📌 학습 목표
- Gradient Vanishing / Exploding
- Internal Covariate Shift
- Batch Normalization
- Code: mnist_batchnorm
Gradient Vanishing / Exploding
-
Gradient Vanishing
Gradient Vanishing은 지난 ReLU포스트에서 Sigmoid 함수의 문제점에서 설명했었다. graient가 0에 가까워 layer를 지날수록 update 값이 0이 되는 것이다.
-
Gradient Exploding
Gradient Exploding은 기울기 폭발 이라고 하며 gradient가 너무 커서 weight가 큰 값이 되는 것이라고 보면 된다.
이러한 issue를 해결하기 위한 방법은 아래와 같이 있다.
- Change activation function( ex. ReLU )
- Careful initialization( ex. xavier, He )
- Small learning rate
이번에는 이러한 방법들 말고 직접적으로 해결할 수 있는 Batch Normalization을 알아 본다.
Internal Covariate Shift
- Train과 Test dataset의 distribution이 다음과 같다고 해보자.
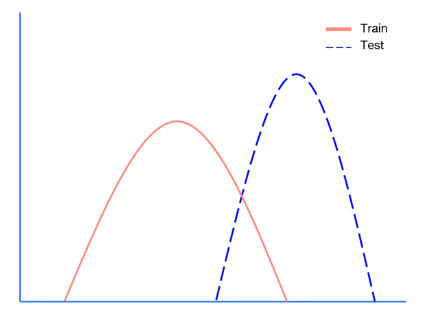
Covariate Shift는 Train set과 Test set의 distribution의 차이가 문제를 발생시킨다는 개념이다.
Internal Covariate Shift는 Layer 사이에 Covatriate Shift 문제가 발생하는 것이다. 그리고, 이를 해결하기 위해 Batch Noramalization을 사용한다.
Batch Normalization
Batch Normalization은 각 Layer를 지날 때 마다 Normalization을 하는 Layer를 추가해 준 것이다.
Batch Norm은 아래 수식과 같은 과정으로 이루어진다.
은 나눌때 0으로 나누지 않도록 하는 작은 값이다.
, 는 학습 가능한 parameter이다.
Batch Norm 역시 train, test 모드로 분리해 사용한다.
train 시 learning mean, learning variance를 구하고 test 시에는 test sample의 mean, variance를 구하지 않고 저장된 learning mean, learning variance를 이용한다.
Code: mnist_batchnorm
Batch Normalization을 이용해 mnist를 학습시켜본다.
class SoftmaxClassifierModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(28*28, 32, bias=True).to(device)
self.linear2 = nn.Linear(32, 32, bias=True).to(device)
self.linear3 = nn.Linear(32, 10, bias=True).to(device)
self.relu = torch.nn.ReLU()
self.bn1 = nn.BatchNorm1d(32)
self.bn2 = nn.BatchNorm1d(32)
torch.nn.init.xavier_uniform_(self.linear1.weight)
torch.nn.init.xavier_uniform_(self.linear2.weight)
torch.nn.init.xavier_uniform_(self.linear3.weight)
self.model = nn.Sequential(self.linear1, self.bn1, self.relu,
self.linear2, self.bn2, self.relu,
self.linear3).to(device)
def forward(self, x):
return self.model(x)여기서 통상적으로 activation function 이전에 batch norm을 적용해준다.
total_batch = len(data_loader)
model.train() # set the model to train mode (dropout=True)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')
'''
Epoch: 0001 cost = 0.468791932
Epoch: 0002 cost = 0.181052282
Epoch: 0003 cost = 0.140861928
Epoch: 0004 cost = 0.118855312
Epoch: 0005 cost = 0.103594661
Epoch: 0006 cost = 0.093640454
Epoch: 0007 cost = 0.083216645
Epoch: 0008 cost = 0.077767603
Epoch: 0009 cost = 0.071476914
Epoch: 0010 cost = 0.065556161
Epoch: 0011 cost = 0.061435528
Epoch: 0012 cost = 0.058798209
Epoch: 0013 cost = 0.056664415
Epoch: 0014 cost = 0.052670859
Epoch: 0015 cost = 0.049189571
Learning finished
'''
with torch.no_grad():
model.eval() # set the model to evaluation mode (dropout=False)
X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
'''
Accuracy: 0.7540000081062317
'''0.75의 정확도이지만, batch norm을 사용하지 않았을 때와 비교해보면 더 높은 성능을 보일 것이다.
