오늘은 AWS Route 53의 장애 조치 라우팅 정책(Failover Routing Policy)에 대해 알아보겠습니다. 이는 애플리케이션이 특정 인프라 환경에서 중단 없이 가동되도록 지원하는 핵심 기능입니다. 특히, 장애 발생 시 자동으로 대체 리소스로 전환하여 애플리케이션의 가용성을 높이는 데 중요한 역할을 합니다.
Route 53과 장애 조치(Failover)란
AWS Route 53은 클라우드에서 제공되는 DNS(Domain Name System) 웹 서비스로, 사용자가 요청하는 웹 트래픽을 올바른 엔드포인트로 라우팅합니다. 이때 장애 조치 라우팅 정책을 사용하면, 정상적으로 작동하지 않는 리소스를 자동으로 대체 리소스로 전환하여 트래픽을 라우팅할 수 있습니다. 이렇게 함으로써 서비스 중단을 최소화하고 안정성을 극대화할 수 있습니다.
기본 EC2 인스턴스와 보조 EC2 인스턴스
장애 조치 구성에서 중요한 두 가지 구성 요소는 기본(primary) EC2 인스턴스와 보조(secondary) EC2 인스턴스입니다. 여기서 기본 인스턴스는 정상 상태에서 클라이언트 트래픽을 처리하는 주된 리소스이며, 보조 인스턴스는 재해 복구(Disaster Recovery)를 위해 대기하고 있는 백업 리소스입니다.
상태 확인(Health Check)
이 시스템의 중요한 요소 중 하나는 상태 확인(Health Check)입니다. 상태 확인은 리소스의 상태를 주기적으로 모니터링하여 해당 리소스가 정상적으로 작동하는지 확인하는 프로세스입니다. 기본 인스턴스에 상태 확인을 연결하고, 상태 확인이 실패할 경우 보조 인스턴스로 트래픽을 자동으로 전환하도록 설정할 수 있습니다.
장애 조치 과정(Failover Process)
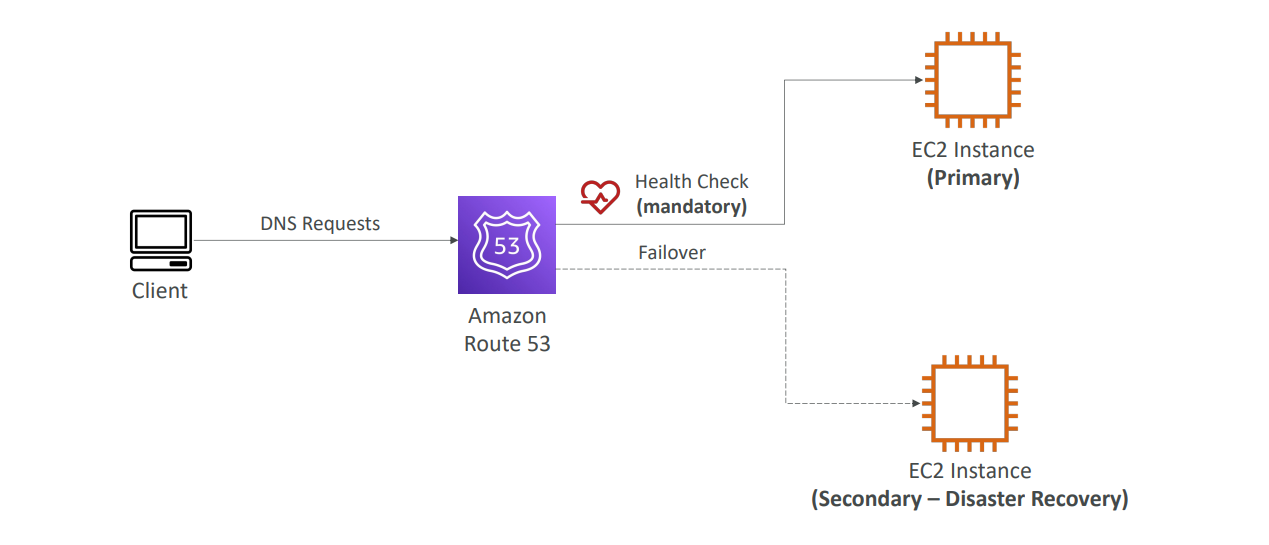
-
정상 시나리오: 기본 EC2 인스턴스가 정상일 때는 Route 53이 상태 확인을 통해 이를 확인하고, 클라이언트의 DNS 요청에 대해 기본 인스턴스의 IP 주소로 응답합니다. 클라이언트는 정상적으로 리소스에 액세스할 수 있습니다.
-
비정상 시나리오: 만약 기본 인스턴스가 비정상 상태가 되면 상태 확인이 실패하고, Route 53은 자동으로 보조 EC2 인스턴스의 레코드를 응답하기 시작합니다. 이때 클라이언트의 DNS 요청은 보조 인스턴스로 전달되며, 서비스는 중단 없이 계속 유지됩니다.
보조 EC2 인스턴스의 상태 확인
보조 인스턴스에도 상태 확인을 설정할 수 있습니다. 이렇게 하면 보조 인스턴스의 상태를 지속적으로 모니터링하여, 필요 시에도 보조 인스턴스가 정상적인 상태로 대기하고 있음을 보장할 수 있습니다. 그러나 기본과 보조 인스턴스 각각에 하나의 상태 확인만 연결해야 합니다.
장애 조치 라우팅 정책의 이점
이러한 장애 조치 라우팅 정책의 가장 큰 이점은 다음과 같습니다:
- 고가용성: 리소스 장애가 발생하더라도 자동으로 대체 리소스로 전환되어 서비스가 중단되지 않습니다.
- 자동화된 대응: 상태 확인과 Route 53의 자동 응답 기능으로 인한 장애 조치가 인프라 운영의 자동화 수준을 높입니다.
- 재해 복구: 재해나 장애 발생 시 빠르게 대응할 수 있어 복구 시간을 단축시킵니다.
마치며
AWS Route 53의 장애 조치 라우팅 정책은 클라우드 인프라에서 가용성과 안정성을 확보하는 데 매우 유용한 도구입니다. 기본 및 보조 EC2 인스턴스와 상태 확인 기능을 결합함으로써 서비스가 중단 없이 운영될 수 있도록 지원하며, 이는 특히 재해 복구 시나리오에서 중요한 역할을 합니다.
이와 같은 구성을 통해 장애가 발생해도 서비스가 유지될 수 있는 안정적인 환경을 구축해 보세요. Route 53을 활용한 자동화된 장애 조치는 여러분의 애플리케이션을 한층 더 신뢰성 있게 만들어 줄 것입니다.
