을 유니크 키로 새로운 테이블을 만들기 때문이다.
SELECT user_id
, product_id
, score
, AVG(score) OVER() AS avg_score
, AVG(score) OVER(PARTITION BY user_id) AS user_avg_score
, score - AVG(score) OVER(PARTITION BY user_id) AS user_avg_score_diff
FROM review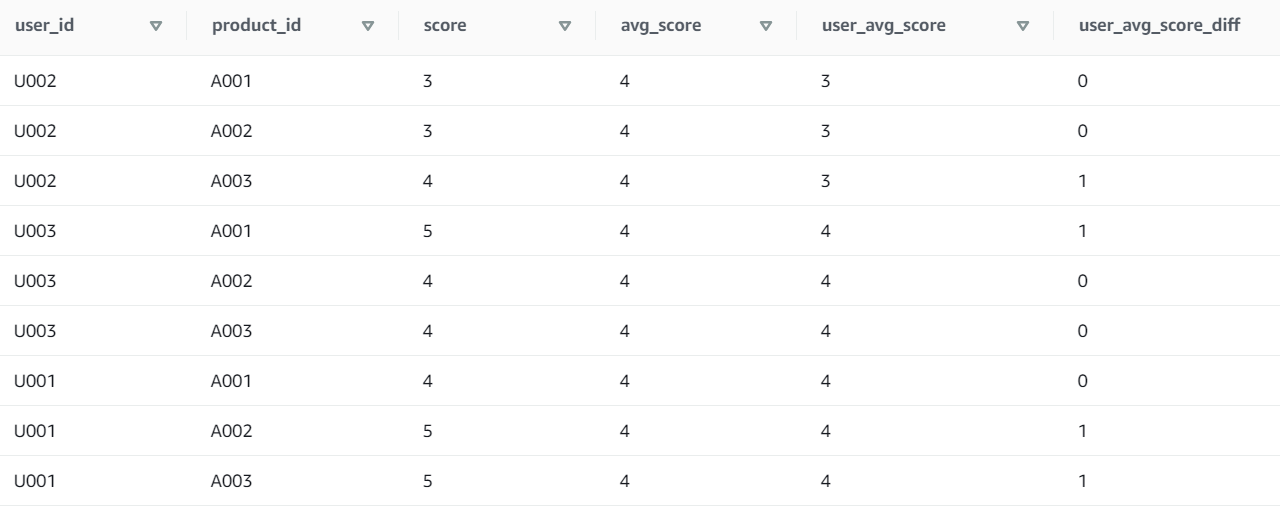
OVER 구문에 매개 변수를 지정하지 않으면 테이블 전체에 집약 함수를 적용한 값이 리턴된다. 매개변수에 PARTITION BY <컬럼이름>을 지정하면 해당 컬럼 값을 기반으로 그룹화하고 집약 함수를 적용한다.
그룹 내부의 순서
SELECT product_id
, score
, ROW_NUMBER() OVER(ORDER BY score DESC) AS row
, RANK() OVER(ORDER BY score DESC) AS rank
, DENSE_RANK() OVER(ORDER BY score DESC) AS dense_rank
FROM popular_products
ORDER BY row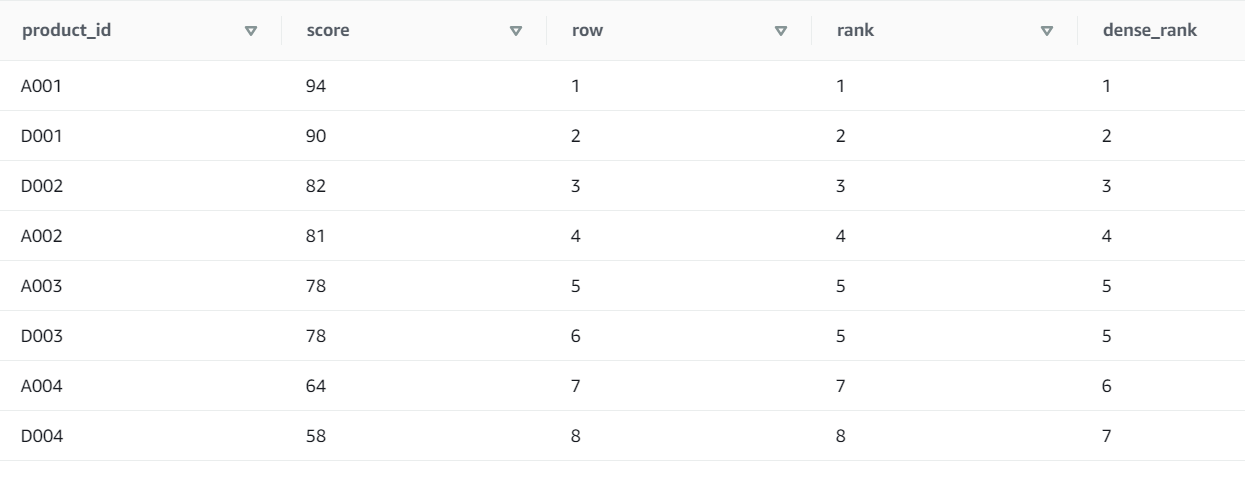

Lifetime Value Creator