AWS의 관계형 데이터베이스 서비스인 Amazon Aurora는 뛰어난 성능과 확장성을 제공하여 많은 기업들이 데이터베이스 관리에 이용하고 있습니다. 기본적인 Aurora의 활용법에서 나아가, 더욱 복잡한 요구 사항을 만족시키기 위해 제공되는 고급 기능들이 있습니다. 이 글에서는 Aurora의 고급 개념들에 대해 살펴보겠습니다. 특히 복제본 Auto Scaling, 사용자 지정 엔드포인트, 서버리스, 글로벌 Aurora, 그리고 기계 학습 통합에 대해 중점적으로 설명하겠습니다.
복제본 Auto Scaling
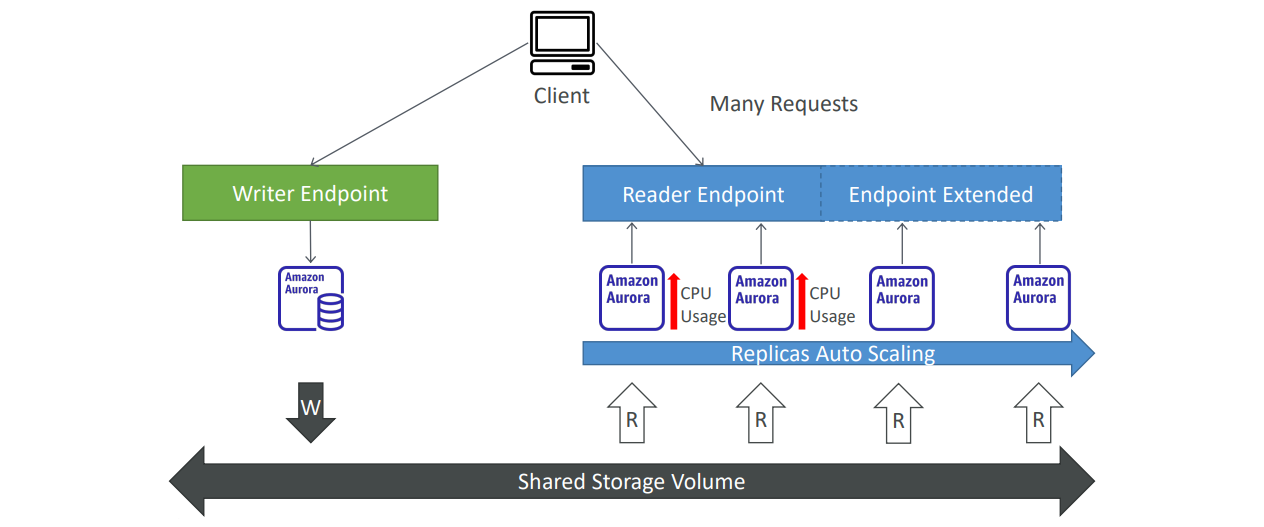
복제본 Auto Scaling은 Aurora 데이터베이스의 읽기 성능을 자동으로 확장하는 중요한 기능입니다. 예를 들어, 하나의 라이터 인스턴스(Writer Endpoint)와 두 개의 리더 인스턴스(Reader Endpoint)를 가지고 있는 상황에서 리더 엔드포인트에 많은 읽기 요청이 들어와 Aurora 데이터베이스의 CPU 사용량이 증가할 경우, 복제본 Auto Scaling을 통해 자동으로 Aurora 복제본을 추가할 수 있습니다.
이 새로운 복제본들은 리더 엔드포인트에 연결되어 읽기 트래픽을 분산받기 시작합니다. 이를 통해 전체적인 CPU 사용량을 낮추고 성능을 유지할 수 있습니다. 복제본 Auto Scaling을 설정하면 수동으로 인스턴스를 추가하거나 관리할 필요 없이, 시스템이 자동으로 적절한 성능을 유지해줍니다.
사용자 지정 엔드포인트
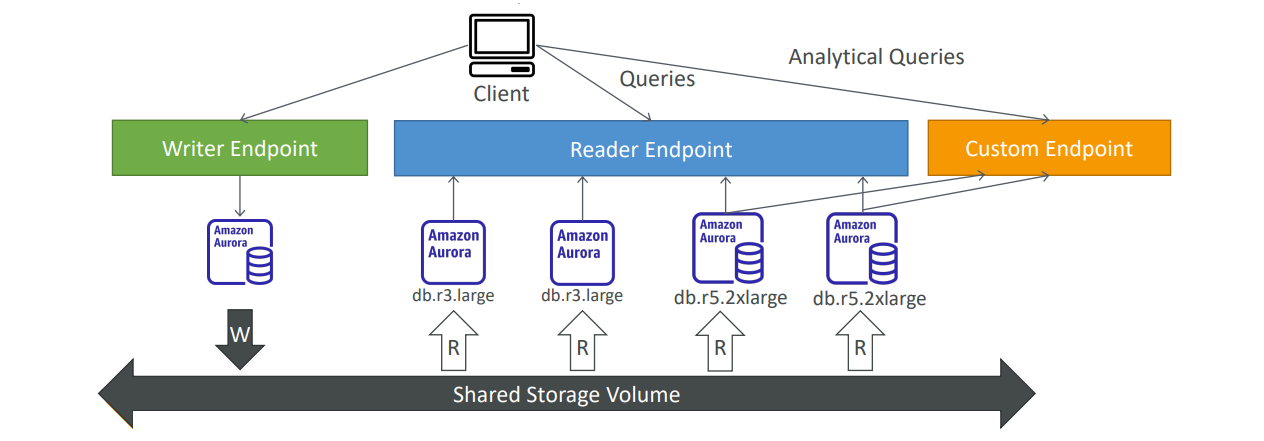
사용자 지정 엔드포인트(Custom Endpoints)는 Aurora 복제본 중 특정 인스턴스를 지정하여 특정 작업에 활용할 수 있는 기능입니다. 예를 들어, db.r3.large와 db.r5.2xlarge와 같은 서로 다른 크기의 복제본이 있을 때, 더 큰 인스턴스에 분석적 쿼리를 전담시키는 것이 효율적일 수 있습니다.
이렇게 특정 인스턴스를 사용자 지정 엔드포인트로 정의하면, 해당 엔드포인트를 통해 그 인스턴스들로만 쿼리가 전달됩니다. 이를 통해 분석 작업이나 다른 중요한 작업을 더 성능 좋은 인스턴스에서 처리하도록 할 수 있습니다. 이 방식은 Aurora의 자원을 더 효율적으로 활용하고, 각 작업에 최적화된 성능을 제공할 수 있게 합니다.
서버리스 (Aurora Serverless)
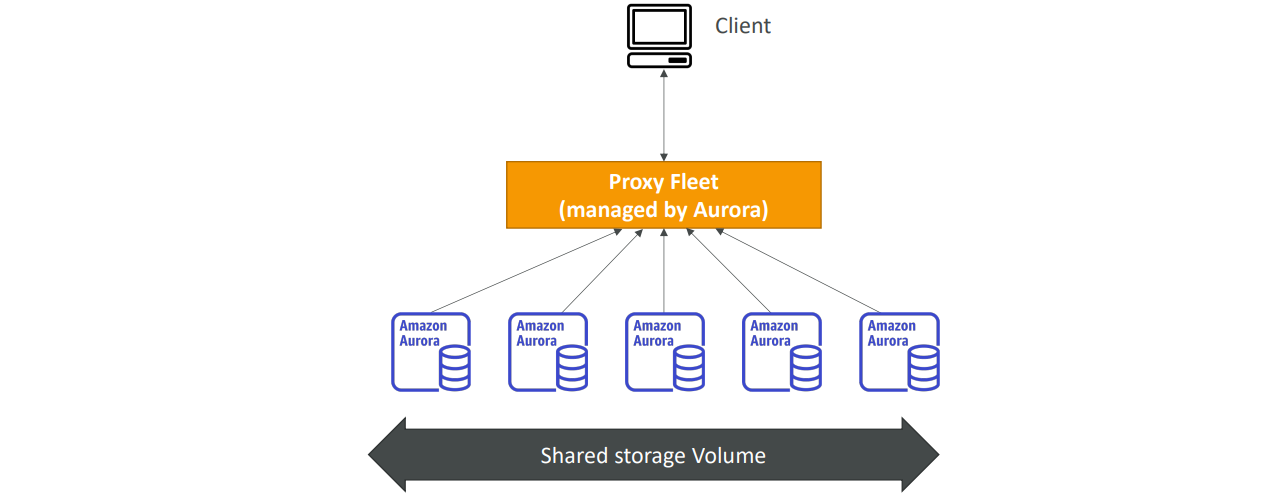
서버리스(Aurora Serverless)는 간헐적이거나 예측 불가능한 워크로드를 처리하는 데 최적화된 기능입니다. 미리 용량을 계획할 필요 없이, 실제 사용량에 따라 데이터베이스 인스턴스가 자동으로 생성되고 확장됩니다. 이를 통해 사용자는 사용한 만큼만 비용을 지불하게 되므로 비용 효율성이 크게 향상됩니다.
서버리스의 작동 방식은 Aurora가 관리하는 프록시 플릿을 통해 클라이언트와 연결됩니다. 백엔드에서는 필요에 따라 Aurora 인스턴스가 자동으로 생성되고, 이 인스턴스들은 서버리스 방식으로 동작하여 워크로드에 맞게 확장됩니다. 이 방식은 특히 가변적인 트래픽이나 짧은 시간 동안 발생하는 대규모 트래픽을 처리할 때 유용합니다.
글로벌 Aurora
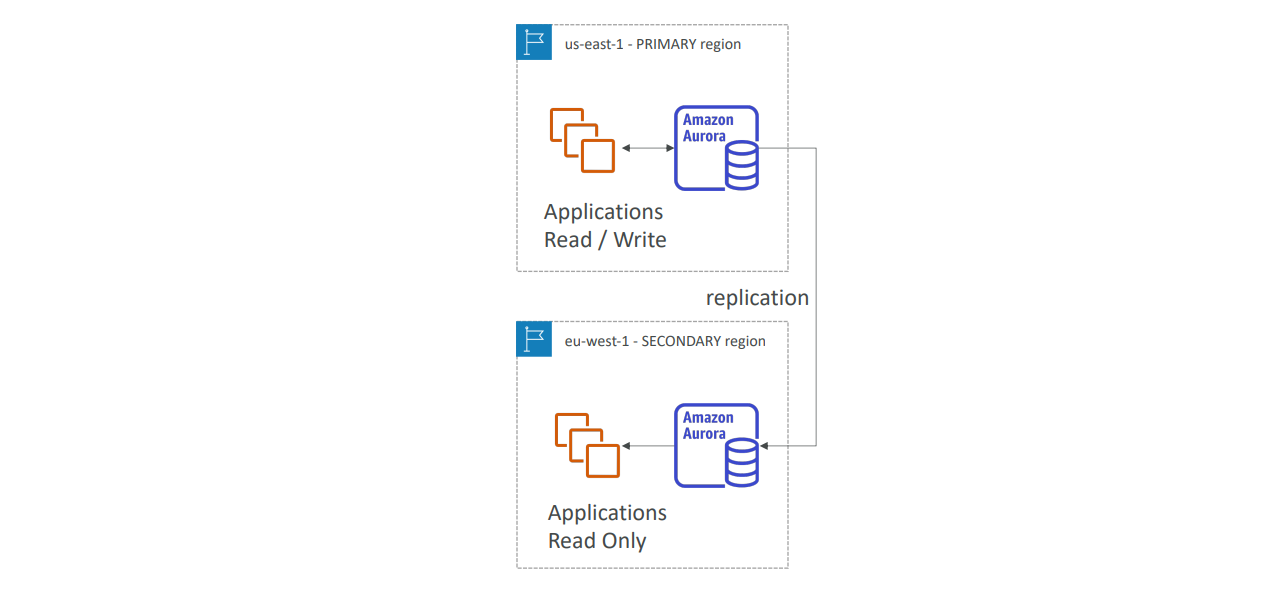
Aurora 글로벌 데이터베이스는 전 세계 여러 리전에 걸쳐 데이터를 동기화하고, 지연 시간을 최소화하여 빠른 응답을 제공하는 기능입니다. 기본 리전(Primary Region)에서 모든 읽기 및 쓰기가 일어나며, 최대 5개의 보조 읽기 전용 리전(Secondary Region)을 설정할 수 있습니다. 이러한 보조 리전은 응답 지연이 1초 이하로 유지되며, 리전당 최대 16개의 읽기 전용 복제본을 가질 수 있습니다
Aurora 글로벌 데이터베이스의 중요한 장점 중 하나는 재해 복구 기능입니다. 만약 한 리전에서 장애가 발생하면, 다른 리전으로 빠르게 전환(failover)하여 서비스 중단을 최소화할 수 있습니다. 이러한 전환 과정은 일반적으로 1분 이내에 완료됩니다.
Aurora 기계 학습 통합
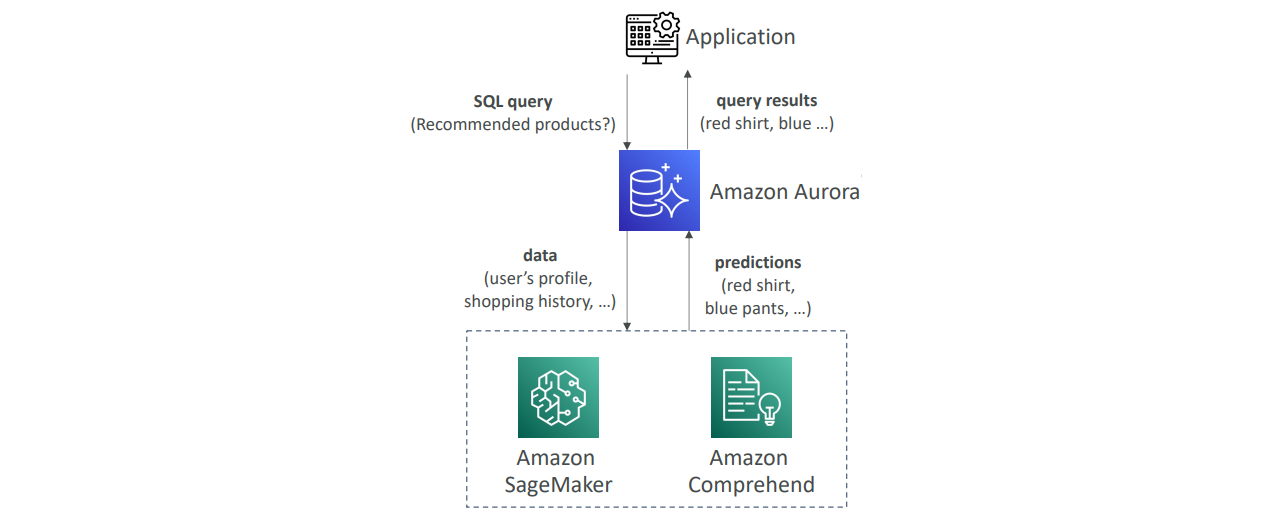
Amazon Aurora는 AWS의 기계 학습 서비스와 통합되어, SQL 인터페이스를 통해 기계 학습 기반의 예측을 응용프로그램에 추가할 수 있습니다. 지원되는 주요 서비스는 Amazon SageMaker와 Amazon Comprehend입니다. SageMaker를 통해 어떤 종류의 기계 학습 모델도 사용할 수 있으며, Comprehend는 감정 분석 등의 작업에 사용됩니다.
이 기능은 Aurora 데이터베이스 내에서 SQL 쿼리만으로 기계 학습 예측을 손쉽게 수행할 수 있게 해줍니다. 예를 들어, '추천 상품은 무엇인가?'와 같은 쿼리를 실행하면, Aurora가 기계 학습 서비스와 통신하여 필요한 데이터를 전송하고 예측 결과를 받아옵니다. 이러한 통합은 기계 학습 경험이 없는 사용자도 쉽게 기계 학습 기능을 응용프로그램에 통합할 수 있도록 해줍니다.
마치며
Amazon Aurora는 기본적인 관계형 데이터베이스 기능을 넘어, 복제본 Auto Scaling, 사용자 지정 엔드포인트, 서버리스, 글로벌 데이터베이스, 기계 학습 통합 등의 고급 기능을 통해 성능과 확장성, 그리고 비용 효율성을 극대화할 수 있습니다. 이러한 기능들은 다양한 비즈니스 요구 사항을 충족시킬 수 있도록 설계되었으며, 클라우드 환경에서 데이터베이스 운영을 최적화하는 데 큰 도움을 줍니다.
