스케줄링의 개요
정의
- CPU 스케줄링은 멀티태스킹 운영 체제에서 여러 프로세스 중 어떤 프로세스가 CPU를 다음으로 사용할지를 결정하는 과정
- 프로세스간 공평한 CPU 시간 할당을 보장하고 시스템의 효율성과 성능을 최적화하는 데 목적임
주요특징
- 공평성: 모든 프로세스에 공평하게 CPU 시간을 분배
- 효율성: CPU 스케줄링은 시스템의 효율성을 최대화하기 위해 리소스 사용을 최적화
- 응답 시간 감소: 사용자와 시스템 프로세스가 더 빨리 응답받을 수 있도록 도움
- 다양한 알고리즘: 우선순위 기반, 라운드 로빈, 최단 작업 우선(SJF) 등 다양한 스케줄링 알고리즘을 사용
왜쓰는지
- CPU 스케줄링은 시스템의 성능을 최적화하고, 프로세스 간의 공정한 자원 분배를 보장하기 위해 사용함
- 특히 멀티태스킹 환경에서 각각의 프로세스가 시스템 리소스를 효율적으로 사용할 수 있게함
언제 쓰는지
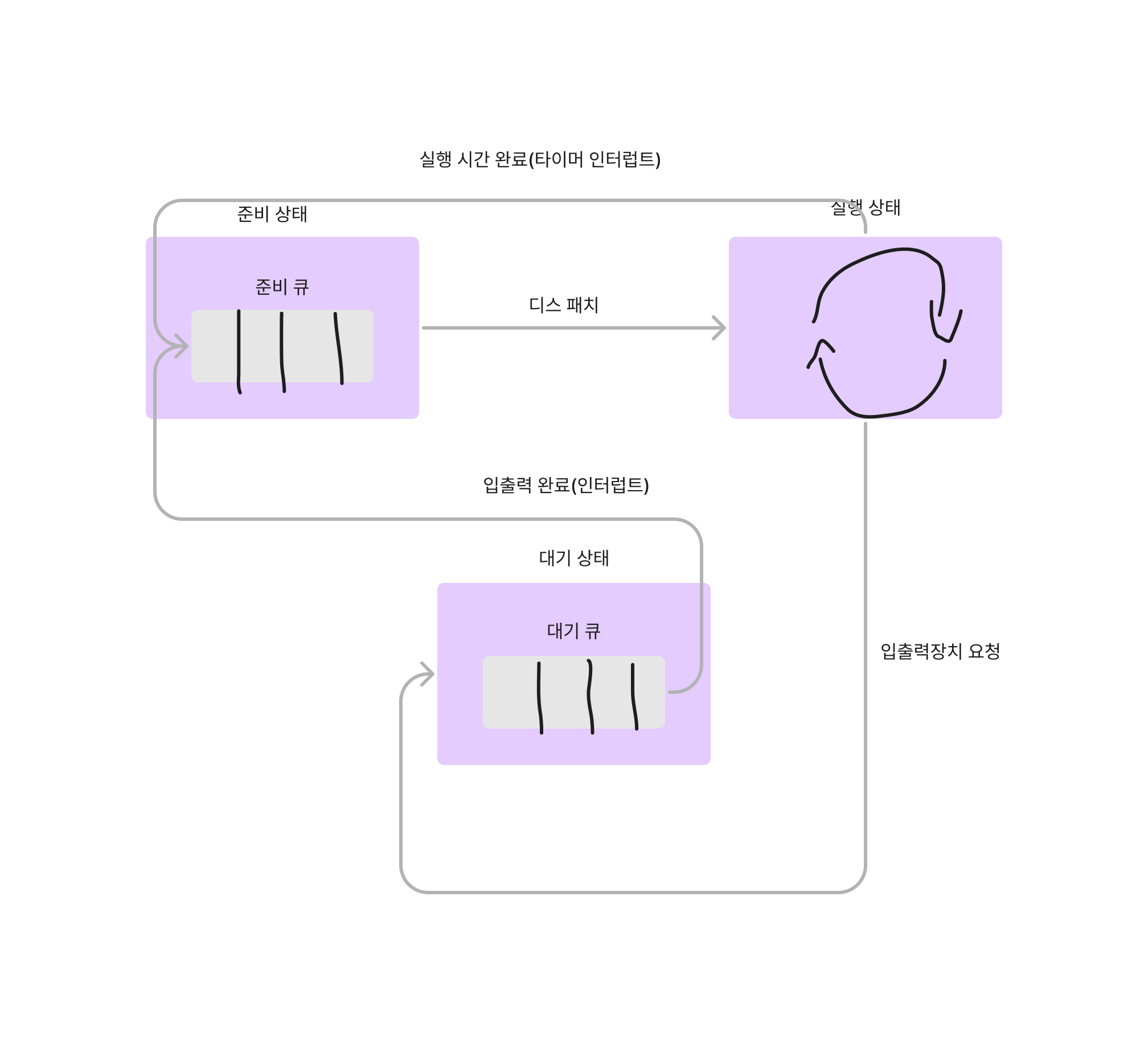
- 프로세스가 생성될 때
- 실행 중인 프로세스가 대기 상태로 전환될 때
- 프로세스가 종료될 때
- I/O 작업이 완료되어 대기 큐로부터 준비 큐로 이동할 때
어떻게 쓰는지
- 운영 체제는 현재 상황과 각 스케줄링 알고리즘의 조건에 따라 프로세스를 선택하고 CPU 시간을 할당
- 예를 들어, 라운드 로빈 스케줄링에서는 각 프로세스에 동일한 시간 할당량(타임 퀀텀)을 주어 순환식으로 CPU 접근 기회를 제공
사용예시
- 웹 서버: 동시에 여러 클라이언트의 요청을 처리해야 하는 경우, CPU 스케줄링을 사용하여 각 요청에 공평하게 CPU 시간을 할당하여 처리할 수 있습니다.
- 운영 시스템: 사용자의 작업과 시스템 프로세스 사이에서 CPU 자원을 효율적으로 관리하고, 시스템 응답 시간을 개선합니다.
이와 같이 CPU 스케줄링은 성능과 효율성을 극대화하고, 멀티태스킹 환경에서의 자원 분배를 공정하게 만드는 데 핵심적인 역할을 합니다.
스케줄링 큐
정의
- 멀티태스킹 운영 체제에서 CPU 스케줄링 과정에서 사용되는 데이터 구조
- 이 큐는 준비 상태의 프로세스들을 관리하며, 운영 체제의 스케줄러가 다음에 CPU를 할당받을 플세스를 선정하는 데 사용됨
주요특징
- 준비 상태의 프로세스 관리
- 다양한 종류
- 다양한 스케줄링 알고리즘 지원
왜쓰는지
- 시스템의 효율성과 반응성을 최적화하기 위해 필요
언제쓰는지
- 멀티태스킹 환경: 운영 체제가 다수의 프로세스를 동시에 관리해야 할 때 사용됩니다.
- 프로세스 상태 변화시: 프로세스가 생성, 대기, 실행, 종료 상태로 전환될 때 스케줄링 큐가 동작합니다.
어떻게 쓰는지
- 운영 체제의 스케줄러는 준비 큐에서 다음에 실행될 프로세스를 선정합니다.
- 사용하는 스케줄링 알고리즘(예: 라운드 로빈, 최단 작업 우선)에 따라, 적절한 프로세스를 CPU에 할당
사용 예시
- 웹 서버: 동시에 여러 클라이언트의 요청을 처리해야 하는 웹 서버에서 병렬 처리를 가능하게 합니다.
- 운영 체제: 사용자의 다양한 애플리케이션 및 시스템 프로세스 간에 CPU 시간을 공정하게 분배합니다.
스케줄링 큐는 시스템의 성능을 극대화하고 리소스를 효율적으로 사용하여 작업을 관리하는 데 핵심적인 역할을 합니다.
선점형과 비선점형 스케줄링
선점형 스케줄링
정의
- 한 프로세스가 CPU를 사용 중일 때, 더 우선순위가 높은 프로세스가 도착하면 현재 실행중인 프로세스를 중지시키고 새로운 프로세스에게 CPU를 할당하는 방식
주요특징
- 반응 시간이 빠름
- 공정성과 효율성 증가
- 우선순위에 따라 작업 전환 가능
왜쓰는지
- 실시간 시스템이나 중요한 적업을 빠르게 처리해야 할 때 유용
- 공정한 자원 분배와 효율적인 프로세스 관리가 필요할 때
언제 쓰는지
- 우선 순위가 서로 다른 작업이나 실시간 작업 처리가 중요한 시스템에서 사용
- 자원 공유가 중요한 멀티태스킹 환경
사용예시
- 실시간 운영 체제에서 공장 자동화 시스템의 작업 관리
- 네트워크 서버에서의 요청 처리
비선점형 스케줄링
정의
- 프로세스가 CPU를 할당받으면, 해당 프로세스가 실행을 완료하거나 입/출력 작업 등으로 대기 상태가 될 때까지 다른 프로세스가 CPU를 강제로 차지할 수 없는 방식
주요특징
- 단순하고 예측 가능
- 프로세스 간의 간섭이 적음
- 오버헤드가 낮음
왜 쓰는지
- 자원의 경쟁이 덜한 시스템에서 효율적
- 시스템의 예측 가능성이 중요한 경우 유용
언제쓰는지
- 배치 처리 시스템이나 사용자의 상호 작용이 적은 시스템에서 사용
- 오버헤드를 최소화하고 싶을 때
어떻게 쓰는지
- 작업이 도착한 순서대로 처리(선입선출)하거나 작업의 크기(단기 작업 우선)를 고려하여 스케줄링
사용 예시
- 배치 작업 시스템에서 대량의 데이터 처리
- 프린팅 작업 관리나 파일 다운로드 스케줄링
선점형 스케줄링과 비선점형 스케줄링
| 구분 | 선점형 스케줄링 | 비선점형 스케줄링 |
|---|---|---|
| 작업 방식 | 실제 상태에 있는 작업을 중단시키고 새로운 작업을 실행할 수 있음 | 실행 상태에 있는 작업이 완료될 때까지 다른 작업이 불가능함 |
| 장점 | 프로세스가 CPU를 할 수 없어 대화형이나 시분할 시스템에 적합 | CPU 스케줄러의 작업량이 적고 문맥 교환의 오버헤드가 적다 |
| 단점 | 문맥 교환의 오버헤드가 많다 | 기다리는 프로세스가 많아 처리율이 떨어진다 |
| 사용 | 시분할 방식 스케줄링에 사용 | 일괄 작업 방식 스케줄링에 사용 |
| 중요도 | 높다 | 낮다 |
CPU 집중 프로세스와 입출력 집중 프로세스
CPU 집중 프로세스
정의
- CPU 집중 프로세스는 대부분의 시간을 CPU 연산에 사용하는 프로세스를 말합니다.
- 이들은 입출력(IO) 작업보다 복잡한 계산이나 데이터 처리에 더 많은 시간을 소요합니다.
주요특징
- 높은 CPU 사용률을 보임
- 입출력(IO) 대기 시간이 상대적으로 짧음
- 계산 또는 처리해야 할 데이터가 많아 실행 시간이 길 수 있음
왜 쓰는지
- 복잡한 계산이나 데이터 처리가 필요한 작업을 효율적으로 처리하기 위해 사용됩니다.
언제 쓰는지
- 데이터 분석, 과학적 연산, 암호화 작업 등 계산량이 많은 작업을 수행할 때 주로 사용됩니다.
어떻게 쓰는지
- 알고리즘 최적화, 멀티쓰레드나 병렬 처리를 통해 CPU 자원을 효율적으로 사용합니다.
사용예시:
- 대규모 수치 계산을 수행하는 과학적 시뮬레이션
- 암호화나 해싱과 같은 보안 알고리즘 실행
- 복잡한 데이터 분석이나 머신러닝 모델 학습
입출력 집중 프로세스
정의
- 입출력 집중 프로세스는 대부분의 시간을 데이터의 입출력 작업에 사용하는 프로세스를 말합니다.
- 이들은 CPU 연산보다 파일 시스템 접근, 네트워크 통신 등의 입출력 작업이 주를 이룹니다.
주요특징
- 높은 입출력(IO) 대기 시간을 보임
- CPU 사용률이 상대적으로 낮음
- 입출력 작업의 최적화가 성능에 큰 영향을 줌
왜 쓰는지
- 데이터의 저장, 검색, 전송과 같은 작업을 처리하기 위해 사용됩니다.
언제 쓰는지
- 파일 처리, 데이터베이스 관리, 네트워크 통신 등의 입출력이 중심이 되는 작업을 수행할 때 주로 사용됩니다.
어떻게 쓰는지
- 입출력 효율을 높이기 위해 비동기 입출력, 캐싱, 버퍼링 등의 기술을 사용합니다.
사용예시
- 웹 서버와 같이 클라이언트의 요청을 받아 처리하고 결과를 반환하는 서비스
- 파일 시스템 관리
- 대용량 데이터베이스 관리 및 쿼리 실행
- 이러한 구분을 통해 각각의 프로세스 유형에 맞게 시스템 리소스를 효율적으로 관리하고 최적화하는 전략을 수립할 수 있습니다.
다중 큐
준비 상태의 다중 큐
정의
- CPU 사용을 위해 대기하는 큐
- 준비 상태의 프로세스들을 관리하기 위해 여러 준비 큐를 사용
- 각 큐는 다른 우선순위 또는 다른 특성(예: CPU 시간 요구 사항, 프로세스 타입 등)을 가지는 프로세스를 위해 지정
작동 원리
- 운영 시스템은 프로세스의 특성 또는 우선순위에 따라 해당 프로세스를 적절한 준비 큐에 할당합니다.
- 각 큐는 별도의 스케줄링 알고리즘(예: 라운드 로빈, 우선순위 스케줄링)을 사용하여 프로세스를 관리할 수 있으며, CPU가 사용 가능해지면 가장 우선순위가 높은 준비 큐에서 프로세스를 선택하여 실행
대기 상태의 다중 큐
정의
- 입출력을 사용하기 위해 대기하는 큐
- 대기 상태의 프로세스들을 관리하기 위해 여러 대기 큐를 사용합니다.
- 이 또한 준비 상태의 다중 큐와 비슷한 방식으로, 프로세스가 대기하는 이유(예: I/O 요청, 특정 이벤트 대기 등)에 따라 다른 대기 큐에 할당
작동 원리
- 프로세스가 특정 자원이나 이벤트를 기다려야 할 때, 운영 시스템은 해당 프로세스를 이유에 따른 적절한 대기 큐에 할당합니다.
- 대기가 완료되고 프로세스가 다시 준비 상태가 되면, 프로세스는 대기 큐에서 제거되고 적절한 준비 큐로 이동
공통점 및 차이점
공통점:
- 두 방식 모두 프로세스를 효율적으로 관리하고, 우선순위 또는 요구 사항에 따라 분리하여 운영하는 것을 목적으로 합니다.
- 다중 큐를 사용하여 다양한 특성을 가진 프로세스들을 분류하고 관리합니다.
차이점:
- 준비 상태의 다중 큐는 CPU를 사용할 준비가 된 프로세스들을 관리하는 반면, 대기 상태의 다중 큐는 특정 자원 또는 이벤트를 기다리는 프로세스들을 관리합니다.
- 준비 상태의 큐는 프로세스가 실행을 위해 선택될 수 있는 반면, 대기 큐는 프로세스가 특정 조건이 만족되기를 기다리는 곳입니다.
- 이러한 분리는 운영 시스템이 각 프로세스의 요구 사항과 우선순위를 더욱 정교하게 관리하고, 시스템 리소스 사용을 최적화하는 데 도움이 됩니다.
스케줄링 알고리즘
선입 선처리 스케줄링
정의
- 선입 선처리 스케줄링은 가장 간단한 CPU 스케줄링 알고리즘 중 하나로, CPU가 요청을 처리하는 순서가 요청이 도착한 순서대로 결정되는 방법
- 비선점형 스케줄링 방식임
주요특징
- 공정성: 모든 프로세스가 도착한 순서대로 처리되어, 특별한 우선순위 없이 공정하게 처리됩니다.
- 간단함: 구현이 매우 간단하여, 시스템의 부담이 적습니다.
- 프로세스 대기 시간: 빠르게 도착한 작업일지라도 무거운 작업에 의해 대기해야 하는 경우가 생길 수 있습니다(컨베이어 벨트 현상).
왜 쓰는지
- 단순한 시간 관리가 필요할 때: 복잡한 우선순위나 요구사항이 없는 시스템에서 효율적입니다.
- 구현 용이성: 다른 스케줄링 방식에 비해 알고리즘 구현이 간단하므로, 리소스가 제한적인 시스템에서 유리합니다.
언제 쓰는지
- 작업 우선순위가 중요하지 않은 환경: 모든 요청이 동등한 중요도를 가진다고 간주될 때 적합합니다.
- 부하가 적은 시스템: 시스템에 큰 부하가 없어 대기 시간이 크게 문제가 되지 않을 때 사용됩니다.
어떻게 쓰는지
- 프로세스가 시스템에 도착하면, 준비 큐의 끝에 추가됩니다.
- CPU가 사용 가능해지면, 준비 큐의 맨 앞에 있는 프로세스가 선택되어 실행됩니다.
- 실행이 끝날 때까지 CPU를 점유한 후 다음 프로세스가 선택됩니다.
사용예시
- 프린터 대기열: 여러 문서가 인쇄를 위해 도착한 순서대로 프린트됩니다. 모든 문서는 동일한 우선순위를 가지며, 먼저 요청된 문서가 먼저 인쇄됩니다.
- 고객 서비스 핫라인: 전화로 접수된 고객의 문의사항이나 요청이 접수된 순서대로 처리됩니다. 모든 고객 요청은 동등하게 취급되며, 먼저 도착한 요청이 먼저 처리
최단 작업 우선 스케줄링
정의
- 준비 큐에 삽입된 프로세스들 중 CPU 이용 시간의 길이가 가장 짧은 프로세스부터 실행하는 스케줄링 방식
주요특징
- 효율성: 평균 대기 시간을 최소화하는데 효과적입니다.
- 비선점형과 선점형: SJF는 비선점형과 선점형(SRTF) 두 버전이 있어 상황에 따라 선택적으로 사용할 수 있습니다.
- 별도의 예측 기법 필요: 실제 시스템에서는 프로세스의 CPU 버스트 시간을 미리 아는 것이 불가능하기 때문에, 과거의 실행 시간을 기반으로 예측하는 기법이 필요합니다.
- 기아 현상: 긴 작업이 짧은 작업에 의해 지속적으로 밀려 나머지 실행되지 못하는 현상이 발생할 수 있습니다.
왜쓰는지
- SJF 스케줄링은 평균 대기 시간을 최소화하는 것을 목표로 하기 때문에, 시스템의 전체적인 효율성을 높이고 사용자 경험을 향상시키기 위해 사용됩니다.
언제쓰는지
- 작업의 처리 시간이 빈번하게 변하지 않는 환경에서 효과적입니다.
- 배치 처리 시스템에서 주로 사용되며, 사용자 상호작용이 적거나 예측 가능한 시스템에서 유용합니다.
어떻게쓰는지
- 비선점형 SJF: 프로세스가 실행을 시작하면 완료될 때까지 CPU를 유지합니다. 새로운 프로세스는 준비 큐에서 대기하고, 현재 실행 중인 프로세스가 완료되면 준비 큐에서 다음으로 가장 짧은 CPU 버스트 시간을 가진 프로세스를 선택합니다.
- 선점형 SJF (SRTF): 실행 중인 프로세스보다 더 짧은 CPU 버스트 시간을 가진 새로운 프로세스가 도착하면 현재 프로세스를 중단하고 새 프로세스에게 CPU를 넘깁니다.
사용예시
- 웹 서버 로깅 시스템: 다수의 짧은 로깅 작업을 빠르게 처리하고자 할 때 사용할 수 있습니다.
- 배치 처리 시스템: 은행 거래 처리 시스템과 같이 처리 시간이 다양한 작업을 효율적으로 관리하기 위해 사용
라운드 로빈 스케줄링
정의
- 선입 선처리 스케줄링에 타임 슬라이스라는 개념이 더해진 스케줄링 방식
- 타임 슬라이스란 각 프로세스가 CPU를 사용할 수 있는 정해진 시간을 의미
- 즉 라운드 로빈 스케줄링은 정해진 타임 슬라이스만큼의 시간 동안 돌아가며 CPU를 이용하는 선점형 스케줄링
- 타임 퀀텀이 끝나면, 실행 중이던 프로세스는 준비 큐의 끝으로 이동하고, 준비 큐의 다음 프로세스가 CPU를 할당
주요특징
- 공평성: 모든 프로세스가 동일한 시간 동안 CPU 시간을 할당받아 실행됩니다.
- 응답 시간: 짧은 태스크 또는 사용자와 상호 작용하는 프로세스에 적합해 빠른 응답 시간을 제공합니다.
- 선점형 스케줄링: 타임 퀀텀이 끝나면 현재 실행 중인 프로세스가 중단되고 다른 프로세스가 실행됩니다.
- 타임 퀀텀 선택의 중요성: 타임 퀀텀의 길이가 성능에 큰 영향을 미칩니다. 너무 짧으면 컨텍스트 스위칭 오버헤드가 증가하고, 너무 길면 라운드 로빈의 장점이 줄어듭니다.
왜 쓰는지
- 모든 프로세스가 공평하게 자원을 할당받도록 하여 사용자 경험을 향상시키기 위해 사용합니다. 특히, 응답 시간이 중요한 시스템에서 효과적입니다.
언제 쓰는지
- 멀티태스킹 환경, 특히 타임 쉐어링 시스템에서 많이 사용됩니다. 사용자의 요청이 빈번하거나 여러 작업이 동시에 처리되어야 하는 경우에 적합합니다.
어떻게 쓰는지
- 모든 프로세스를 준비 큐에 넣습니다.
- CPU가 사용 가능하면 준비 큐의 첫 번째 프로세스에 CPU를 할당합니다.
- 타임 퀀텀이 끝나면, 현재 프로세스를 준비 큐의 끝에 재배치하고 다음 프로세스에게 CPU를 할당합니다.
- 모든 프로세스가 실행을 완료할 때까지 이 과정을 반복합니다.
사용 예시
- 인터넷 서버: 여러 사용자의 요청을 받아 동시에 처리해야 하는 웹 서버나 애플리케이션 서버에서 사용됩니다.
- 운영 시스템: 사용자의 대화형 세션을 처리하기 위해 대부분의 현대 운영 시스템에서 사용
최소 잔여 시간 우선 스케줄링
정의
- 최단 작업 우선 스케줄링 알고리즘과 라운드 로빈 알고리즘을 합친 스케줄링 방식
- 최소 잔여 시간 우선 스케줄링 하에서 프로세스들은 정해진 타임 슬라이스만큼 CPU를 사용하되, CPU를 사용할 다음 프로세스로는 남아있는 작업 시간이 가장 적은 프로세스가 선택
주요특징
- 효율성: 평균 대기 시간과 응답 시간을 최소화합니다.
- 선점형 스케줄링: 새로운 프로세스가 도착하면 현재 실행 중인 프로세스를 중단시키고 새 프로세스로 전환할 수 있습니다.
- 동적 스케줄링: 실행 중에 프로세스의 실행 시간 정보를 기반으로 스케줄을 조정합니다.
- 스타베이션(starvation) 방지: 잔여 실행 시간이 긴 프로세스보다 짧은 프로세스를 우선적으로 처리합니다.
왜 쓰는지
- SRTF 스케줄링은 시스템의 평균 대기 시간을 최소화하여 전체적인 성능을 향상시키고, 사용자 요구 사항에 빠르게 대응하도록 디자인되었습니다.
언제 쓰는지
- 응답 시간이 중요한 시간 공유 환경이나 멀티태스킹 시스템에서 효과적으로 사용됩니다.
- 특히, 실행 시간이 다양한 프로세스들을 효율적으로 관리해야 하는 경우에 적합합니다.
어떻게 쓰는지
- 모든 프로세스의 잔여 실행 시간을 추적합니다.
- 새 프로세스가 도착하면, 모든 준비된 프로세스 중에서 잔여 실행 시간이 가장 짧은 프로세스에 CPU를 할당합니다.
- 실행 중인 프로세스의 잔여 시간이 다른 프로세스의 도착으로 인해 더이상 최소가 아니게 되면, 현재 프로세스를 선점하고 새 프로세스를 실행시킵니다.
- 모든 프로세스의 실행이 완료될 때까지 이 과정을 반복합니다.
사용예시
- 실시간 운영 시스템: 실행 시간이 중요한 작업을 더 빨리 처리하기 위해 사용됩니다.
- 클라우드 컴퓨팅 환경: 다양한 클라이언트 요청을 신속하게 처리하기 위해 작은 작업을 우선적으로 처리합니다.
- 멀티태스킹 운영 체제: 사용자와 시스템의 다양한 요구를 효율적으로 만족시킬 수 있습니다.
우선순위 스케줄링
정의
- 프로세스에 대해 우선순위를 부여하고, 우선순위에 따라 CPU의 사용 권한을 결정하는 스케줄링 방법
주요특징:
- 우선순위 기반: 모든 프로세스는 특정 우선순위를 가집니다.
- 비선점형/선점형: 비선점형은 일단 CPU를 할당받으면 완료될 때까지 계속 실행되지만, 선점형은 높은 우선순위의 새 프로세스가 도착하면 현재 프로세스를 중단시킬 수 있습니다.
- 융통성: 시스템의 요구 사항에 따라 우선순위 부여 기준을 변경할 수 있습니다.
왜 쓰는지
- 중요하거나 긴급한 작업을 먼저 처리하여 시스템의 효율성을 높이고, 사용자 또는 시스템 요구에 따라 자원을 유연하게 할당하기 위해 사용됩니다.
언제 쓰는지
- 시스템의 특정 작업에 더 높은 응답성이나 처리 우선도가 필요할 때, 혹은 다양한 사용자 요구를 효율적으로 만족시켜야 하는 멀티태스킹 환경에서 주로 사용됩니다.
어떻게 쓰는지
- 시스템이나 사용자는 프로세스 작업에 우선순위를 지정하고, 스케줄러는 우선순위가 높은 순서대로 프로세스에 CPU 시간을 할당합니다.
- 비선점형에서는 프로세스가 자발적으로 CPU를 놓거나 작업이 완료될 때까지 CPU를 보유하며, 선점형에서는 더 높은 우선순위 프로세스가 도착하면 현재 프로세스를 중지시키고 새 프로세스에 CPU를 할당합니다.
사용 예시:
- 운영 체제: 사용자 인터페이스 반응성이 중요한 작업에 높은 우선순위를 부여해, 시스템이 더 빠르게 반응하도록 합니다.
- 실시간 시스템: 긴급한 태스크를 처리하는 데 사용됩니다. 예를 들어, 의료 모니터링 시스템에서 환자의 생명을 구할 수 있는 긴급한 데이터 처리에 높은 우선순위를 부여합니다.
- 네트워크 스케줄러: 대역폭이 제한된 환경에서 중요한 데이터 패킷에 더 높은 우선순위를 부여해, 중요한 정보가 우선적으로 전송될 수 있도록 합니다.
다단계 큐 스케줄링
정의
- 각각의 큐는 고유한 스케줄링 알고리즘을 가지거나 우선순위에 의해 운영될 수 있으며, 프로세스들은 특정 기준에 따라 다양한 큐 사이에 할당
주요특징:
- 분류 기반 관리: 프로세스를 우선순위나 유형별로 분류하여 관리합니다.
- 여러 큐 사용: 여러 큐에 걸쳐 프로세스를 할당하고 각 큐는 독립적인 스케줄링 기준을 가집니다.
- 효율성과 공정성: 다양한 유형의 프로세스 요구사항을 효율적으로 관리하며, 공정성을 보장합니다.
왜 쓰는지
- 서로 다른 요구사항을 가진 프로세스들을 효율적으로 관리하고, 시스템 자원을 효율적으로 사용하기 위해 적용됩니다.
언제 쓰는지
- 다양한 유형의 작업이나 프로세스가 존재하며, 이를 효율적으로 분류하고 관리해야 할 때 주로 사용됩니다.
어떻게 쓰는지:
- 시스템 요구사항에 따라 여러 큐를 생성합니다.
- 프로세스가 생성될 때, 그 특성에 따라 특정 큐에 할당됩니다.
- 각 큐는 독립적인 스케줄링 정책을 사용하여 프로세스를 관리합니다.
- 우선순위 큐가 있다면, 높은 우선순위 큐의 프로세스부터 처리합니다.
다단계 패드백 큐 스케줄링
정의
- 여러 개의 준비 큐를 사용하며, 프로세스는 실행 중에 다른 큐로 이동할 수 있습니다.
- 프로세스의 우선순위는 실행에 걸린 시간, 대기 시간, 입출력 요구 등에 따라 동적으로 변화할 수 있습니다.
주요 특징:
- 다중 큐: 여러 개의 큐를 사용하고 각 큐는 다른 우선순위 또는 시간 할당량을 가집니다.
- 우선 순위 변경: 프로세스는 실행 동안 제공되는 피드백에 따라 다른 큐로 이동할 수 있습니다.
- 사용자 정의 가능: 큐의 수, 우선 순위 규칙, 시간 할당량 등은 시스템 요구사항에 따라 조정될 수 있습니다.
왜 쓰는지
- 다양한 요구 사항과 실행 패턴을 가진 프로세스를 효과적으로 관리하기 위해.
- 이 방식은 시스템의 평균 대기 시간과 응답 시간을 최소화하며 높은 처리량을 유지함으로써 가변적인 작업 부하를 더 유연하게 처리할 수 있습니다.
언제 쓰는지
- 시스템에 짧은 작업과 긴 작업, CPU 집중형 및 입출력 집중형 작업 등 다양한 유형의 프로세스가 혼합되어 있을 때 사용합니다.
- 또한 시스템의 효율성과 반응성이 중요한 멀티 태스킹 환경에서 유용합니다.
어떻게 쓰는지
- 여러 큐를 설정하고 각 큐에 대한 우선 순위, 시간 할당량 등을 정의합니다.
- 새로 도착한 프로세스는 가장 높은 우선 순위 큐에 배치됩니다.
프로세스가 할당된 시간 동안 완료되지 않으면 하위 큐로 이동합니다. - 각 단계에서 프로세스의 행동(예: CPU 사용 시간, 대기 시간)에 따라 큐 사이를 이동할 수 있습니다.
사용 예시:
- 운영체제: 사용자 대화형 프로세스(빠른 응답 필요)에 높은 우선 순위를 부여하고 배치 처리 작업(시간이 덜 중요)에는 낮은 우선순위 큐를 사용합니다.
- 클라우드 서비스: 긴급 처리가 필요한 작업에 높은 우선 순위를 주고, 일반적인 배치 처리 작업에 대해서는 낮은 우선 순위 큐를 할당하여 자원 사용을 최적화합니다.
- 실시간 시스템: 실시간 데이터 처리 요구가 높은 프로세스를 우선적으로 처리하여 시스템의 반응 시간을 개선
다단계 큐 스케줄링 vs 다단계 피드백 큐 스케줄링
배경
- 우선 다단계 큐 스케줄링의 문제점은 각 큐 내에서의 스케줄링이 고정되어 있는것임
- 이는 즉, 프로세스가 한 번 특정 큐에 할당되면, 그 프로세스의 실행 특성이 변하더라도 그 큐를 벗어나 다른 큐로 이동할 수 없다는것을 의미
- 이로 인해 일부 프로세스가 불필요하게 오래 기다리거나, 시스템의 유연성이 저하될 수 있음
해결법
- 다단계 피드백 큐 스케줄링은 이러한 문제점을 해결하기 위해 등장
- 프로세스가 시스템의 운영 상황에 따라 다른 큐로 이동할 수 있음
- 프로세스의 우선순위가 실행 중에 변경 될 수있으므로, 프로세스의 특성이나 요구사항에 따라 더 유연하게 대응가능
두 스케줄링 기법의 주요 차이점
-
큐 간 이동성:
다단계 큐 스케줄링에서는 한 번 큐에 배정된 프로세스가 다른 큐로 이동할 수 없습니다.
다단계 피드백 큐 스케줄링에서는 프로세스가 실행 중에 다른 큐로 이동할 수 있어, 피드백을 바탕으로 동적으로 우선순위가 조정됩니다. -
유연성 및 효율성:
다단계 큐 스케줄링은 고정된 우선순위 및 큐 구조로 인해 특정 상황에서 비효율적일 수 있습니다.
다단계 피드백 큐 스케줄링은 프로세스의 특성과 시스템의 상황에 따라 유연하게 대응할 수 있어, 대체적으로 더 높은 효율성을 제공
