의사결정나무란?
의사결정나무는 데이터를 분석하는 모형이 '나무'와 비슷하다고 하여 그렇게 불려진다. 질문을 던진 후 대상을 좁혀나가는, 마치 스무고개와 비슷한 개념이라고 생각하면 된다.
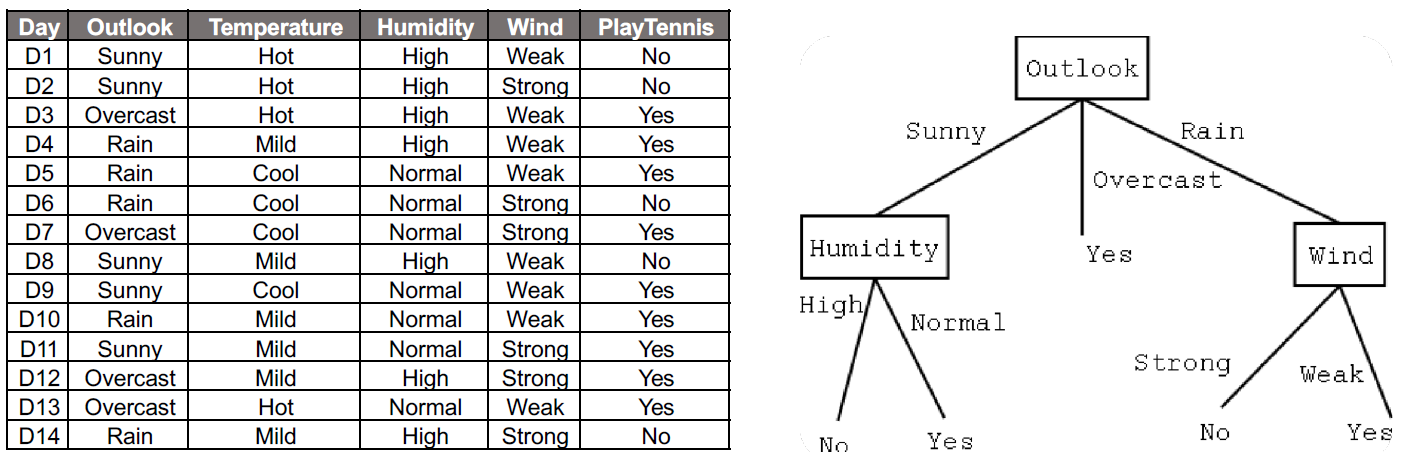
오른쪽 표를 보고 데이터를 정리하자면 오른쪽과 같은 '나무'모양으로 정리가 가능하다.
그렇다면 의사결정 나무의 장단점을 살펴보자!
- 장점 : 해석력이 높다!, 직관적이고 범용성이 뛰어나다!
- 단점 : 변동성이 높다. 즉 샘플에 민감할 수 있다는 의미
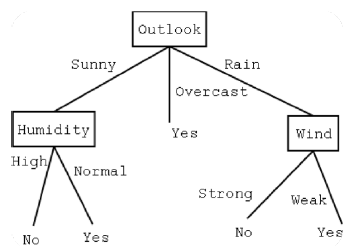
우린 이 그림을 통해서 의사결정나무를 공부하기 위해 알아야 할 몇가지 내용을 짚고 넘어갈 것이다.
- 노드(node)란 ? 네모 칸 안에 있는 요소들! , 분류의 기준이 되는 위치
-parent node : 상위노드
-child node : 하위노드
-root node : 더이상 상위 노드가 없는 가장 상위의 노드
-leaf node : 하위 노드가 없는 가장 아래의 노드
-internal node : leaf node가 아닌 노드
노드에 대한 설명은 상대적인 개넘으로 접근해야한다. 예를들어 위 그림에서 Humidity의 parent node는 Outlook이 되고, Outlook의 child node는 Humidity, Wind가 된다.
프로세스
나무의 알고리즘 프로세스를 간단하게 알아보자.
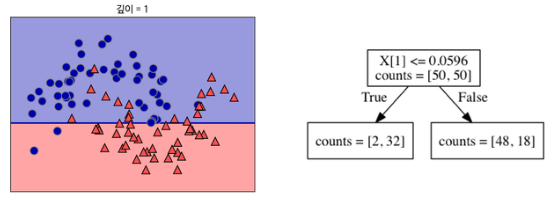
데이터를 가장 잘 구분할 수 있는 기준으로 나눈다.
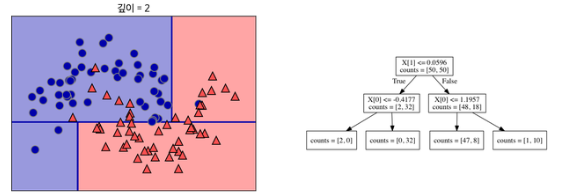
나누니 범주에서 다시 데이터를 잘 구분할수 있는 기준으로 나눈다. 반복하면 좋지만 오버피팅이 될 수 있음을 주의!! (실제로 의사결정나무는 오버피팅이 잘 일어나는 모델이다.)
가지치기(Pruning)
오버피팅을 막기위해 가지치기 기법을 이용한다. 가지치기라는 말과 비슷하게, 더 많은 가지게 생기지 않도록 터미널 노드의 최대 개수를 정하거나, 최소 데이터 수를 제한한다. 그렇다면 어느정도 다른데이터가 섞이는 것도 허용한다는 의미인가? 그렇다. 그 정도를 불순도(Impurity)라고 표현한다.
불순도를 더 깊게애기하자면 엔트로피에 대한 얘기가 나와야하지만 후에 다루기로 하고 의사결정나무는 이정도에서 마치도록 하겠다!
