
프로젝트 2일차 기록을 작성한다 🔥
머신 러닝을 위해 필요한 데이터 수집이 필요하다.
이전에 yt-dlp를 통해 만든 기능을 통해 '자막 수집 서비스'를 만드는 중이다.
관련 코드는 여기서 확인할 수 있다.
데이터 저장
데이터 수집은 곧 데이터 저장을 말한다.
그럼 어떤 데이터를 저장해야 할까? 🤔
필요한 데이터
url, create_time, leet_code_number, thumbnail_url, title, content
핵심적으로 고려했던 부분은 content(추출해온 자막)이었다.
content는 매우 긴 문자열이었고 이를 원활히 저장하기 좋은 DB는 NoSQL이라 생각했다 😉
DynamoDB
NoSQL로 가장 유명한 MongoDB가 있지만 AWS 환경으로 인프라를 구축하고 싶었기에 DynamoDB를 이용했다.
우리가 만든 '자막 수집 서비스'는 EC2에 올렸고 같은 AWS 리전 내 DB를 생성했다.
# db가 생성된 리전을 명시
dynamodb = boto3.resource('dynamodb', region_name='ap-northeast-2')
# 테이블의 이름 명시
table = dynamodb.Table('Subtitle-Ondemand')
# 데이터 insert 예시
table.put_item(
Item={
'video_id': video_id,
'title': title,
'datetime': datetime,
'content': content,
'thumbnail': thumbnail,
'leetcode_number': leetcode_number
}
)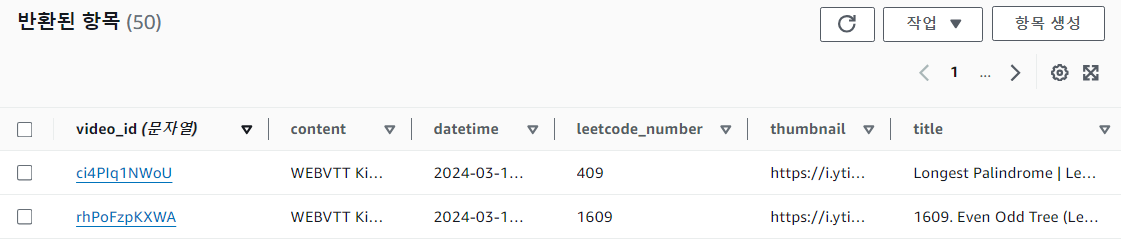
이런식으로 DynamoDB에 저장됨을 확인할 수 있다 👍
중복 처리
우리는 직접 데이터를 수동으로 넣는다.

사람이 하는 일이다 보니 중복된 영상을 저장할 수도 있을 것이다.
이를 대비하여 중복 처리를 확인하는 작업을 주로했다.
def check_video_exists_in_dynamodb(self, video_id):
try:
# video_id를 사용하여 DynamoDB에서 항목 조회
# table은 따로 정의한 dynamodb의 테이블을 의미
response = table.get_item(Key={'video_id': video_id})
return 'Item' in response
except Exception as e:
print(f"Error checking video in DynamoDB: {e}")
return False참고 문헌

날씨의 아이 ☀️ Java Spring ☘️