📌 학습 목표
- 데이터 확인
- Cost function 이해
- Gradient Descent 이론
- Gradient Descent 구현
데이터 정의
예시 데이터로 공부한 시간(x)에 대한 점수(y)를 사용한다.
간단하게 input = output으로 정의한다.
이를 torch.tensor로 아래와 같이 표현한다.
# Data
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])그러면 가장 좋은 모델(Hypothesis)은 이다.
Cost function 이해
모델의 좋고 나쁨을 평가하기 위해 cost function을 이용한다.
linear regression이므로 MSE를 사용한다.
현재 데이터에서는 W=1 이 가장 좋은 모델이므로 W=1일때 cost function이 0이다.
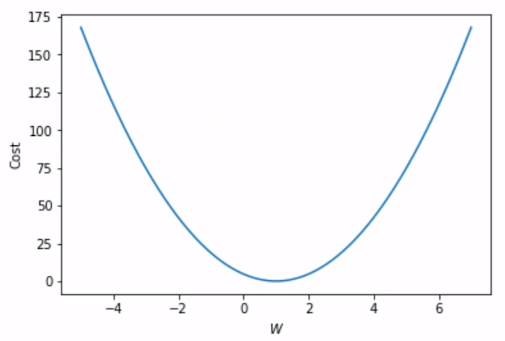
Gradient Descent 이론
Gradient Descent는 cost function의 곡선을 타고 내려가는 것이다.
즉, 미분하여 기울기만큼 이동한다.
이를 수식으로 표현하면 아래와 같다.
Gradient Descent 구현
전체 코드는 아래와 같다.
import torch
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
W = torch.zeros(1)
epochs = 10
lr = 0.1
for epoch in range(1, epochs+1, 1):
hypothesis = x_train*W
cost = torch.mean((hypothesis - y_train) ** 2)
gradient = torch.sum((W*x_train - y_train) * x_train)
print('Epoch {:4d}/{} W: {:.3f}, Cost: {:.6f}'.format(
epoch, epochs, W.item(), cost.item()
))
W -= lr * gradient
'''
Epoch 1/10 W: 0.000, Cost: 4.666667
Epoch 2/10 W: 1.400, Cost: 0.746666
Epoch 3/10 W: 0.840, Cost: 0.119467
Epoch 4/10 W: 1.064, Cost: 0.019115
Epoch 5/10 W: 0.974, Cost: 0.003058
Epoch 6/10 W: 1.010, Cost: 0.000489
Epoch 7/10 W: 0.996, Cost: 0.000078
Epoch 8/10 W: 1.002, Cost: 0.000013
Epoch 9/10 W: 0.999, Cost: 0.000002
Epoch 10/10 W: 1.000, Cost: 0.000000
'''직접 gradient를 구해 갱신해줄 수 있지만, torch 에서는 torch.optim을 지원한다.
import torch
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
W = torch.zeros(1, requires_grad=True)
#optimizer 설정
optimizer = torch.optim.SGD([W], lr=0.15 )
epochs = 10
for epoch in range(1, epochs+1, 1):
hypothesis = x_train*W
cost = torch.mean((hypothesis - y_train) ** 2)
print('Epoch {:4d}/{} W: {:.3f}, Cost: {:.6f}'.format(
epoch, epochs, W.item(), cost.item()
))
# 갱신 과정
optimizer.zero_grad()
cost.backward()
optimizer.step()
'''
Epoch 1/10 W: 0.000, Cost: 4.666667
Epoch 2/10 W: 1.400, Cost: 0.746667
Epoch 3/10 W: 0.840, Cost: 0.119467
Epoch 4/10 W: 1.064, Cost: 0.019115
Epoch 5/10 W: 0.974, Cost: 0.003058
Epoch 6/10 W: 1.010, Cost: 0.000489
Epoch 7/10 W: 0.996, Cost: 0.000078
Epoch 8/10 W: 1.002, Cost: 0.000013
Epoch 9/10 W: 0.999, Cost: 0.000002
Epoch 10/10 W: 1.000, Cost: 0.000000
'''
Hello!