Amazon S3(Simplified Storage Service)는 강력한 데이터 저장 서비스로, 다양한 비즈니스와 개인이 클라우드에 데이터를 안전하게 저장하고 관리할 수 있도록 돕습니다. 하지만 중요한 데이터가 저장된 만큼, 누가 언제 S3 버킷에 접근했는지 추적하는 것은 매우 중요합니다. 이를 위해 Amazon S3는 액세스 로그(Access Logging) 기능을 제공합니다. 이번 글에서는 S3 액세스 로그의 작동 방식과 설정 방법, 그리고 주의 사항에 대해 설명하겠습니다.
S3 액세스 로그란
S3 액세스 로그는 S3 버킷에 대한 모든 요청을 기록할 수 있는 기능입니다. 어떤 계정에서든 S3로 보내는 요청이 승인되었든 거부되었든 상관없이, 모든 요청이 액세스 로그에 기록됩니다. 이 로그는 다른 S3 버킷에 파일 형태로 저장되며, 이 데이터를 활용해 Amazon Athena와 같은 데이터 분석 도구로 분석할 수 있습니다.
이 기능은 보안 감사, 문제 해결, 사용자 활동 모니터링 등 다양한 용도로 활용할 수 있어, S3를 활용하는 많은 기업들에게 매우 유용합니다.
S3 액세스 로그의 작동 원리
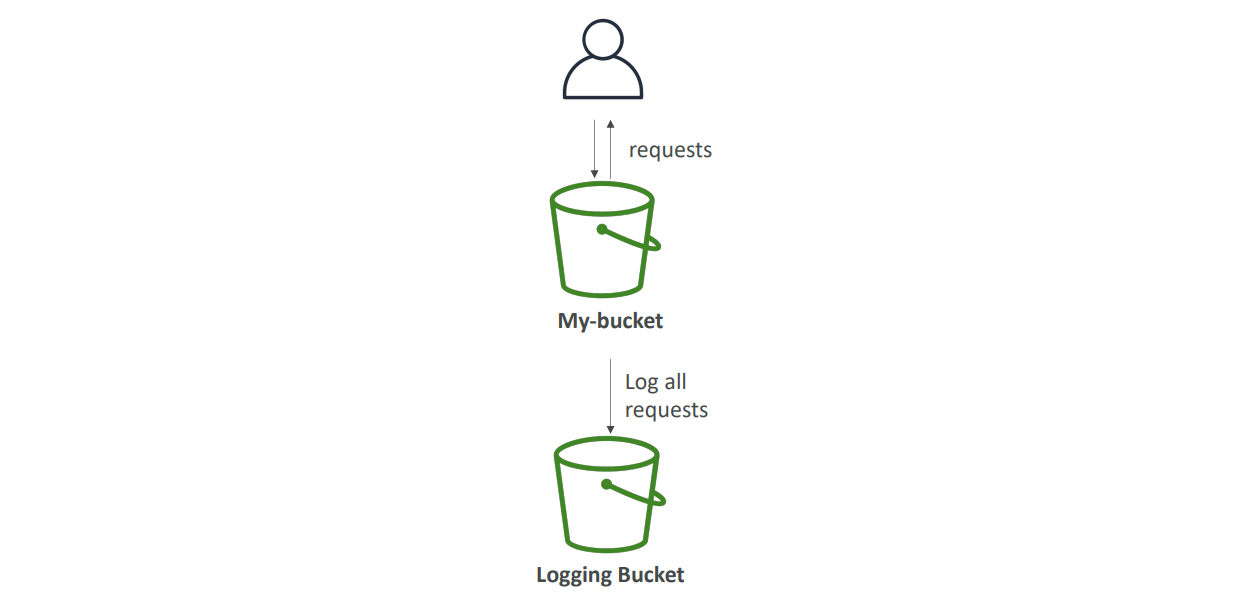
S3 액세스 로그가 작동하는 방식은 비교적 간단합니다. 액세스 로그를 활성화하면, S3는 해당 버킷에 대한 모든 요청(읽기, 쓰기, 삭제 등)을 지정된 다른 S3 버킷(로깅 버킷)에 로그 파일로 기록합니다. 이러한 방식으로, 여러 계정이나 사용자가 해당 S3 버킷에 어떤 요청을 했는지 추적할 수 있습니다.
중요한 점은 로깅 버킷이 S3 버킷과 동일한 리전(Region)에 있어야 한다는 것입니다. 이는 AWS의 리전 내 데이터 전송에 최적화된 성능을 제공하기 위해서입니다.
액세스 로그 형식
로그 파일은 특정 형식으로 저장되며, 로그 파일의 구조는 AWS에서 제공하는 공식 문서를 통해 확인할 수 있습니다. 이 로그에는 요청 시간, 요청자 IP 주소, 요청의 유형 등 중요한 정보들이 포함됩니다. 자세한 형식은 AWS 공식 문서에서 확인할 수 있습니다.
S3 액세스 로그 활성화 방법
- 대상 버킷 설정: 액세스 로그를 저장할 별도의 S3 버킷(로깅 버킷)을 생성합니다.
- 로그 설정: 로깅을 활성화하려는 S3 버킷의 속성에서 액세스 로그 옵션을 활성화합니다. 이때 로그를 저장할 대상으로 위에서 생성한 로깅 버킷을 지정합니다.
- 정책 구성: 로깅 버킷이 올바르게 동작할 수 있도록 해당 버킷에 필요한 권한을 부여합니다.
이제 S3 버킷에 대한 모든 요청이 로깅 버킷에 저장되며, 언제든지 이를 분석할 수 있습니다.
액세스 로그 설정 시 주의 사항
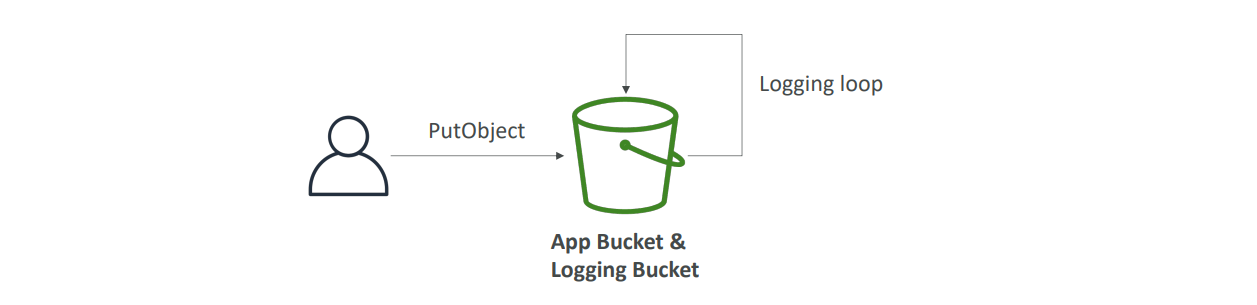
액세스 로그를 설정할 때 반드시 유의해야 할 중요한 사항이 있습니다. 절대로 로깅 버킷을 모니터링하는 S3 버킷과 동일하게 설정하지 말아야 합니다. 만약 동일하게 설정할 경우, "로깅 루프(logging loop)"라는 문제가 발생할 수 있습니다.
로깅 루프 문제
로깅 루프는 말 그대로 로그가 반복적으로 기록되며 끝없이 늘어나는 상황을 말합니다. 예를 들어, 로그를 기록할 로깅 버킷이 원본 S3 버킷과 동일한 경우, 로그 파일을 생성하는 매 요청마다 새로운 로그가 생성됩니다. 이 로그는 또 다른 요청으로 인식되어 또 다른 로그를 생성하게 되고, 이런 과정이 무한 반복되면서 버킷의 크기가 기하급수적으로 증가하게 됩니다.
이런 상황이 발생하면 S3 버킷의 크기가 급격히 증가하고, 스토리지 비용도 폭증하게 됩니다. 따라서 로깅 버킷은 반드시 별도로 설정해야 하며, 로깅 루프를 방지하기 위한 세심한 주의가 필요합니다.
마치며
Amazon S3 액세스 로그는 보안 및 모니터링 목적으로 매우 유용한 도구입니다. 액세스 로그를 통해 S3 버킷에 대한 모든 요청을 기록하고 분석할 수 있으며, 이를 통해 데이터 보안과 관리를 강화할 수 있습니다. 하지만 로깅 버킷 설정 시에는 "로깅 루프" 문제가 발생하지 않도록 주의가 필요합니다.
