Redux Toolkit???
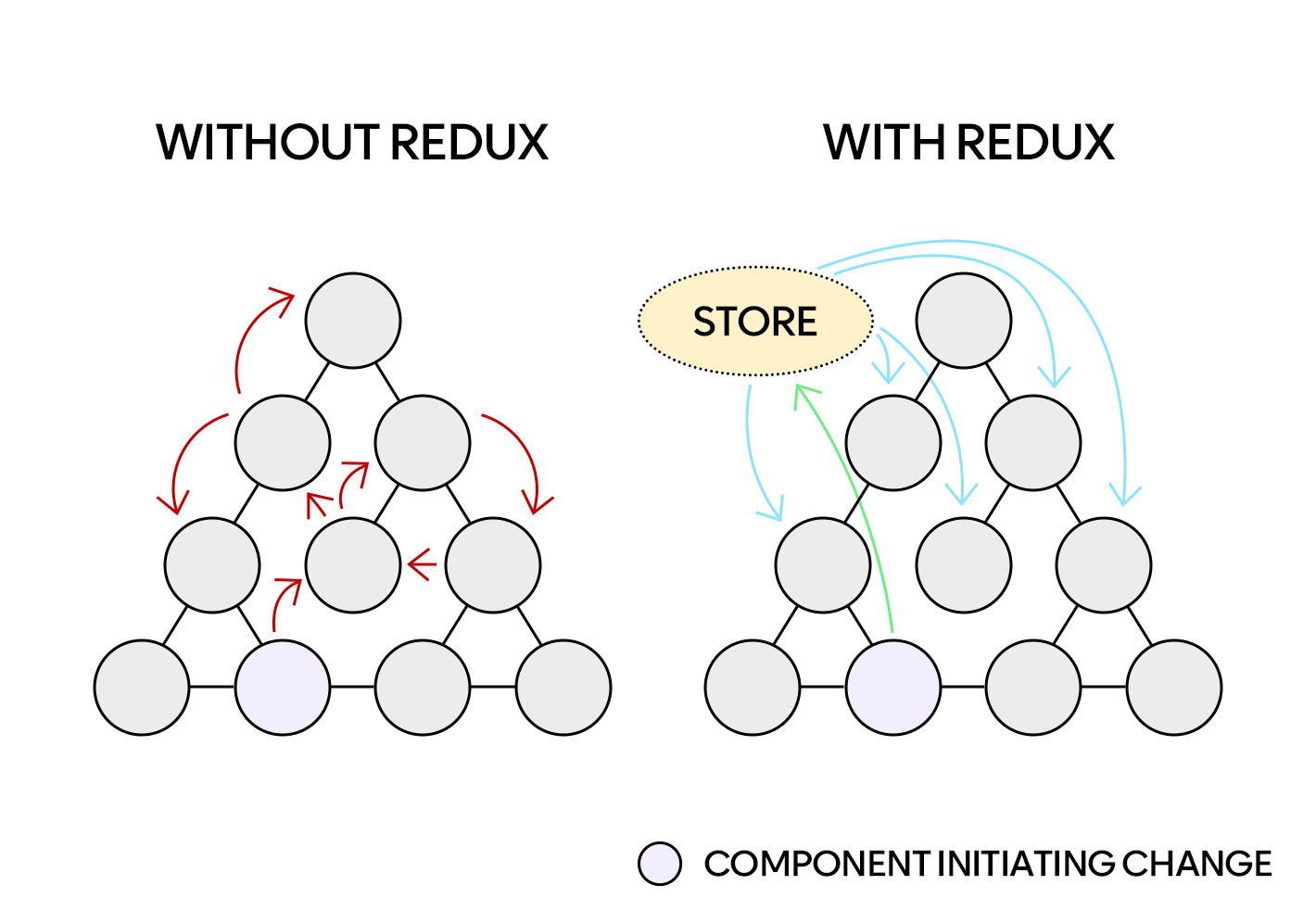
먼저 리덕스(Redux) 는 Flux 아키텍처의 구현체로 대형 MVC 애플리케이션에서 종종 나타나는 데이터 간 의존성 이슈, 즉 연쇄적인 갱신이 뒤얽혀 데이터의 흐름을 예측할 수 없게 만들었던 문제를 해결하기 위해서 고안되었습니다.
2014년 컨퍼런스에서 소개된 페이스북의 채팅 버그가 있었습니다.
[읽지 않은 메시지 상태]를 나타내는 카운트를 확인하고 사용자가메시지를 확인해도 어느새 좀비처럼 카운트 숫자가 되살아나면서 사용자를 괴롭히던 버그였습니다. 다시 확인했을 때 새로운 내용은 아무것도 없는데 말이지요. 개발자가 버그를 수정해도 잠시 동안은 괜찮아 보였다가 계속해서 같은 버그가 보고되는 상황이 연출됐습니다. 이러한 경험을 거치면서 페이스북 팀은 설계에 기반한 근본적인 문제가 있다고 판단했다고 합니다.
그래서 그 해결책으로 애플리케이션의 데이터가 단방향으로 흐르는 방법을 고안하게 됩니다. 그것은 플럭스 아키텍처의 핵심 멘탈 모델, 다시 말해서 사고 과정, 동기, 철학적 배경 등에 대해 깊이 이해할 수 있게 하는 하나의 모델이 되었고 그 구현체인 리덕스는 애플리케이션을 위한 상태 컨테이너로써 단방향 데이터 흐름을 활용하여 시스템을 예측 가능하게 만들어서 시스템을 보완하는 역할을 하게 됩니다.
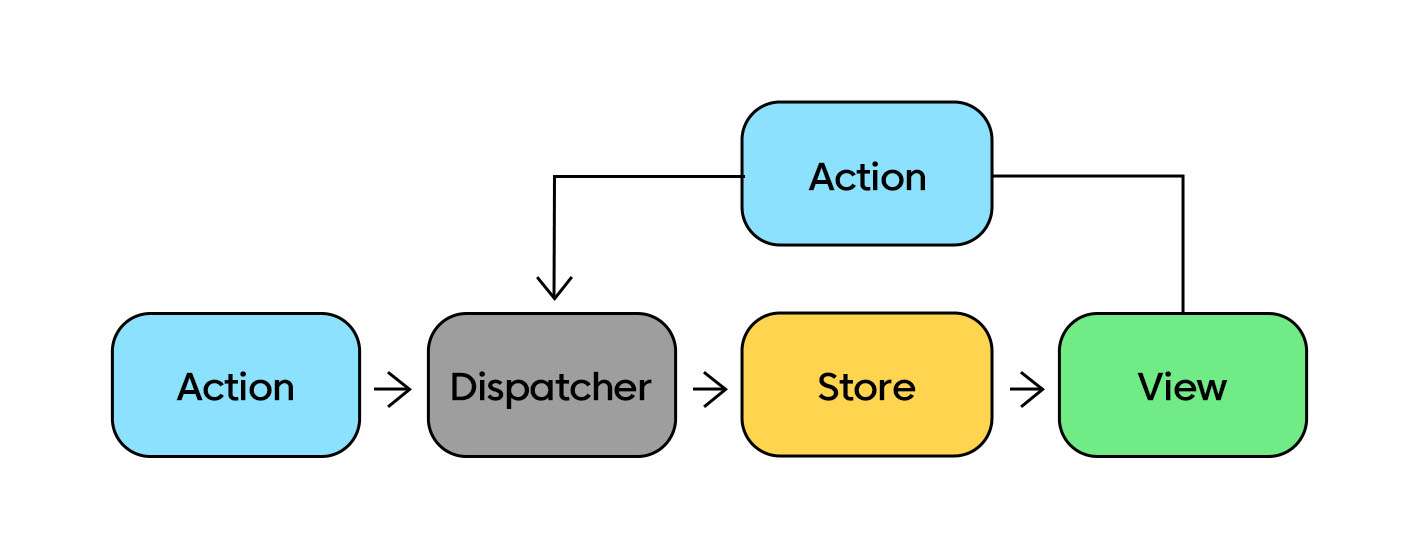
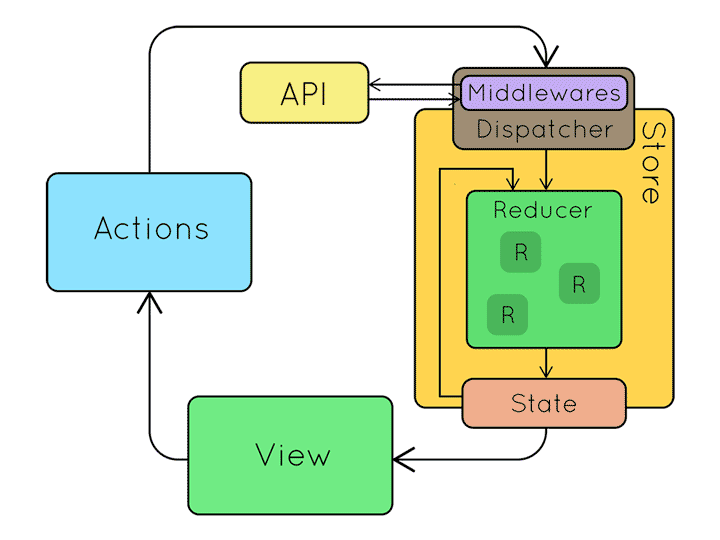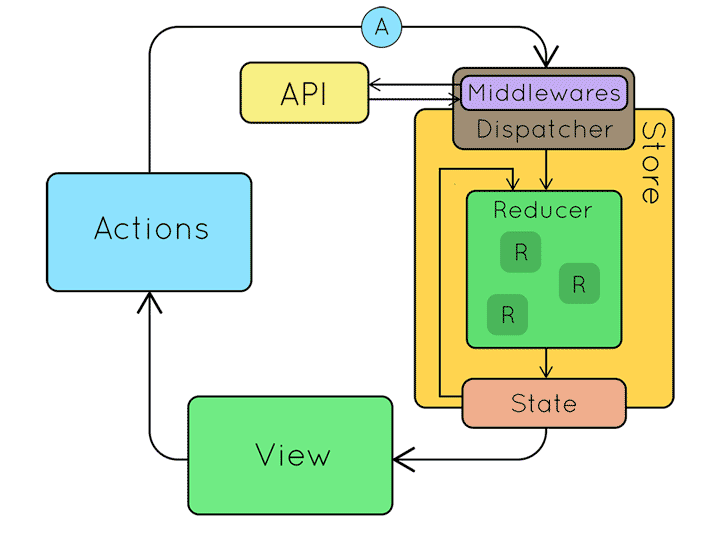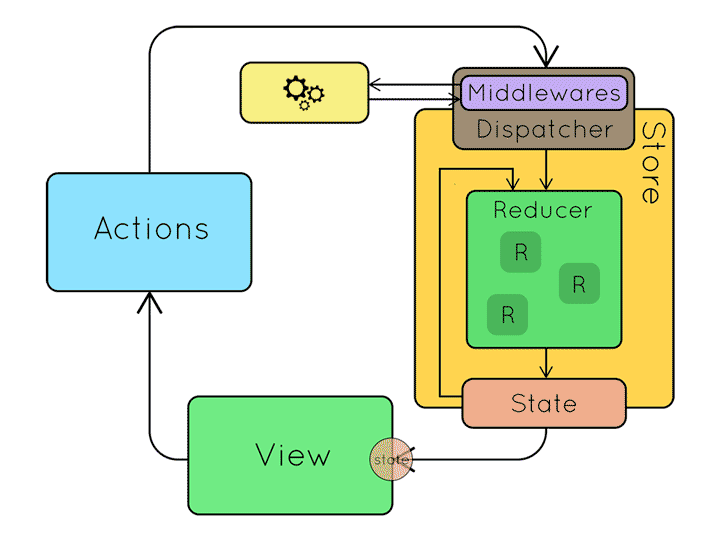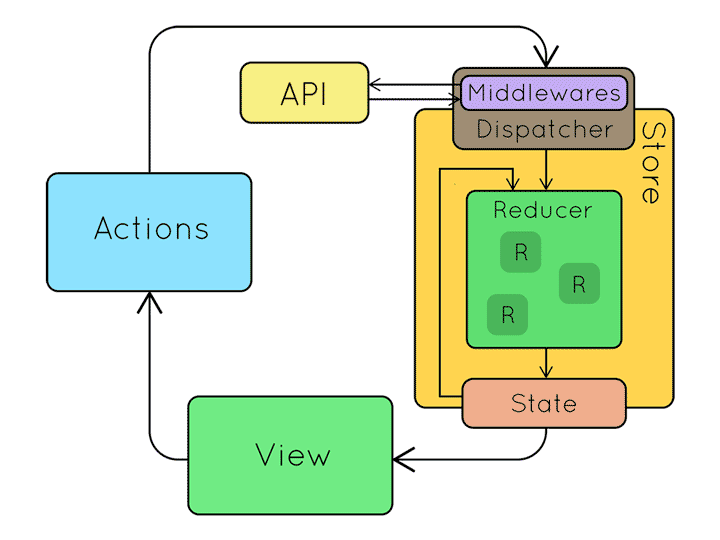
리덕스를 사용하는 구조에서는 전역 상태를 전부 하나의 저장소(store) 안에 있는 객체 트리에 저장하며, 상태를 변경하는 것은 어떤 일이 일어날지를 서술하는 객체인 액션(action)을 내보내는(dispatch) 것이 유일한 방법입니다. 그리고 액션이 전체 애플리케이션의 상태를 어떻게 변경할지 명시하기 위해서는 리듀서(reducer)의 작성이 필요합니다.
위 흐름도와 같이 사용자의 상호작용에 응답하기 위해서 뷰는 액션을 만들어서 시스템에 전파 하는 방식으로 진행하게 되었습니다.
reducer(이하 리듀서)는 변화를 일으키는 함수로써 전달받은 액션을 가지고 새로운 상태를 만들어서 스토어에 전달합니다. 이 모든 설계는 데이터가 단방향으로 흐른다는 전제하에 데이터의 일관성을 향상시키고 버그 발생 원인을 더 쉽게 파악하려는 의도에서 출발했음을 알게 되었습니다.
지금까지의 설명만으로는 리덕스 그 자체만으로도 무결해서 웹 애플리케이션 개발에 꼭 필요한 잘 설계된 아키텍처의 훌륭한 대안이 될 것만 같은데요.
그렇다면 이처럼 완전할 것만 같은 리덕스를 뒤로하고 RTK는 어떤 목적을 가지고 세상에 나온 것일까요? 간단히 말하자면 리덕스를 더 쉽게 사용하기 위해서입니다. 이름 그대로 리덕스를 위한 도구 모음(키트)인 것이지요.
사실 완벽할 것만 같았던 리덕스에도 문제가 있었습니다. 대표적으로 언급되는 리덕스의 3가지 문제는 아래와 같습니다.
- 리덕스 스토어 환경 설정은 너무 복잡하다!
- 리덕스를 유용하게 사용하려면 많은 패키지를 추가해야 한다!
- 리덕스로 어떤 일을 하기 위해 꼭 작성해야 하는 (상용구)코드를 너무 많이 요구한다!
이러한 이슈를 해결하기 위해 툴킷이 등장합니다. 공식 문서에 따르면 RTK는 리덕스 로직을 작성하는 표준 방식이 되기 위한 의도로 만들어졌다고 합니다.
핵심은 기존 리덕스의 복잡함을 낮추고 사용성을 높이는 것입니다.
그럼 RTK은 뭐가 달라졌을까?
1. configureStore() *
가장 먼저 스토어를 구성하는 함수에 대해서 알아보겠습니다. configureStore는 리덕스 코어 라이브러리의 표준 함수인 createStore를 추상화한 것입니다. 더 좋은 개발 경험을 위해서 기존 리덕스의 번거로운 기본 설정 과정을 자동화하는 것인데요. 아래처럼 간단히 작성할 수 있습니다.
import { configureStore } from '@reduxjs/toolkit'
import rootReducer from './reducers'
const store = configureStore({ reducer: rootReducer })위처럼 선언하면 기본 미들웨어로 redux-thunk를 추가하고 개발 환경에서 리덕스 개발자 도구(Redux DevTools Extension)를 활성화해줍니다. 이전에는 매번 프로젝트를 시작할 때마다 이런 설정을 직접 하는 불편한 과정이 있었다고 하니 개발 경험을 높이기 위해서 그동안 RTK가 어떤 접근을 했었는지 알 수 있었습니다.
다음 예제는 configureStore를 사용한 전체적인 구성을 담고 있습니다.
import logger from 'redux-logger'
import { reduxBatch } from '@manaflair/redux-batch'
import todosReducer from './todos/todosReducer'
import visibilityReducer from './visibility/visibilityReducer'
const rootReducer = {
todos: todosReducer,
visibility: visibilityReducer,
}
const preloadedState = {
todos: [
{
text: 'Eat food',
completed: true,
},
{
text: 'Exercise',
completed: false,
},
],
visibilityFilter: 'SHOW_COMPLETED',
}
const store = configureStore({
reducer,
middleware: (getDefaultMiddleware) => getDefaultMiddleware().concat(logger),
devTools: process.env.NODE_ENV !== 'production',
preloadedState,
enhancers: [reduxBatch],
})configureStore 함수는 reducer, middleware, devTools, preloadedState, enchancer 정보를 전달합니다.
-
reducer: 리듀서에는 단일 함수를 전달하여 스토어의 루트 리듀서(root reducer)로 바로 사용할 수 있습니다. 또한 슬라이스 리듀서들로 구성된 객체를 전달하여 루트 리듀서를 생성하도록 할 수 있습니다. 이런 경우에는 내부적으로 기존 리덕스 combineReducers 함수를 사용해서 자동적으로 병합하여 루트 리듀서를 생성합니다. -
middleware: 기본적으로는 리덕스 미들웨어를 담는 배열입니다. 사용할 모든 미들웨어를 배열에 담아서 명시적으로 작성할 수도 있는데요. 그렇지 않으면 getDefaultMiddleware를 호출하게 됩니다. 사용자 정의, 커스텀 미들웨어를 추가하면서 동시에 리덕스 기본 미들웨어를 사용할 때 유용한 방법입니다. -
devTools: 불리언값으로 리덕스 개발자 도구를 끄거나 켭니다. -
preloadedState: 스토어의 초기값을 설정할 수 있습니다. -
enchaners: 기본적으로는 배열이지만 콜백 함수로 정의하기도 합니다. 예를 들어 다음과 같이 작성하면 개발자가 원하는 store enhancer를 미들웨어가 적용되는 순서보다 앞서서 추가할 수 있습니다.
const store = configureStore({
...
enhancers: (defaultEnhancers) => [reduxBatch, ...defaultEnhancers],
})
// [reduxBatch, applyMiddleware, devToolsExtension]리덕스 미들웨어 (Redux Middleware)
여기까지 리서치를 마치고 나니, 궁금증이 생겼습니다.
리덕스에서 미들웨어란 무엇일까요? 그리고 미들웨어는 어떤 역할을 할까요? 먼저 용어에 대해 정리해 보고자 합니다. 소프트웨어 공학에서 미들웨어란 운영 체제와 응용 소프트웨어 중간에서 조정과 중개의 역할을 수행하는 소프트웨어로 정의됩니다.
그렇다면 리덕스에서 미들웨어의 역할은 무엇일까요?
리덕스 미들웨어는 dispatch(이하 디스패치)된 액션이 리듀서에 도달하기 전 중간 영역에서 사용자의 목적에 맞게 기능을 확장할 수 있도록 돕습니다. 예를 들어 미들웨어로 redux-logger를 추가했다면 액션이 디스패치될 때마다 개발자 도구 콘솔에 로그가 찍히는 것을 생각해 볼 수 있습니다. 로그를 출력하는 과정이 중간에 추가된 것이지요. 이처럼 개발자는 자신의 필요에 의해 미들웨어를 작성하여 원하는 목적을 달성할 수 있습니다.
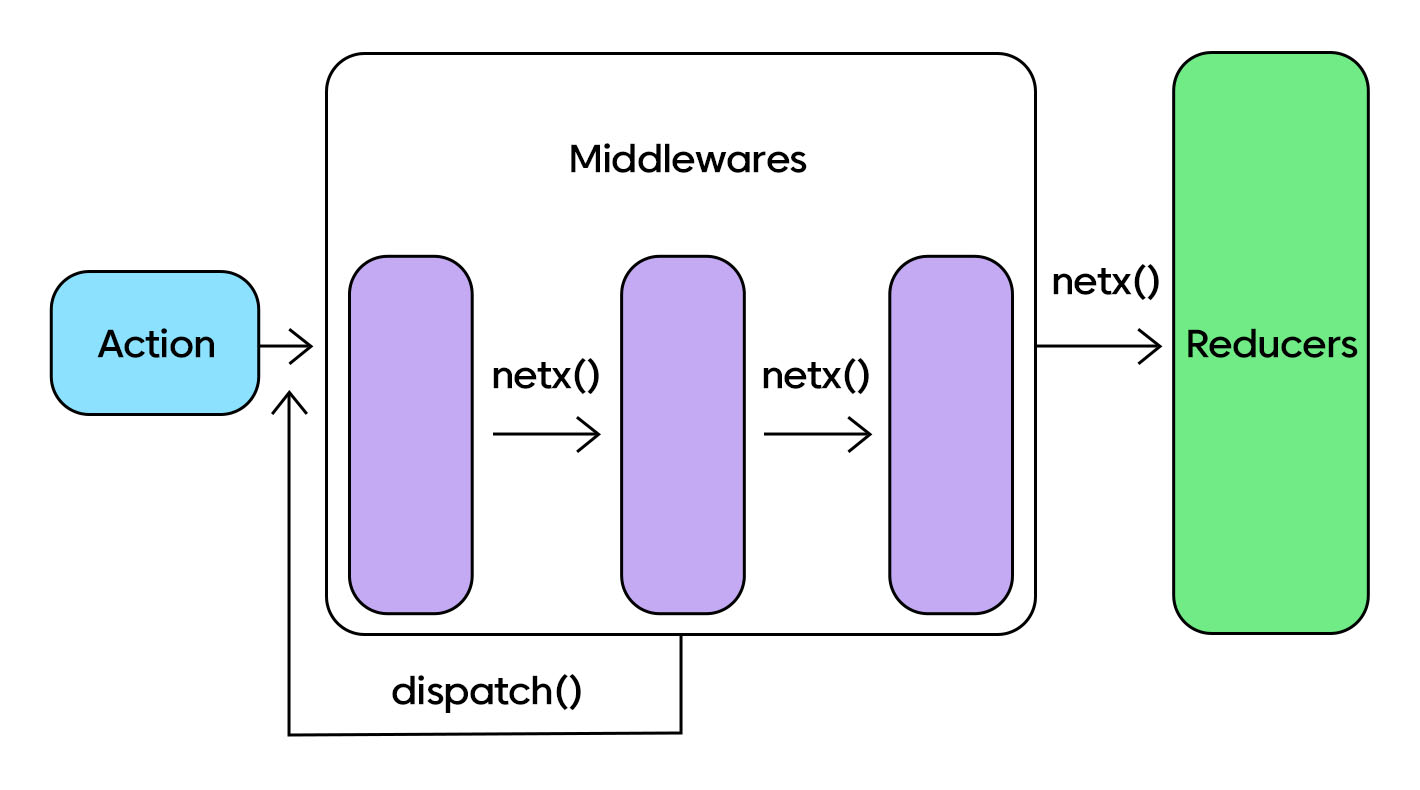
// 각각의 미들웨어는 next 함수에 액션을 담아서
// 리듀서까지 전파해 나갑니다.
// 아래는 커스텀 미들웨어를 작성한 코드입니다.
const customMiddleware = (storeApi) => {
return (next) => {
return (action) => {
// 개발자는 이곳에 자신의 목적에 알맞은 코드를 추가할 수 있습니다.
// ...
return next(action);
};
};
};
const store = configureStore({
middleware: (getDefaultMiddleware) =>
getDefaultMiddleware().concat(customMiddleware)
});이외에도 개발 모드에서 일부 미들웨어는 특정한 역할을 기본적으로 수행합니다. 상태의 변형(mutation)을 감지하거나 직렬화, 즉 데이터를 다른 데이터 구조로 맞추어 가공하는 행위가 불가능한 값(non-serializable value)을 사용하는 실수를 방지할 수 있도록 경고해 줍니다.
여기서 직렬화가 불가능하다는 의미는 어떤 데이터를 직렬화 하는 과정에서 데이터를 유실할 수도 있다는 것인데요. 자바스크립트에서는 JSON-serialization를 사용하는데 예제를 살펴보면 아래와 같습니다.
// { it: 'has data' } 객체를 JSON 데이터 포맷으로 직렬화합니다.
const stringifiedObject =
JSON.stringify({ it: 'has data' }); // {"it":"has data"}
// 이것을 다시 역직렬화를 하면
// 처음 내용과 동일한 데이터를 담고 있음을 확인할 수 있습니다.
JSON.parse(stringifiedObject); // { it: 'has data' }
// 그러나 아래처럼 Set 자료형을 직렬화 한다면
// 그 과정에서 데이터가 유실됩니다.
const setObject = new Set([1, 2, 3]); // Set(3) {1, 2, 3}
const stringifiedSetObject =
JSON.stringify(setObject); // {}
// 역직렬화해도 데이터가 이미 유실된 상태이기 때문에
// 본래 값과 차이가 발생하여 앱이 기대하지 않은 방식으로 동작할 수 있습니다.
JSON.parse(stringifiedSetObject); // {}
이러한 이유로 직렬화가 불가능한 값을 액션이나 상태에서 사용하지 않는 것을 권장합니다. 직렬화가 불가능한 값들은 Promise, Symbol, Map/Set, function, class instance 등이 있습니다. 반면에 직렬화가 가능한 값들은 자바스크립트 원시 자료형에 속하는 string, number, null, undefined와 array, object literal(객체 리터럴) 방식으로 선언된 plain object가 있습니다.
- Redux state is normally plain JS objects and arrays.
2. createReducer()
상태에 변화를 일으키는 리듀서 함수를 생성하는 유틸 함수입니다. 내부적으로 immer 라이브러리 사용하여 mutative한 코드, 예컨대 state.todos[3].completed = true 형태로 작성해도 불변(immutable) 업데이트가 이루어지도록 로직을 간단히 할 수 있습니다.
그렇지 않으면 아래처럼 중첩된 모든 단계에서 복사가 필요한데요. 이는 사용자의 실수로 원본 객체에 직접적인 변형을 일으키거나 얕은 복사가 이루어지는 등, 다양한 사이드 이펙트를 발생시켜 애플리케이션이 예기치 않게 동작할 위험성이 있습니다. 게다가 코드가 길어지기도 하고요.🤢
// 기존 스위치 문으로 이루어진 카운터 리듀서 함수입니다.
// 많은 보일러플레이트 코드와 에러를 발생시키기 쉬운 구조를 보여주고 있습니다.
function todosReducer(state = [], action) {
switch (action.type) {
case 'UPDATE_VALUE': {
return {
...state,
first: {
...state.first,
second: {
...state.first.second,
[action.someId]: {
...state.first.second[action.someId],
fourth: action.someValue,
},
},
},
};
}
default: {
return state;
}
}
}
// 하지만 createReducer 함수를 사용하면 아래처럼 간단히 작성할 수 있습니다.
const todosReducer = createReducer(state = [], (builder) => {
builder.addCase('UPDATE_VALUE', (state, action) => {
const {someId, someValue} = action.payload;
state.first.second[someId].fourth = someValue;
})
})RTK에서 case reducer(이하 케이스 리듀서)가 액션을 처리하는 두 가지 방법은 builder callback 표기법과 map object 표기법이 있습니다. 두 방법 모두 동일한 역할을 하지만 타입스크립트와의 호환성을 위해서는 builder callback 표기법이 더 선호됩니다.
Builder Callback 표기법
createReducer의 콜백 함수 인자로 주어지는 builder 객체는 addCase, addMatcher, addDefaultCase라는 메서드를 제공합니다. 그리고 각 함수에서 액션을 리듀서에서 어떻게 처리할지를 정의할 수 있습니다.
작성하는 방법은 각 라인마다 빌더 메서드를 나누어 호출하거나 체이닝(chaining) 형태로 작성하는 것입니다.
// 각 라인마다 빌더 메서드를 나누어 호출합니다.
const counterReducer = createReducer(initialState, (builder) => {
builder.addCase(increment, (state) => {})
builder.addCase(decrement, (state) => {})
})
// 또는 메서드 호출을 연결하여 연속적으로 작성합니다.
const counterReducer = createReducer(initialState, (builder) => {
builder
.addCase(increment, (state) => {})
.addCase(decrement, (state) => {})
})builder callback의 주요 메서드를 살펴보면 다음과 같습니다.
createReducer(initialState, builderCallback)
-
builder.addCase(actionCreator, reducer): 액션 타입과 맵핑되는 케이스 리듀서를 추가하여 액션을 처리합니다.addMatcher또는addDefaultCase메서드 보다 먼저 작성되어야 합니다. -
builder.addMatcher(matcher, reducer): 새로 들어오는 모든 액션에 대해서 주어진 패턴과 일치하는지 확인하고 리듀서를 실행합니다. -
builder.addDefaultCase(reducer): 그 어떤 케이스 리듀서나 매처 리듀서도 실행되지 않았다면, 기본 케이스 리듀서가 실행됩니다.
const increment = createAction('increment')
const decrement = createAction('decrement')
function isActionWithNumberPayload(
action: AnyAction
): action is PayloadAction {
return typeof action.payload === 'number'
}
const initialState = {
counter: 0,
sumOfNumberPayloads: 0,
unhandledActions: 0,
};
const counterReducer = createReducer(initialState, (builder) => {
builder
.addCase(increment, (state, action) => {
state.counter += action.payload
})
.addCase(decrement, (state, action) => {
state.counter -= action.payload
})
.addMatcher(isActionWithNumberPayload, (state, action) => {})
.addDefaultCase((state, action) => {})
})Map Object 표기법
액션 타입 문자열을 ‘키’로 사용하는 객체를 받아서 케이스 리듀서에 맵핑합니다. 이는 builder callback 표기법보다 짧게 작성할 수 있다는 장점이 있기는 하지만 JavaScript를 사용하는 프로젝트에 유효한 방법입니다. TypeScript를 고려한다면 대부분의 경우 builder callback 표기법을 권장합니다.
const counterReducer = createReducer(0, {
increment: (state, action) => state + action.payload,
decrement: (state, action) => state - action.payload
})
// 위 예제처럼 작성하거나
// 또는 'createAction'에서 생성된 액션 생성자(action creator)를
// 연산된 프로퍼티(computed property) 문법을 사용해서 바로 '키'로 사용할 수 있습니다.
const increment = createAction('increment')
const decrement = createAction('decrement')
const counterReducer = createReducer(0, {
[increment]: (state, action) => state + action.payload,
[decrement.type]: (state, action) => state - action.payload
})
아래는 map object 표기법을 사용하는 createReducer 함수의 인자를 차례로 나열한 것입니다.
createReducer(initialState, actionsMap, actionMatchers, defaultCaseReducer)
-
initialState: 리듀서가 최초로 호출되었을 때 사용될 상태 값입니다. -
actionsMap: 액션 타입이 케이스 리듀서에 맵핑되어 있는 객체입니다. -
actionMatchers:{ matcher, reducer }형태로 정의된 매처를 배열로 담습니다. 매칭된 리듀서는 순서대로 독립적으로 실행됩니다. -
defaultCaseReducer: 그 어떤 케이스 리듀서나 매처 리듀서도 실행되지 않았다면, 기본 케이스 리듀서가 실행됩니다.
// matcher
const isStringPayloadAction = (action) => typeof action.payload === 'string'
const lengthOfAllStringsReducer = createReducer(
// initialState
{ strLen: 0, nonStringActions: 0 },
// actionsMap
{
/* [...]: (state, action) => {} */
},
// actionMatchers
[
{
matcher: isStringPayloadAction,
reducer(state, action) {
state.strLen += action.payload.length
},
},
],
// defaultCaseReducer
(state) => {
state.nonStringActions++
}
3. createAction()
기존 리덕스 코어 라이브러리에서 액션을 정의하는 일반적인 접근법은 액션 타입 상수와 액션 생성자 함수를 분리하여 선언하는 것이었습니다. RTK에서는 이러한 두 과정을 createAction 함수를 사용하여 하나로 결합하여 추상화했습니다.
// BEFOR
const INCREMENT = 'counter/increment'
function increment(amount: number) {
return {
type: INCREMENT,
payload: amount,
}
}
const action = increment(3)
// { type: 'counter/increment', payload: 3 }
// AFTER
import { createAction } from '@reduxjs/toolkit'
const increment = createAction('counter/increment')
const action = increment(3)
// { type: 'counter/increment', payload: 3 }
개인적으로 리서치를 하면서 흥미로웠던 부분은 createAction 함수가 toString() 메서드를 오버라이딩하여 action creator (이하 액션 생성자) 객체를 액션 타입 문자열로 표현할 수 있도록 했다는 점입니다. 덕분에 map object 표기법에서 아래처럼 액션 생성자를 직접 키로 사용할 수 있습니다.
const increment = createAction('counter/increment')
const counterReducer = createReducer(0, {
[increment]: (state, action) => state + action.payload,
[decrement.type]: (state, action) => state - action.payload
})
console.log(increment.toString())
// 'counter/increment'
console.log(`The action type is: ${increment}`)
// 'The action type is: counter/increment'
액션 콘텐츠 편집하기
일반적으로 액션 생성자는 단일 인자를 받아서 action.payload 값을 생성하지만 payload에 사용자 정의 값을 추가하고 싶은 경우가 있을 수 있습니다. 랜덤 아이디 값을 만들거나, 액션이 생성되는 시점을 넣는 행위 등이 여기에 해당하는데요. prepare callback 함수를 사용해서 원하는 값을 추가하고 플럭스 표준 액션(FSA) 형태로 반환할 수 있습니다.
import { createAction, nanoid } from '@reduxjs/toolkit'
const addTodo = createAction('todos/add', function prepare(text: string) {
return {
payload: {
text,
id: nanoid(),
createdAt: new Date().toISOString(),
},
}
})
console.log(addTodo('Write more docs'))
/**
* {
* type: 'todos/add',
* payload: {
* text: 'Write more docs',
* id: '4AJvwMSWEHCchcWYga3dj',
* createdAt: '2019-10-03T07:53:36.581Z'
* }
* }
**/4. createSlice() *
const alertSlice = createSlice({
name: 'todos',
initialState,
reducers: {},
extraReducers: (builder) => {}
});리덕스 로직을 작성하는 표준 접근법은 createSlice를 사용하는 것에서 출발합니다.
앞서 소개해드린 createAction, createReducer 함수가 내부적으로 사용되며 createSlice에 선언된 슬라이스 이름을 따라서 리듀서와 그리고 그것에 상응하는 액션 생성자와 액션 타입을 자동으로 생성합니다. 따라서 createSlice를 사용하면 따로 createAction, createReducer를 작성할 필요가 없습니다.☺️
공식 문서의 리덕스 스타일 가이드에 따르면 슬라이스 파일은 feature 폴더 안에서 상태 도메인 별로 나누어 정리하고 있습니다.
// features/todos/todosSlice.js
import { createSlice, PayloadAction } from '@reduxjs/toolkit'
import { nanoid } from 'nanoid'
interface Item {
id: string
text: string
}
// 투두 슬라이스
const todosSlice = createSlice({
name: 'todos',
initialState: [] as Item[],
reducers: {
// 액션 타입은 슬라이스 이름을 접두어로 사용해서 자동 생성됩니다. -> 'todos/addTodo'
// 이에 상응하는 액션 타입을 가진 액션이 디스패치 되면 리듀서가 실행됩니다.
addTodo: {
reducer: (state, action: PayloadAction) => {
state.push(action.payload)
},
// 리듀서가 실행되기 이전에 액션의 내용을 편집할 수 있습니다.
prepare: (text: string) => {
const id = nanoid()
return { payload: { id, text } }
},
},
},
})
const { actions, reducer } = todosSlice
export const { addTodo } = actions
export default reducer
extraReducers
extraReducers는 createSlice가 생성한 액션 타입 외 다른 액션 타입에 응답할 수 있도록 합니다. 슬라이스 리듀서에 맵핑된 내부 액션 타입이 아니라, 외부의 액션을 참조하려는 의도를 가지고 있습니다.
const usersSlice = createSlice({
name: 'users',
initialState: { entities: [], loading: 'idle' },
reducers: {},
extraReducers: (builder) => {
// 'users/fetchUserById' 액션 타입과 상응하는 리듀서가 정의되어 있지 않지만
// 아래처럼 슬라이스 외부에서 액션 타입을 참조하여 상태를 변화시킬 수 있습니다.
builder.addCase(fetchUserById.fulfilled, (state, action) => {
state.entities.push(action.payload)
})
},
})
비동기 액션을 생성하는 createAsyncThunk 함수와의 조화를 생각해 볼 수 있는데요. 위 예제는 아래에서 이어서 다시 알아보겠습니다
5. createAsyncThunk *
createAction의 비동기 버전을 위해서 제안되었습니다. 액션 타입 문자열과 프로미스를 반환하는 콜백 함수를 인자로 받아서 주어진 액션 타입을 접두어로 사용하는 프로미스 생명 주기 기반의 액션 타입을 생성합니다.
import { createAsyncThunk, createSlice } from '@reduxjs/toolkit'
import { userAPI } from './userAPI'
const fetchUserById = createAsyncThunk(
'users/fetchByIdStatus',
async (userId, thunkAPI) => {
const response = await userAPI.fetchById(userId)
return response.data
}
)
const usersSlice = createSlice({
name: 'users',
initialState: { entities: [], loading: 'idle' },
reducers: {},
// extraReducers에 케이스 리듀서를 추가하면
// 프로미스의 진행 상태에 따라서 리듀서를 실행할 수 있습니다.
extraReducers: (builder) => {
builder
.addCase(fetchUserById.pending, (state) => {})
.addCase(fetchUserById.fulfilled, (state, action) => {
state.entities.push(action.payload)
})
.addCase(fetchUserById.rejected, (state) => {})
},
})
// 위에서 fetchUserById, 즉 thunk를 작성해두고
// 앱에서 필요한 시점에 디스패치 하여 사용합니다.
// ...
dispatch(fetchUserById(123))
꼭 서버와 통신이 이루어지는 구간에서만 사용되어야 하는 것은 아닙니다. 비즈니스 로직을 비동기 형태로 구현할 때에도 응용할 수 있습니다. 예를 들어 사용자가 UI와 상호작용한 이후에 이행된 프로미스 결과에 따라서 어떤 로직을 실행해야 하는지 응집도 높게 작정할 수 있습니다. 코드는 이런 모습입니다.
const ReactComponent = () => {
const { openDialog } = useDialog();
// (아래 GIF처럼 버튼의 onClick 액션을 핸들링하는 함수입니다.)
const handleSubmit = async (): Promise => {
// 화면에 띄울 다이얼로그를 선언하고, 프로미스 결과를 기다립니다.
// 사용자가 '동의' 버튼을 누르면 true로 평가됩니다.
const hasConfirmed = await openDialog({
title: '데이터 전송',
contents: '입력한 데이터를 전송할까요?',
});
if (hasConfirmed) {
// 이후 비즈니스 로직 실행
}
};
}
const useDialog = () => {
const dispatch = useAppDispatch();
// 리액트 컴포넌트에서 훅을 사용해서 openDialog 함수를 호출했다면
// 썽크(thunk) 액션 생성자 함수를 통해서 액션을 디스패치하게 됩니다.
const openDialog = async (state: DialogContents): Promise => {
const { payload } = await dispatch(confirmationThunkActions.open(state));
return payload
};
// ...
return {
openDialog,
...
}
};
const confirmationThunkActions = {
open: createAsyncThunk<
boolean,
DialogContents,
{ extra: ThunkExtraArguments }
>('dialog', async (payload, { extra: { store }, dispatch }) => {
// thunk 액션이 실행되고, 실제로 다이얼로그가 열리는 부분입니다.
dispatch(openDialog(payload));
return new Promise<boolean>((resolve) => {
// 스토어를 구독하고 상태 변경을 감지하면
// 사용자의 '동의', '거절' 액션에 맞추어 resolve 처리합니다.
const unsubscribe = store.subscribe(() => {
const { dialog } = store.getState() as RootState;
if (dialog.isConfirmed) {
unsubscribe();
resolve(true);
}
if (dialog.isDeclined) {
unsubscribe();
resolve(false);
}
});
});
}),
};
export default confirmationThunkActions;위와 같은 패턴으로 작성하게 되면 서로 먼 거리에서 소통을 주고받아야 하는 객체 간의 메시지 전달을 리덕스 스토어를 통해서 효율적으로 달성할 수 있게 됩니다. 아래처럼 리액트 컴포넌트에서 각각의 다이얼로그가 어떤 역할을 수행해야 하는지 명시적으로 하나하나 전달하지 않아도 됩니다.
RTK를 활용해서 컴포넌트에서 다이얼로그의 의존성을 제거할 수 있습니다.
return (
<div>
<main>콘텐츠</main>
<Dialog
isOpen={isOpen1}
title={title1}
contents={title2}
onConfirmed={handleConfirmedCase1}
onDeclined={handleDeclinedCase1}
/>
<Dialog
isOpen={isOpen2}
title={title2}
contents={contents2}
onConfirmed={handleConfirmedCase2}
onDeclined={handleDeclinedCase2}
/>
</div>
)
// 위 예체처럼 다이얼로그 선언하고 많은 핸들링 함수를 넘겨서 사용하던 부분에서 개선을 기대할 수 있습니다.
6. createSelector
리덕스 스토어 상태에서 데이터를 추출할 수 있도록 도와주는 유틸리티입니다. Reselect 라이브러리에서 제공하는 함수를 그대로 가져온 것인데요. RTK에서 지원하는 이유는 useSelector 함수의 결점을 보완하기 위한 좋은 솔루션이기 때문입니다.
// useSelector는 스토어에서 값을 조회합니다.
const users = useSelector((state) => state.users)Reselect 라이브러리를 살펴보면 createSelector 함수가 memoization(이하 메모이제이션), 즉 이전에 계산한 값을 메모리에 저장하여 값이 변경됐을 경우에만 계산하도록 동작하는 것을 확인할 수 있었습니다. 이것은 아래와 같은 상황을 개선할 수 있는데요.
const users = useSelector(
(state) => state.users.filter(user => user.subscribed)
);
컴포넌트의 구현부에 작성된 인라인 useSelector 훅은 스토어를 자동으로 구독하고 있기 때문에 상태 트리가 갱신되어 컴포넌트를 다시 render 해야 되는 경우 매번 새로운 인스턴스를 생성하게 됩니다.
위 예제에서는 어떤 서비스를 구독 중인 사용자, subscribed user를 조회하기 위해서 filter 함수를 사용하고 있는데요. useSelector가 실행될 때마다 필터 함수는 매번 새로운 배열을 반환하게 되면서 이전에 참조하고 있던 객체 주소가 현재 주소와의 차이를 발생시키게 됩니다. 그리고는 re-rendering을 발생시키는데 이때 재계산이 필요한 상태 트리의 사이즈나 계산 비용이 크다면 성능 문제로 이어질 수 있습니다.
이러한 문제를 회피하기 위해서 createSelector를 사용하면 애플리케이션을 최적화할 수 있습니다.
const shopItemsSelector = state => state.shop.items
const taxPercentSelector = state => state.shop.taxPercent
// subtotal 값을 메모이제이션 합니다.
const subtotalSelector = createSelector(
shopItemsSelector,
items => items.reduce((subtotal, item) => subtotal + item.value, 0)
)
// 메모이제이션된 subtotal 값과 taxPercentSelector를 합성하여
// 새로운 값을 메모이제이션 합니다.
const taxSelector = createSelector(
subtotalSelector,
taxPercentSelector,
(subtotal, taxPercent) => subtotal * (taxPercent / 100)
)
const totalSelector = createSelector(
subtotalSelector,
taxSelector,
(subtotal, tax) => ({ total: subtotal + tax })
)
const exampleState = {
shop: {
taxPercent: 8,
items: [
{ name: 'apple', value: 1.20 },
{ name: 'orange', value: 0.95 },
]
}
}
console.log(subtotalSelector(exampleState)) // 2.15
console.log(taxSelector(exampleState)) // 0.172
console.log(totalSelector(exampleState)) // { total: 2.322 }
7. createEntityAdapter
정규화된 상태 구조, 즉 중복을 취소화하기 위해서 데이터가 구조화되고, 일관성이 보장된 구조에서 효율적인 CRUD를 수행하기 위해 미리 빌드된 리듀서 및 셀렉터를 생성하는 함수입니다. CRUD 함수를 따로 제공하고 있습니다.
이번 소개에서는 자세히 다루지는 않았지만 다음 공식 예제에서 전체적인 사용법을 다루고 있어서 첨부해 보았습니다.
import {
createEntityAdapter,
createSlice,
configureStore,
} from '@reduxjs/toolkit'
// Since we don't provide `selectId`, it defaults to assuming `entity.id` is the right field
const booksAdapter = createEntityAdapter({
// Keep the "all IDs" array sorted based on book titles
sortComparer: (a, b) => a.title.localeCompare(b.title),
})
const booksSlice = createSlice({
name: 'books',
initialState: booksAdapter.getInitialState({
loading: 'idle',
}),
reducers: {
// Can pass adapter functions directly as case reducers. Because we're passing this
// as a value, `createSlice` will auto-generate the `bookAdded` action type / creator
bookAdded: booksAdapter.addOne,
booksLoading(state, action) {
if (state.loading === 'idle') {
state.loading = 'pending'
}
},
booksReceived(state, action) {
if (state.loading === 'pending') {
// Or, call them as "mutating" helpers in a case reducer
booksAdapter.setAll(state, action.payload)
state.loading = 'idle'
}
},
bookUpdated: booksAdapter.updateOne,
},
})
const {
bookAdded,
booksLoading,
booksReceived,
bookUpdated,
} = booksSlice.actions
const store = configureStore({
reducer: {
books: booksSlice.reducer,
},
})
// Check the initial state:
console.log(store.getState().books)
// {ids: [], entities: {}, loading: 'idle' }
const booksSelectors = booksAdapter.getSelectors((state) => state.books)
store.dispatch(bookAdded({ id: 'a', title: 'First' }))
console.log(store.getState().books)
// {ids: ["a"], entities: {a: {id: "a", title: "First"}}, loading: 'idle' }
store.dispatch(bookUpdated({ id: 'a', changes: { title: 'First (altered)' } }))
store.dispatch(booksLoading())
console.log(store.getState().books)
// {ids: ["a"], entities: {a: {id: "a", title: "First (altered)"}}, loading: 'pending' }
store.dispatch(
booksReceived([
{ id: 'b', title: 'Book 3' },
{ id: 'c', title: 'Book 2' },
])
)
console.log(booksSelectors.selectIds(store.getState()))
// "a" was removed due to the `setAll()` call
// Since they're sorted by title, "Book 2" comes before "Book 3"
// ["c", "b"]
console.log(booksSelectors.selectAll(store.getState()))
// All book entries in sorted order
// [{id: "c", title: "Book 2"}, {id: "b", title: "Book 3"}]
데이터 패칭과 상태 관리의 분리
리덕스 생태계에 데이터 패칭 및 캐싱을 위한 라이브러리가 등장하기 전까지는 리듀서를 사용해서 데이터 패칭을 직접 관리하는 경우가 일반적이었습니다. 공식 문서에서도 어떻게 패칭 로직을 작성해야 하는지 직접 가이드를 했었고 지금도 그러한 형태로 리덕스를 사용하기도 합니다.
그러나 사용자들은 데이터 패칭 로직을 리덕스에서 직접 관리하는 것에 대해 의문을 가지게 되었고, 한편으로는 RTK가 보일러플레이트 코드를 최적화하긴 했지만 로직을 일일이 작성하는 방법은 여전히 피로도를 높였던 것으로 생각됩니다.
그러한 시점에 리액트 커뮤니티에서는 React Query, SWR과 같은 훅 기반의 데이터 패칭 라이브러리를 사용하기 시작하면서 리덕스를 통한 앱의 전역 상태 관리와 데이터 패칭의 역할이 서로 구분된 것 같습니다. 다행히 리덕스 개발팀에서도 커뮤니티의 이러한 온도에 맞추어 RTK에 데이터 패칭과 캐싱을 위한 솔루션인 RTK Query를 선보이면서 현재는 데이터 패칭에서는 이를 사용하도록 안내하고 있습니다.
소개에 따르면 RTK Query를 사용하는 데는 리덕스와 RTK에 대한 지식은 별도로 필요하지 않다고 합니다. 다만 전역 스토어 관리 기능, 예를 들어서 개발자 도구 사용 방법 같은 것은 확인해둘 필요가 있다고 하는데요. RTK Query와 연동되어 사용자의 요청과 캐시 행위에 대한 타임라인을 여행하거나 리플레이를 할 수 있다고 합니다.
RTK Query는 RTK 1.6 버전부터 패키지에 함께 포함되어 릴리즈 되었습니다. 예제와 API를 살펴보니 기존 경험처럼 데이터 패칭의 로딩과 에러 상태를 나타내면서도 동시에 데이터 캐싱을 지원하고 있음을 확인할 수 있었습니다. 앞으로 어떤 사용성을 보여줄지 많은 기대가 됩니다.
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import { Pokemon } from './types'
// Define a service using a base URL and expected endpoints
export const pokemonApi = createApi({
reducerPath: 'pokemonApi',
baseQuery: fetchBaseQuery({ baseUrl: 'https://pokeapi.co/api/v2/' }),
endpoints: (builder) => ({
getPokemonByName: builder.query<Pokemon, string>({
query: (name) => `pokemon/${name}`,
}),
}),
})
// Export hooks for usage in functional components, which are
// auto-generated based on the defined endpoints
export const { useGetPokemonByNameQuery } = pokemonApi
import * as React from 'react'
import { useGetPokemonByNameQuery } from './services/pokemon'
export default function App() {
// Using a query hook automatically fetches data and returns query values
const { data, error, isLoading } = useGetPokemonByNameQuery('bulbasaur')
// Individual hooks are also accessible under the generated endpoints:
// const { data, error, isLoading } = pokemonApi.endpoints.getPokemonByName.useQuery('bulbasaur')
// render UI based on data and loading state
}
import { configureStore } from '@reduxjs/toolkit'
// Or from '@reduxjs/toolkit/query/react'
import { setupListeners } from '@reduxjs/toolkit/query'
import { pokemonApi } from './services/pokemon'
export const store = configureStore({
reducer: {
// Add the generated reducer as a specific top-level slice
[pokemonApi.reducerPath]: pokemonApi.reducer,
},
// Adding the api middleware enables caching, invalidation, polling,
// and other useful features of `rtk-query`.
middleware: (getDefaultMiddleware) =>
getDefaultMiddleware().concat(pokemonApi.middleware),
})
// optional, but required for refetchOnFocus/refetchOnReconnect behaviors
// see `setupListeners` docs - takes an optional callback as the 2nd arg for customization
setupListeners(store.dispatch)마무리
이번에 리덕스의 주요 API 및 지원 사항에 대해서 살펴보면서 RTK에 대해서 조금 더 잘 이해하게 되었습니다. 물론 아직 더 여행할 지역이 남아있지만 제가 RTK에 대해 가지고 있던 생각을 조금은 깨주었다는 점에서 의미가 있었던 것 같습니다.
예전에는 리덕스를 단순히 앱 상태 관리 도구 정도로만 가볍게 생각했었는데, 어떤 문제를 해결하기 위해 고안되었는지 한번 더 생각해 볼 수 있어서 좋았습니다. 그리고 RTK가 기존 리덕스가 가진 문제점을 개선해 나가는 과정 속에서 더 좋은 개발 경험을 제공하기 위해 계속 변화하고 성장해 나가고 있다는 점도 확인할 수 있었습니다.
물론 최근 개발 생태계는 여러 가지 상태 관리 라이브러리가 대안으로 등장하면서 더 쉽고, 가볍게 애플리케이션의 전역 상태 관리를 달성할 수 있는 방법이 많아졌습니다. 그렇지만 웹 애플리케이션을 구축할 때 리덕스를 상태 관리의 대안에서 제외할 정도로 뒤쳐지고 있다는 생각은 들지 않았습니다. 오히려 리덕스를 잘 이해하고 필요 적절하게 사용한다면 잘 설계된 API를 바탕으로 좋은 제품을 만드는데 많은 도움이 될 것이라고 생각합니다.
위 내용을 짧게 정리해 보면 다음과 같습니다.
-
리덕스는 데이터를 단방향으로 흐르게 하여 결과를 예측 가능하게 하고 디버깅을 쉽게 만든다.
-
RTK는 기존 리덕스의 문제를 개선하고, 리덕스 로직을 작성하는 표준을 제안한다.
- 스토어 구성은 configureStore를 사용하자.
- 리덕스 로직을 작성할 때는 덕-패턴(ducks pattern) 형태로 작성을 돕는 createSlice를 사용하자.
- 비동기 로직은 createAsyncThunk를 사용해서 작성하자.
- 타입 스크립트를 지원하는 빌더 콜백(builder callback) 표기법을 사용하자.
- 프로미스 생명 주기를 따르는 액션 타입으로 비동기 로직을 관리해 보자.
- 데이터 패칭과 캐싱은 RTK Query를 사용해 보자.
