데이터가 폭발적으로 증가하는 시대에 클라우드 스토리지에서 데이터를 효율적으로 관리하고 검색하는 것은 매우 중요한 과제입니다. 특히 Amazon S3(이하 S3)를 사용하면서 대규모 데이터를 다루는 경우, 단순히 데이터를 저장하는 것 이상으로 그 데이터를 효율적으로 검색하고 처리하는 방법이 필요합니다.
과거에는 S3에서 데이터를 검색할 때 전체 데이터를 내려받은 후 애플리케이션에서 필요한 부분만 필터링하는 방식이 일반적이었습니다. 하지만 이 방식은 대규모 데이터에 비효율적이었고, 네트워크 트래픽과 클라이언트 측 리소스 소모가 컸습니다. 이러한 문제를 해결하기 위해 도입된 것이 바로 Amazon S3 Select와 Amazon Glacier Select입니다.
S3 Select와 Glacier Select란
S3 Select는 S3에 저장된 데이터를 직접 검색하면서 특정 행과 열을 SQL과 유사한 쿼리 문법으로 필터링할 수 있는 서비스입니다. 이 서비스는 Amazon S3가 서버 측에서 데이터를 필터링하여, 필요한 데이터만 클라이언트로 전송하게 함으로써 데이터 전송량을 줄이고, 클라이언트 측의 처리 부담을 경감합니다.
Glacier Select는 S3의 저렴한 장기 보관 스토리지인 Glacier에 저장된 데이터에 대해 유사한 기능을 제공합니다. 데이터를 Glacier에서 복원할 때도 필요한 부분만 검색 및 필터링하여 전송함으로써 비용과 시간을 절감할 수 있습니다.
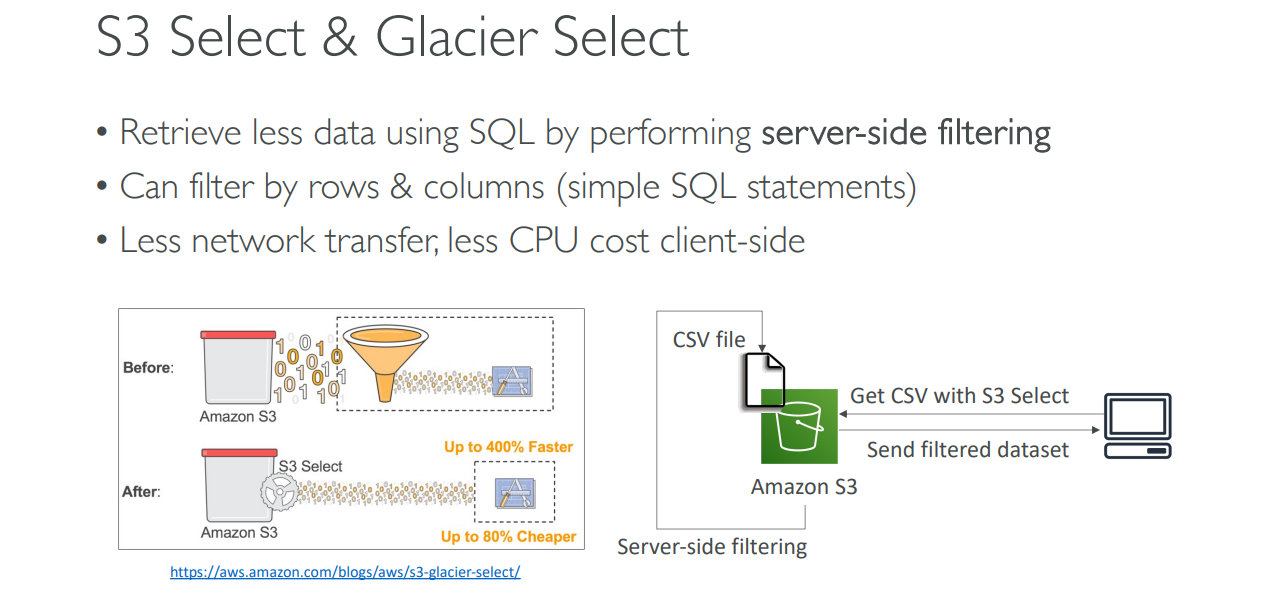
S3 Select의 장점
1. 네트워크 비용 절감:
S3 Select를 사용하면 클라이언트로 전송되는 데이터의 양이 줄어들기 때문에 네트워크 비용이 크게 절감됩니다. 필요 없는 데이터를 전송할 필요가 없기 때문에 전체적인 데이터 전송 비용이 줄어듭니다.
2. 클라이언트 측 리소스 절감:
기존 방식에서는 클라이언트가 전체 데이터를 받아와서 필터링했기 때문에, 클라이언트 측의 CPU 및 메모리 사용량이 컸습니다. 하지만 S3 Select는 서버 측에서 필터링을 수행하기 때문에 클라이언트의 리소스 소모를 줄일 수 있습니다.
3. 성능 향상:
S3 Select를 사용하면 전체 데이터를 다운로드하는 시간과 그 후에 필터링하는 시간을 줄일 수 있어 성능이 크게 향상됩니다. AWS에 따르면 S3 Select를 사용하면 데이터 검색 속도가 최대 400% 빨라지고 비용은 80%까지 절감할 수 있습니다.
사용 사례: CSV 파일 검색
예를 들어 S3에 저장된 큰 CSV 파일에서 특정 열과 행만 필요한 경우를 생각해보겠습니다. 과거 방식대로라면 전체 파일을 다운로드한 후, 그 파일을 분석해서 필요한 데이터를 추출했어야 했습니다. 하지만 S3 Select를 사용하면 Amazon S3가 서버 측에서 직접 이 CSV 파일을 검색하고, SQL 문법을 통해 필터링된 결과만 전송해줍니다.
이 과정에서 전체 데이터 크기는 줄어들기 때문에 네트워크 전송 비용이 감소하고, 처리 속도는 크게 빨라집니다. 이렇게 필터링된 데이터는 원하는 형태로 전달되어 클라이언트 측에서 추가적인 연산 없이 바로 사용할 수 있습니다.
Glacier Select의 활용
Glacier는 저비용의 장기 데이터 보관 서비스로, 주로 자주 접근하지 않는 데이터를 저장하는 데 사용됩니다. 하지만 보관된 데이터를 다시 복구해야 하는 상황에서도 Glacier Select를 통해 필요한 데이터만 검색 및 복구할 수 있습니다. 이는 전체 데이터를 복구하는 데 소요되는 비용과 시간을 절약해줍니다.
마치며
Amazon S3 Select와 Glacier Select는 대규모 데이터를 다루는 환경에서 성능을 최적화하고 비용을 절감하는 데 유용한 도구입니다. 특히 단순한 SQL 문법을 사용하여 서버 측에서 필터링할 수 있기 때문에, 복잡한 데이터 처리 과정이 간소화되고 네트워크 및 클라이언트 리소스의 사용이 최소화됩니다.
