📌 학습 목표
- 딥러닝 학습 단계
- CNN 구조 확인
- MNIST CNN with Code
딥러닝 학습 단계
딥러닝 학습은 아래와 같은 순서로 진행해보자.
- load Library(torch, torchvision, matplotlib .. )
- use GPU and setting random seed
- parameter (learning rate, training epochs, batch size ..)
- load dataset with Loader
- class CNN(torch.nn.Module)
- Loss function, optimizer
- train and check loss
- test model
CNN 구조 확인
아래 그림과 같이 구조를 정했다.
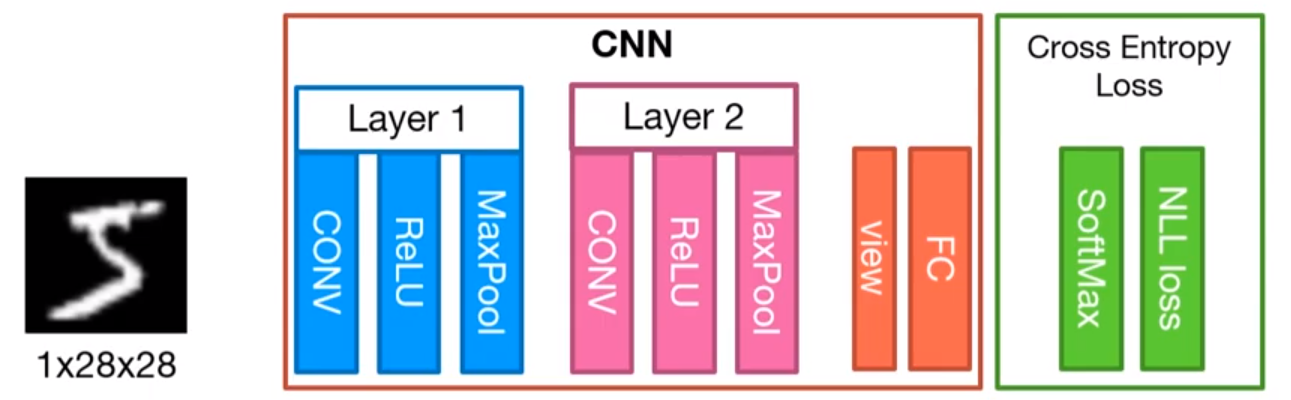
미리 shape를 code를 통해 확인해보자.
import torch
import torch.nn as nn
input = torch.Tensor(1, 1, 28, 28)
conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
max1 = nn.MaxPool2d(kernel_size=2, stride=2)
conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
max2 = nn.MaxPool2d(kernel_size=2, stride=2)
out = conv1(input)
print('out conv1 :', out.size())
out = max1(out)
print('out max1:', out.size())
out = conv2(out)
print('out conv2:', out.size())
out = max2(out)
print('out max2:', out.size())
'''
out conv1 : torch.Size([1, 32, 28, 28])
out max1: torch.Size([1, 32, 14, 14])
out conv2: torch.Size([1, 64, 14, 14])
out max2: torch.Size([1, 64, 7, 7])
'''
out = out.view(out.size(0), -1)
out.size()
# torch.Size([1, 3136])
fc = nn.Linear(3136, 10)
out = fc(out)
out.size()
# torch.Size([1, 10])MNIST CNN with Code
-
load library
필요한 라이브러리를 import 한다.
import torch
import torch.nn as nn
import torch.utils as utils
import torch.optim as optim
import torchvision.datasets as dsets
import torchvision.transforms as transforms-
use GPU and setting random seed
GPU를 사용하고, 재현을 위해 seed값을 고정시켜준다.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)-
parameter
필요한 parameter를 설정해준다.
# parameter
learning_rate = 0.001
training_epochs = 15
batch_size = 100-
load dataset with Loader
MNIST 데이터를 로드한다. 이떄,
utils.data.DataLoader를 이용한다.
# MNIST data
mnist_train = dsets.MNIST(root='DATA_URL',
train=True,
transform=transforms.ToTensor(),
download=False)
mnist_test = dsets.MNIST(root='DATA_URL',
train=False,
transform=transforms.ToTensor(),
download=False)
# dataset loader
data_loader = utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)-
class CNN
CNN 모델을 구성한다.
nn.Module을 상속하여 사용한다.구조는 앞에서 본 이미지와 같이 구성한다.
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc = nn.Linear(7*7*64, 10, bias=True)
torch.nn.init.xavier_uniform_(self.fc.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return outmodel = CNN().to(device)
model
'''
CNN(
(layer1): Sequential(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Linear(in_features=3136, out_features=10, bias=True)
)
'''-
Loss function, optimizer
Loss function은 Cross Entropy를 사용하고, optimizer로는 Adam을 사용한다.
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)-
train and check loss
모델을 훈련시키면서 cost(loss)를 확인한다. 여기서는 잘 줄어들며 학습된다.
# training
total_batch = len(data_loader)
print('Learning Start..')
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch : {:4d}/15 ,Cost = {:.9f}'.format(
epoch+1, avg_cost
))
print('Learning Finish..')
'''
Learning Start..
Epoch : 1/15 ,Cost = 0.220295236
Epoch : 2/15 ,Cost = 0.060901970
Epoch : 3/15 ,Cost = 0.045975104
Epoch : 4/15 ,Cost = 0.036619928
Epoch : 5/15 ,Cost = 0.030008260
Epoch : 6/15 ,Cost = 0.026157571
Epoch : 7/15 ,Cost = 0.020740598
Epoch : 8/15 ,Cost = 0.018732941
Epoch : 9/15 ,Cost = 0.015574027
Epoch : 10/15 ,Cost = 0.013134414
Epoch : 11/15 ,Cost = 0.011464452
Epoch : 12/15 ,Cost = 0.008420592
Epoch : 13/15 ,Cost = 0.008224162
Epoch : 14/15 ,Cost = 0.006989738
Epoch : 15/15 ,Cost = 0.006271583
Learning Finish..
'''-
test model
훈련된 모델의 성능을 test data를 이용하여 평가한다.
# Test model using test data
with torch.no_grad():
X_test = mnist_test.data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.targets.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy', accuracy.item())
'''
Accuracy 0.9855999946594238
'''
Hello!